MobTech自研FM模型,推动行业重塑,探索数据智能世界
我们正处于大数据和数字化转型的时代。数据无处不在,运用数据驱动的思想和策略在实践中逐渐成为共识,数据的价值已在科学研究和工商业的不同领域得到充分展现。然而,如果无法从数据中提取出知识和信息并加以有效利用,数据本身并不能驱动和引领数字化转型取得成功。如何让数据发挥它最大的价值?“数据智能”(Data Intelligence) 应运而生。

然而,技术的不断发展终究要服务于现实生活,海量数据背后那些未被挖掘的价值,需要企业不断挖掘并乐于分享才能真正促进行业转型,才能赋能各种应用场景。日前,由MobTech MobAI团队基于Spark自研的因子分解机(Factorization Machine,简称FM)模型已得到Spark merge,Spark使用者只要更新Spark后,即可使用该模型。

Apache Spark是一个互联网行业普遍使用的开源大数据分布式编程框架,借助Catalyst、新的混排方法、新的网络模块等,获得了超越MapReduce框架的性能,也提供了丰富的API接口。截至2015年年底,Spark是所有大数据项目中最活跃的开源项目。如今,许多公司使用Spark,包括亚马逊、Autodesk、Groupon、TripAdvisor,百度、阿里巴巴和腾讯、微软等国内外一流互联网公司都在使用。
而FM模型自从2010年被提出后,由于易于整合交叉特征、能够有效解决高维数据特征组合的稀疏问题且具有较高的预测精度和计算效率,在推荐系统及广告CTR预估等领域得到了大规模使用,国内很多大厂(如美团、头条等)都用它来做推荐及CTR预估。在数据稀疏的情况(如CTR预测)下,FM模型展现出非常高的预测质量,被提出后迅速成为学术界和行业研究和应用的热点。
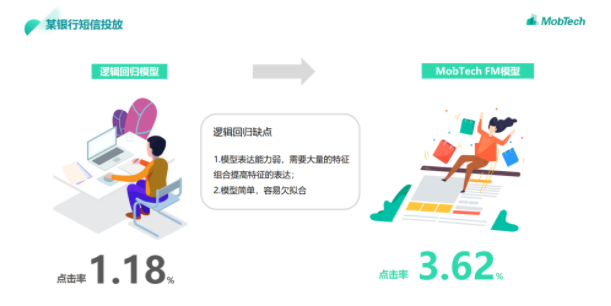
比如在某银行短信投放的项目中,一开始使用对于计算广告等有天然优势的逻辑回归模型,点击率为1.18%。但是,逻辑回归虽然适合用来学习需要大规模训练的样本和特征,同时也有着不容忽视的缺点:1.模型表达能力弱,需要大量的特征组合提高特征的表达;2.模型简单,容易欠拟合。所以在评估后,MobTech选择了使用FM模型,成功帮助用户的点击率增长至3.62%,带来了更多转化。
作为全球领先的数据智能科技平台,MobTech结合大规模数据处理、数据挖掘、机器学习、可视化等多种技术,从数据中提炼、发掘、获取有揭示性和可操作性的信息,为企业和品牌在基于数据制定决策或执行任务时提供有效的智能支持。自研FM模型并得到Spark merge是MobTech助力各企业探求数据空间中未知世界,在不同领域里寻找巨大机会的见证,也彰显了MobTech在推动行业重塑商业分析和商业智能领域的决心。

新一轮技术革命带来的商业演进把我们带进“ABC”时代,即人工智能(AI)、大数据(Big Data)和云计算(Cloud Computing)。而根据Gartner的调研,一种新的
“增强分析”的分析模式正在颠覆旧有方式,预计在几年内将成为商业智能系统采购的主导驱动力。这种“增强分析”模式正是由数据智能技术赋能,提供了自然语言查询和叙述、增强的数据准备、自动的高级分析、基于可视化的数据探索等多种核心能力。

未来,MobTech将会潜心数据智能研究,让产品更加契合当今大数据时代各领域、各行业从数据中挖掘、实现价值,进行数字化转型的迫切需要。并不断将成果与众企业分享,一同实现数据智能在更多领域的落地和发展,不断挑战新应用和新场景,进一步激发和驱动数字智能研究保持强劲的发展势头,迈向更高的层次。
