谷歌公布新研究BiT探索大规模数据如何影响预训练模型性能
将门创投计算机视觉的研究人员在利用现代深度神经网络解决问题时常常会无奈地感受到其对数据的庞大需求,当前很多先进的CNN模型都需要在像OpenImages和Places这样包含上百万张标注图片的数据集上进行训练。然而对于很多领域的应用来说,收集如此海量的数据其时间和经济成本几乎是常人无法承受的。
为了解决计算机视觉领域缺乏数据的问题,人们提出了预训练模型的迁移学习方法,通过在大规模的通用数据上进行预训练而后再复用到目标任务上,用少量数据对模型进行适应性调优。
尽管预训练模型在实践中十分有效,但它仍不足以迅速地在新场景下掌握概念并进行深入的理解,在工程实践中还面临着一系列问题。由于大规模的预训练使得BERT和T5等方法在语言领域取得了巨大的进展,研究人员坚信大规模的预训练可以有效提升计算机视觉任务的性能。
为了充分研究大规模预训练和迁移学习的内在机理和规律,来自谷歌的研究人员发表了一篇名为BigTransfer的论文,探索了如何有效利用超常规的图像数据规模来对模型进行预训练,并对训练过程进行的系统深入的研究。研究人员发现,随着预训练数据的增加,恰当地选择归一化层、拓展模型架构的容量对于预训练的结果至关重要。
在有效的调整和训练后,这种方法展示了多个领域的视觉任务上展现了前所未有的适应性和先进的性能,包括小样本是识别任务和最近提出的真实数据基准ObjectNet上都取得了非常优异的成绩。

预训练
为了探索数据规模对于模型性能的影响,研究人员重新审视了目前常用的预训练配置(包括激活函数和权重的归一化,模型的宽度和深度以及训练策略),同时利用了三个不同规模的数据集包括:ILSVRC-2012 (1000类128万张图像), ImageNet-21k (2.1万类的1400万张图像) 和 JFT (1.8万类的三亿张图像),更重要的是基于这些数据研究人员可以探索先前未曾涉足的数据规模。
研究人员首先探索了数据集规模和模型容量间的关系,选择了ResNet不同的变体进行训练。从标准大小的“R50x1”到x4倍宽度的,再到更深度152层“R152x4”,都在上面的数据集上进行了训练。随后研究人员获得了关键的发现,如果想要充分利用大数据的优势,就必须同时增加模型的容量。
下图左半部分箭头开头的扩大显示了这一结论,数据量增大的情况下容量更大的模型性能增加更大,而容量小的模型反而会有一定程度地下降。
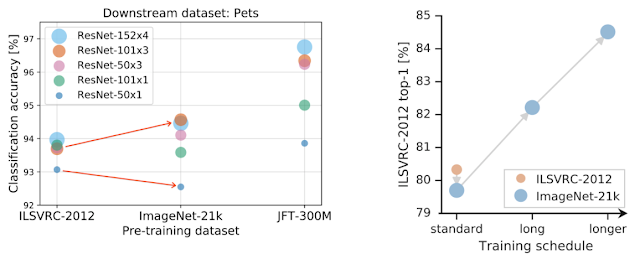
左半部分显示了随着数据量的增加需要扩充模型的容量,红色箭头的扩大意味着小模型架构在大数据集下变差,而大模型架构则得到改善。右图显示了在大数据集下的预训练并不一定改善,而是需要提高训练时间和计算开销来充分利用大数据的优势。
其次,训练的时间对模型性能也具有关键的作用。如果在大规模数据集上没有进行充分地训练调整计算开销的话,性能会有显著下降(上图中有半部分红色点到蓝色点下降),但通过适当地调整模型训练时间就能得到显著的性能提升。
在探索的过程中研究人员还发现了适当的归一化可以有效提升性能。下图中展示了将批归一化BN替换为组归一化GN后可以有效提升预训练模型在大规模数据集上的性能,其原因主要来源于两个方面。
首先在从预训练迁移到目标任务时BN的状态需要进行调整,而GN却是无状态的从而避开了需要调整的困难;其次,BN利用每一批次的统计信息,但这对于每个设备上的小批量来说这种统计信息会变得不可靠,而对于大型模型来说多设备上的训练不可避免。由于GN不需要计算每个批次的统计信息,又一次成功避开了这一问题。

图中展示了预训练策略,在标准ResNet基础上增加宽度和深度,将BN替换为GN和权重标准化,并在非常大规模数据集上训练更长的时间。
1 2 下一页>
