万字详解:腾讯如何自研大规模知识图谱 Topbase
将门创投导读
Topbase 是由 TEG-AI 平台部构建并维护的一个专注于通用领域知识图谱,其涉及 226 种概念类型,共计 1 亿多实体,三元组数量达 22 亿。在技术上,Topbase 支持图谱的自动构建和数据的及时更新入库。此外,Topbase 还连续两次获得过知识图谱领域顶级赛事 KBP 的大奖。
目前,Topbase 主要应用在微信搜一搜,信息流推荐以及智能问答产品。本文主要梳理 Topbase 构建过程中的技术经验,从0到1地介绍了构建过程中的重难点问题以及相应的解决方案,希望对图谱建设者有一定的借鉴意义。
一、简介
知识图谱( Knowledge Graph)以结构化的形式描述客观世界中概念、实体及其关系,便于计算机更好的管理、计算和理解互联网海量信息。通常结构化的知识是以图形式进行表示,图的节点表示语义符号(实体,概念),图的边表示符号之间的语义关系(如图 1 所示),此外每个实体还有一些非实体级别的边(通常称之为属性),如:人物的出生日期,主要成就等。
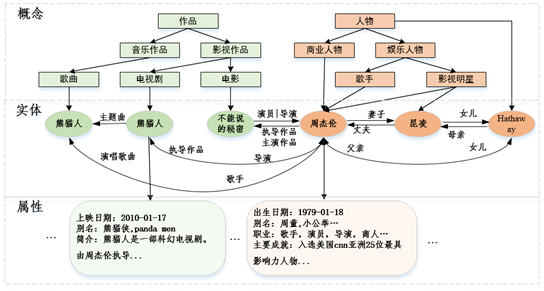
图1 知识图谱的示列
TEG-AI 平台部的 Topbase 是专注于通用领域知识。数据层面,TopBase 覆盖 51 个领域的知识,涉及 226 种概念类型,共计 1 亿多个实体,三元组数量达 22 亿多。技术层面,Topbase 已完成图谱自动构建和更新的整套流程,支持重点网站的监控,数据的及时更新入库,同时具备非结构化数据的抽取能力。此外,Topbase 还连续两次获得过知识图谱领域顶级赛事 KBP 的大奖,分别是 2017 年 KBP 实体链接的双项冠军,以及 2019 年 KBP 大赛第二名。在应用层面,Topbase 主要服务于微信搜一搜,信息流推荐以及智能问答产品。本文主要梳理 Topbase 构建过程中的重要技术点,介绍如何从 0 到 1 构建一个知识图谱,内容较长,建议先收藏。
二、知识图谱技术架构
TopBase 的技术框架如图 2 所示,主要包括知识图谱体系构建,数据生产流程,运维监控系统以及存储查询系统。其中知识图谱体系是知识图谱的骨架,决定了我们采用什么样的方式来组织和表达知识,数据生产流程是知识图谱构建的核心内容,主要包括下载平台,抽取平台,知识规整模块,知识融合模块,知识推理模块,实体重要度计算模块等。Topbase 应用层涉及知识问答(基于 topbase 的 KB-QA 准确率超 90%),实体链接(2017 图谱顶级赛事 KBP 双料冠军),相关实体推荐等。
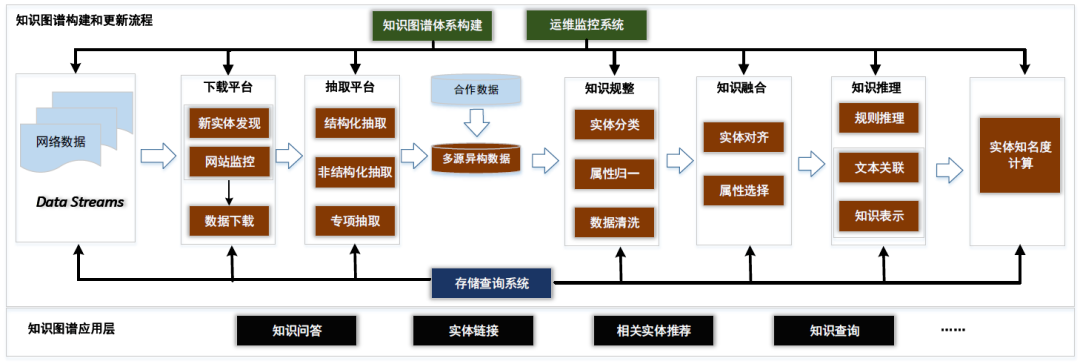
图2 知识图谱Topbase的技术框架
1. 下载平台-知识更新:下载平台是知识图谱获取源数据平台,其主要任务包括新实体的发现和新实体信息的下载。
2. 抽取平台-知识抽取:下载平台只负责爬取到网页的源代码内容,抽取平台需要从这些源码内容中生成结构化的知识,供后续流程进一步处理。
3. 知识规整:通过抽取平台以及合作伙伴提供的数据我们可以得到大量的多源异构数据。为了方便对多源数据进行融合,知识规整环节需要对数据进行规整处理,将各路数据映射到我们的知识体系中。
4. 知识融合:知识融合是对不同来源,不同结构的数据进行融合,其主要包括实体对齐和属性融合。
5. 知识推理:由于处理数据的不完备性,上述流程构建的知识图谱会存在知识缺失现象(实体缺失,属性缺失)。知识推理目的是利用已有的知识图谱数据去推理缺失的知识,从而将这些知识补全。此外,由于已获取的数据中可能存在噪声,所以知识推理还可以用于已有知识的噪声检测,净化图谱数据。
6. 实体知名度计算:最后,我们需要对每一个实体计算一个重要性分数,这样有助于更好的使用图谱数据。比如:名字叫李娜的人物有网球运动员,歌手,作家等,如果用户想通过图谱查询“李娜是谁”那么图谱应该返回最知名的李娜(网球运动员)。
三、知识体系构建
知识体系的构建是指采用什么样的方式来组织和表达知识,核心是构建一个本体(或 schema)对目标知识进行描述。在这个本体中需要定义:1)知识的类别体系(如:图 1 中的人物类,娱乐人物,歌手等);2)各类别体系下实体间所具有的关系和实体自身所具有的属性;3)不同关系或者属性的定义域,值域等约束信息(如:出生日期的属性值是 Date 类型,身高属性值应该是 Float 类型,简介应该是 String 类型等)。我们构建 Topbase 知识体系主要是以人工构建和自动挖掘的方式相结合,同时我们还大量借鉴现有的第三方知识体系或与之相关的资源,如:Schema.org、Dbpedia、大词林、百科(搜狗)等。知识体系构建的具体做法:
1. 首先是定义概念类别体系:
概念类别体系如图 1 的概念层所示,我们将知识图谱要表达的知识按照层级结构的概念进行组织。在构建概念类别体系时,必须保证上层类别所表示的概念完全包含下层类别表示的概念,如娱乐人物是人物类的下层类别,那么所有的娱乐人物都是人物。在设计概念类别体系时,我们主要是参考 schema.org、DBpedia 等已有知识资源人工确定顶层的概念体系。同时,我们要保证概念类别体系的鲁棒性,便于维护和扩展,适应新的需求。除了人工精心维护设计的顶层概念类别体系,我们还设计了一套上下位关系挖掘系统,用于自动化构建大量的细粒度概念(或称之为上位词),如:《不能说的秘密》还具有细粒度的概念:“青春校园爱情电影”,“穿越电影”。
2. 其次是定义关系和属性:
定义了概念类别体系之后我们还需要为每一个类别定义关系和属性。关系用于描述不同实体间的联系,如:夫妻关系(连接两个人物实体),作品关系(连接人物和作品实体)等;属性用于描述实体的内在特征,如人物类实体的出生日期,职业等。关系和属性的定义需要受概念类别体系的约束,下层需要继承上层的关系属性,例如所有歌手类实体应该都具有人物类的关系和属性。我们采用半自动的方式生成每个概念类别体系下的关系属性。我们通过获取百科 Infobox 信息,然后将实体分类到概念类别体系下,再针对各类别下的实体关系属性进行统计分析并人工审核之后确定该概念类别的关系属性。关系属性的定义也是一个不断完善积累的过程。
3. 定义约束:
定义关系属性的约束信息可以保证数据的一致性,避免出现异常值,比如:年龄必须是 Int 类型且唯一(单值),演员作品的值是 String 类型且是多值。
四、下载平台-知识更新
知识更新主要包括两方面内容,一个是新出现的热门实体,需要被及时发现和下载其信息,另一个是关系属性变化的情况需要对其值进行替换或者补充,如明星的婚姻恋爱关系等。
知识更新的具体流程如下图所示:
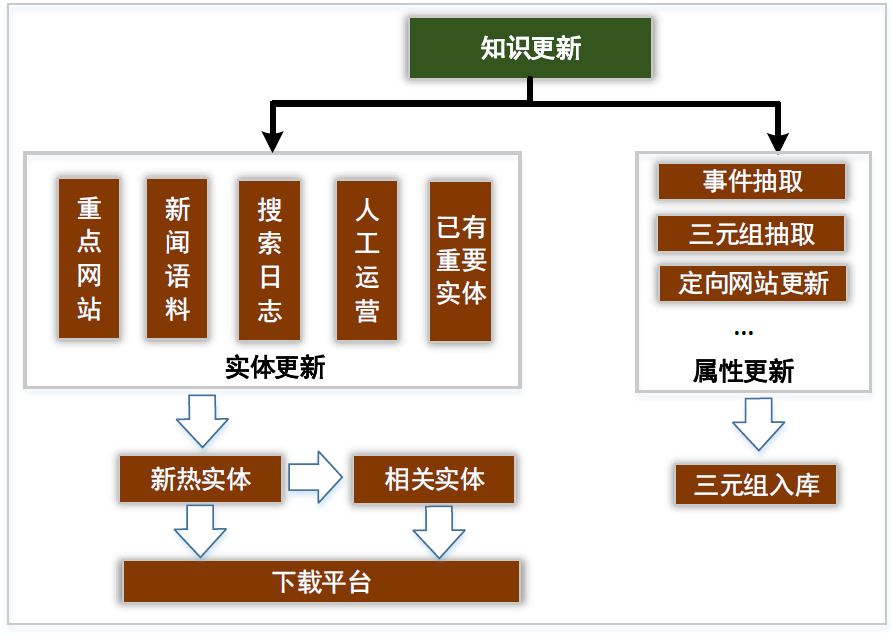
图3 Topbase知识更新流程图
1. 针对热门实体信息的更新策略主要有:
从各大站点主页更新,定时遍历重点网站种子页,采用广搜的方式层层下载实体页面信息;
从新闻语料中更新,基于新闻正文文本中挖掘新实体,然后拼接实体名称生成百科 URL 下载;
从搜索 query log 中更新,通过挖掘 querylog 中的实体,然后拼接实体生成百科 URL 下载。基于 querylog 的实体挖掘算法主要是基于实体模板库和我们的 QQSEG-NER 工具;
从知识图谱已有数据中更新,知识图谱已有的重要度高的实体定期重新下载;
从人工运营中更新,将人工(业务)获得的 URL 送入下载平台获取实体信息;
从相关实体中更新,如果某个热门实体信息变更,则其相关实体信息也有可能变更,所以需要获得热门实体的相关实体,进行相应更新。

表 1 最近 7 日下载数据统计情况
2. 针对其他关系属性易变的情况,我们针对某些重要关系属性进行专项更新。如明星等知名人物的婚姻感情关系我们主要通过事件挖掘的方式及时更新,如:离婚事件会触发已有关系“妻子”“丈夫”变化为“前妻”“前夫”,恋爱事件会触发“男友”“女友”关系等。此外,基于非结构化抽取平台获得的三元组信息也有助于更新实体的关系属性。
五、抽取平台 - 知识抽取
Topbase 的抽取平台主要包括结构化抽取,非结构化抽取和专项抽取。其中结构化抽取主要负责抽取网页编辑者整理好的规则化知识,其准确率高,可以直接入库。由于结构化知识的局限性,大量的知识信息蕴含在纯文本内容中,因此非结构化抽取主要是从纯文本数据中挖掘知识弥补结构化抽取信息的不足。此外,某些重要的知识信息需要额外的设计专项策略进行抽取,比如:事件信息,上位词信息(概念),描述信息,别名信息等。这些重要的知识抽取我们统称专项抽取,针对不同专项的特点设计不同的抽取模块。
1. 结构化抽取平台
许多网站提供了大量的结构化数据,如(图 4 左)所示的百科 Infobox 信息。这种结构化知识很容易转化为三元组,如:“<姚明,妻子,叶莉>”。针对结构化数据的抽取,我们设计了基于 Xpath 解析的抽取平台,如(图 4 右)所示,我们只需要定义好抽取网页的种子页面如:baike.com,然后从网页源码中拷贝 Infobox 中属性的 xpath 路径即可实现结构化知识的自动抽取,入库。通过结构化抽取平台生成的数据准确率高,因此无需人工参与审核即可直接入库,它是知识图谱的重要数据来源。

图4 Topbase结构化抽取平台的xpath配置界面
2. 非结构化抽取平台
由于大量的知识是蕴含在纯文本中,为了弥补结构化抽取信息的不足,我们设计了非结构化抽取平台。非结构化抽取流程如图 5 所示:
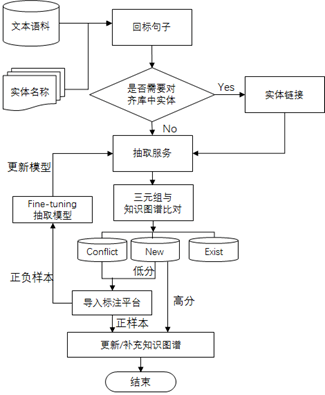
图5 Topbase非结构化抽取平台的技术框架
1 2 3 4 下一页>
