从2022新公开的特斯拉机器人Dojo芯片架构解析到存算一体
半导体产业纵横在Hot Chips 34(2022)大会上,Emil Talpes公开了特斯拉Dojo处理器的关键细节。
Emil Talpes 本人在 AMD 工作了近 17 年,曾研究各种 Opteron 处理器以及 “K12”Arm服务器芯片。

D1处理器由台积电制造,采用7纳米制造工艺,拥有500亿个晶体管,芯片面积为645mm?,小于英伟达的A100(826 mm?)和AMD Arcturus(750 mm?)。要知道,这个D1处理器可是特斯拉人形机器人的核心,意义重大。
千芯科技陈巍博士就D1架构、D1训练模块、D1训练网格以及训练矩阵整体架构做了解析。
D1处理器架构
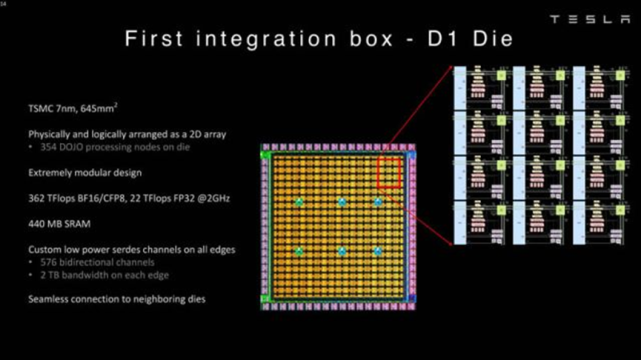
D1处理器结构
每个D1处理器由 18 x 20 的D1核心构成。每个D1处理器中有354个D1核心可用。估计是出于良率和处理器核心稳定考虑,D1处理器由台积电制造,采用7nm制造工艺,拥有500亿个晶体管,芯片面积为645mm?。
这个尺寸小于英伟达的A100(826 mm?)和AMD Arcturus(750 mm?)。但是每个核心都是一个完整的带矩阵计算能力的CPU,其计算灵活性是远超众核架构的GPU的,这也会带来极高的成本。这个架构有点类似于SambaNova。
D1芯片运行在2GHz,拥有巨大的440MB SRAM,是存算一体架构(近存计算)。

D1核心的架构
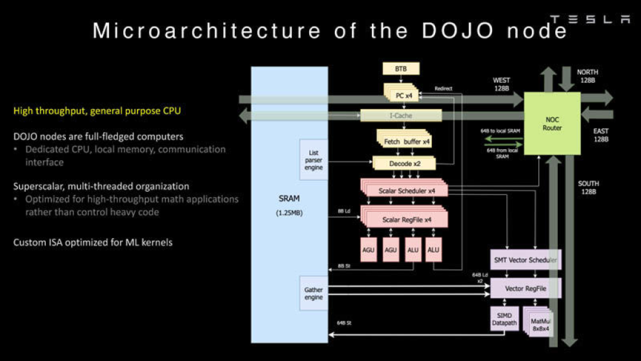
D1核心结构
从18x20阵列中每个D1核心的结构上看,每个D1核心是带有向量计算/矩阵计算能力的处理器,具有完整的取指、译码、执行部件。处理器运行在2GHz,具有4个8x8x4矩阵乘法计算单元。


D1处理器指令集
据称D1以RISC-V架构ISA为基础进行扩展。
D1核心具备FP32和FP16这两个标准的计算格式,同时还具备更适合Inference的BFP16格式。为了达到混合精度计算提升性能的目的,D1还采用了用于较低精度和更高吞吐量的 8 位 CFP8 格式。Dojo 编译器可以在尾数精度附近滑动,以涵盖更广泛的范围和精度。在任何给定时间,最多可以使用 16 种不同的矢量格式,灵活提升算力。
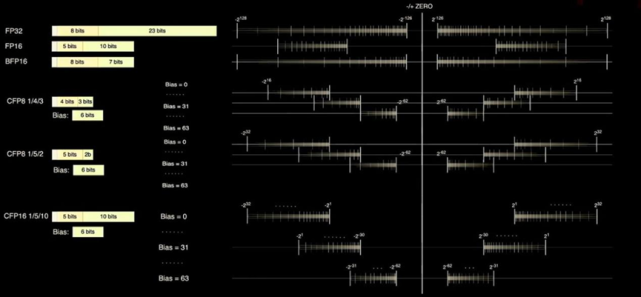
D1处理器的数据格式
D1训练块架构

D1训练模块展开图
在D1训练模块方面,每个D1训练模块由5x5的 D1芯片阵列排布而成,以二维Mesh结构互连。片上跨内核SRAM达到惊人的11GB,这也算是一个非常典型的近存计算架构了。当然耗电量也达到了15kW的惊人指标。能效比为0.6TFLOPS/W@BF16/CFP8。对于CPU架构来说,这一能效比非常不错。显然存算一体架构带来的优势非常大。外部32GB共享HBM内存。(HBM2e或HBM3)
每个训练模块外部边缘的 40 个 I/O 芯片达到了 36 TB/s的聚合带宽,或者10TB/s的横跨带宽。
数据传输方向与芯片平面平行,供电及水冷却方向与芯片平面垂直。这是一个非常优美的结构设计,不同的训练模块之间还可以互连。可想而知,这是一个可以横向扩展的超级计算机架构。
当然,一开始的那个图是展开图。实际的D1训练块像是个扁扁的披萨饼盒子。

D1训练模块
D1训练网格与训练矩阵
D1训练网格
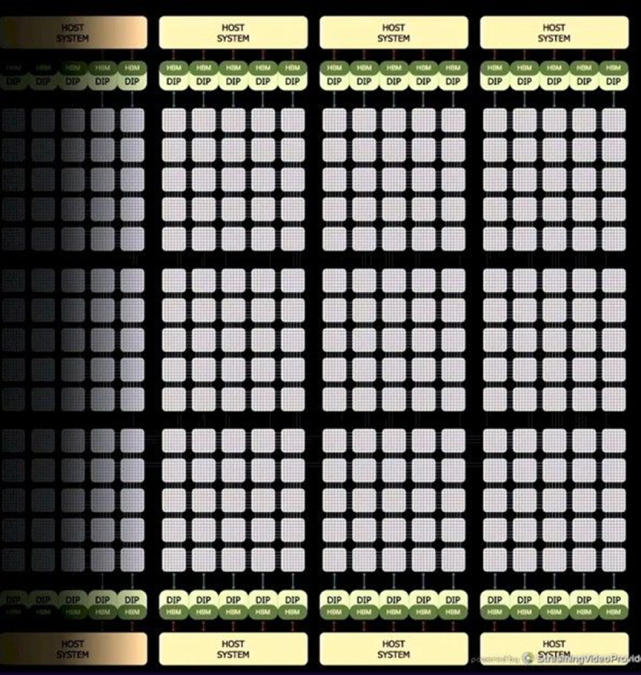
D1扩展的方式就好像自家铺地砖一样。在 D1 网格的边缘有Dojo 接口处理器(DIP)。
每个DIP包括了32GB HBM(800GB/s存储带宽),以及900GB/s的对外传输带宽(特斯拉自定义的TTP协议),32GB/s PCIe Gen4接口,以及50GB/s的以太网带宽(特斯拉自定义的TTPoE协议)
Dojo V1训练矩阵

Dojo V1 训练矩阵由 6 个训练块、4 个主机服务器上(装有20个 DIP),以及一组连接到以太网交换结构的辅助服务器构成。
这样算下来,Dojo V1 系统有 53,100 个D1 内核,在 BF16 和 CFP8 格式下算力 1 Exaflop,1.3 TB 的SRAM 内存,以及 DIP 上的 13 TB 的 HBM内存。
与其一同被揭秘的还有特斯拉ExaPod超算。

总的来说,特斯拉D1芯片有以下几个特点:
(1)2D Mesh架构;
(2)具备向量及矩阵计算加速单元的众核架构;
(3)存算一体架构(近存计算)。
据Dojo项目负责人Ganesh Venkataramanan介绍,特斯拉Dojo是史上最快的AI训练计算机。相比于业内其他芯片,同成本下性能提升4倍,同能耗下性能提高1.3倍,占用空间节省5倍。而使得Dojo完成训练AI算法的重任,就是特斯拉自研神经网络训练芯片——D1芯片。
马斯克透露,不久后,特斯拉即将开始Dojo超级计算机的首批组装,特斯拉Dojo超级计算机将于明年投用。
