算法偏见:被AI算法包围的时代
Ai芯天下前言:人工智能在各个领域似乎被吹捧为在各种应用领域实现自动化决策的“圣杯”,被认为可以做得比人类更好或更快,但事实上人工智能面临了一个大挑战就是算法偏见。

人工智能是否全能
机器是没有情感的,只能根据输入的数据来进行学习,然后按照既定设计完成相应功能,AI需要大量数据来运作,但通常没有合适的数据基础设施来支持AI学习,最终AI的数据基础不够,无法真正有效地完成功能,更多的是从事一些指令性的工作,就像生产线上的机器手一样,都是提前输入指令,由机器手臂按照固定的步骤操作完成。
人类对大脑还是未知的,我们并不清楚大脑是如何进行学习和工作的,AI其实就是模仿人脑去思考和工作,但我们对大脑的机理并不清楚,就无法让AI完全模拟人脑,无法完全代替人脑去学习和工作,AI更多时候是根据输入的数据,将见到的问题录入与已输入的数据进行对比,有重叠度比较高的就认为匹配成功,执行相应的预设动作,当已有的样本库里没有匹配到,那AI也不知道该怎么办。在很多人类活动中,掺杂着很多复杂的社会问题,比如说种族歧视、国家竞争、疾病传染等问题,AI显然还意识不到这些问题的存在,这些数据不好采集和录入,AI算法也没有考虑这些社会因素。

算法的偏见来自哪里
工程师很少刻意将偏见教给算法,那偏见究竟从何而来,这个问题与人工智能背后的核心技术—机器学习休戚相关。机器学习过程可化约为如下步骤,而为算法注入偏见的主要有三个环节—数据集构建、目标制定与特征选取(工程师)、数据标注(标注者)。
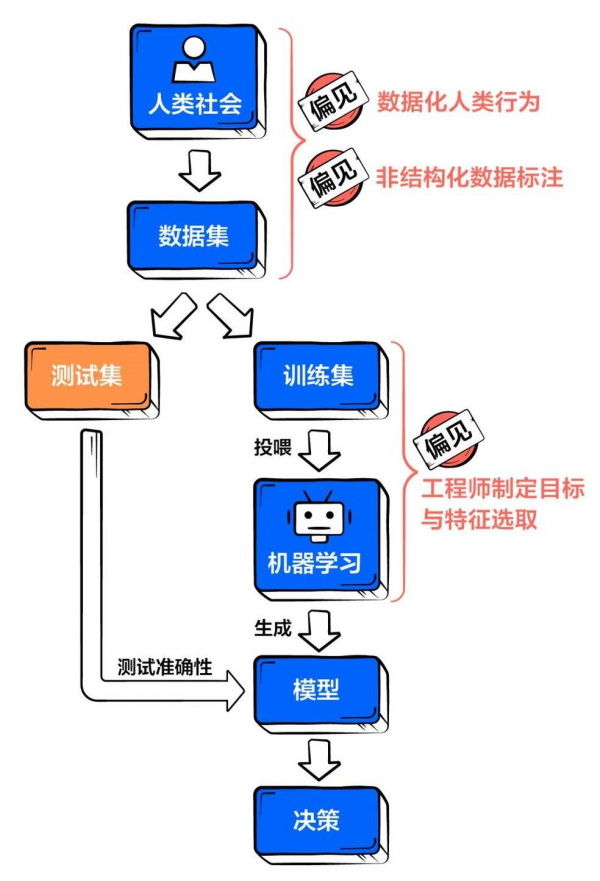
工程师是规则制定者,算法工程师从头到尾参与了整个系统,包括:机器学习的目标设定、采用哪种模型、选取什么特征(数据标签)、数据的预处理等。不恰当的目标设定,可能从一开始就引入了偏见,比如意图通过面相来识别罪犯;不过,更典型的个人偏见代入,出现在数据特征的选取环节。
数据标签就是一堆帮助算法达成目标的判定因素。算法就好像一只嗅探犬,当工程师向它展示特定东西的气味后,它才能够更加精准地找到目标。因此工程师会在数据集中设置标签,来决定算法要学习该数据集内部的哪些内容、生成怎样的模型。
对于一些非结构化的数据集如大量描述性文字、图片、视频等,算法无法对其进行直接分析。这时就需要人工为数据进行标注,提炼出结构化的维度,用于训练算法。举一个很简单的例子,有时Google Photos会请你帮助判断一张图片是否是猫,这时你就参与了这张图片的打标环节。
当打标者面对的是“猫或狗”的提问时,最坏结果不过是答错;但如果面对的是“美或丑”的拷问,偏见就产生了。作为数据的加工人员,打标者时常会被要求做一些主观价值判断,这又成为偏见的一大来源。
打标过程正是将个人偏见转移到数据中,被算法吸纳,从而生成了带有偏见的模型。现如今,人工打标服务已成为一种典型商业模式,许多科技公司都将其海量的数据外包进行打标。这意味着,算法偏见正通过一种“隐形化”、“合法化”的过程,被流传和放大。

人工智能偏见的分类
偏见不是以一种形式出现的,而是有各种类型的。这包括交互偏见、潜意识偏见、选择偏见、数据驱动的偏见和确认偏见。
交互偏见:是指用户由于自己与算法的交互方式而使算法产生的偏见。当机器被设置向周围环境学习时,它们不能决定要保留或者丢弃哪些数据,什么是对的,什么是错的。相反,它们只能使用提供给它们的数据——不论是好的、坏的,还是丑的,并在此基础上做出决策。机器人Tay便是这类偏见的一个例子,它是受到一个网络聊天社区的影响而变得偏种族主义。
潜意识偏见:是指算法错误地把观念与种族和性别等因素联系起来。例如,当搜索一名医生的图像时,人工智能会把男性医生的图像呈现给一名女性,或者在搜索护士时反过来操作。
选择偏见:是指用于训练算法的数据被倾向性地用于表示一个群体或者分组,从而使该算法对这些群体有利,而代价是牺牲其他群体。以招聘为例,如果人工智能被训练成只识别男性的简历,那么女性求职者在申请过程中就很难成功。
数据驱动的偏见:是指用来训练算法的原始数据已经存在偏见了。机器就像孩子一样:他们不会质疑所给出的数据,而只是寻找其中的模式。如果数据在一开始就被曲解,那么其输出的结果也将反映出这一点。
确认偏见:这类似于数据驱动的偏见,偏向于那些先入为主的信息。它影响人们怎样收集信息,以及人们怎样解读信息。例如,如果自己觉得8月份出生的人比其他时候出生的更富有创造性,那就会偏向于寻找强化这种想法的数据。

Applause推出偏见解决方案
应用测试公司Applause推出了新的人工智能解决方案,同时提供AI训练所需的庞大数据。
Applause已经为其应用程序测试解决方案建立了庞大的全球测试社区,该解决方案受到谷歌、Uber、PayPal等品牌的信任。
具体地说,Applause的新解决方案跨越五种独特的AI活动类型:
①语音:源发声以训练支持语音的设备,并对这些设备进行测试,以确保它们能够准确地理解和响应;
②OCR:提供文档和对应的文本来训练识别文本的算法,并比较打印文档和识别文本的准确性;
③图像识别:交付预定义对象和位置的照片,并确保正确识别图片和识别对象;
④生物识别:获取生物特征输入,如人脸和指纹,并测试这些输入是否会产生易于使用且实际有效的体验;
⑤聊天机器人:给出样本问题和不同的意图让聊天机器人回答,并与聊天机器人互动,以确保它们能像人类那样准确地理解和响应。

结尾:
但回过头来,技术不过是社会与人心的一面镜子。某种程度上,算法偏见就像在这个我们认为进步、美好的当下,重新呈递灰暗角落的真相并敲响警钟。因此,当谈及算法偏见的应对时,一部分努力便是要回归于人。可幸的是,即便是技术层面的自律与治理尝试,也能极大地降低偏见程度、避免偏见大幅扩张。
