大模型发展到现在,如何才能真正走向生产力?
奇偶派来自无锡的80后矿山管理者胡哥在阅遍众多大模型的介绍视频后,没忍住对我问道:“大模型能做啥?”
这就是大模型的现状——行业内火热,圈外人发懵。这不禁让人思考,大模型的时代真的到来了吗?还是只是小圈层内的自嗨?
2023年以来,以ChatGPT、Midjourney为代表的以内容生成为导向的人工智能应用,引发了一轮又一轮的创新浪潮。
让大模型技术深入生活生产的核心场景,降低使用AI的门槛,助力企业实现降本增效,成为了各家AI、科技企业都在为之努力的目标。
不过,从技术走向生产力谈何容易。一方面,算力不足的问题一直存在,另一方面,大模型能力落地,也需要寻找更多的场景。
1
决胜大模型时代
算力、网络、向量数据库缺一不可
大模型应用场景日趋多样,需求也随着增加,进而倒逼着多元算力方面的创新,为满足AI工作负载的需求,采用GPU、FPGA、ASIC等加速卡的服务器越来越多。
根据IDC数据统计,2022年,中国加速服务器市场相比2019年增长44.0亿美元,服务器市场增量的一半更是来自加速服务器。
这意味着未来算力一定是多元化的。
高性能、高弹性与高稳定的算力,对于网络速度与稳定性要求也非常高,在训练集群中,一旦网络有波动,训练的速度就会大受影响,只要一台服务器过热、宕机,整个集群都可能要停下来,然后训练的任务要重启,这些事件会使得训练的时间大大增加,所以投入在大模型的成本也会变大。
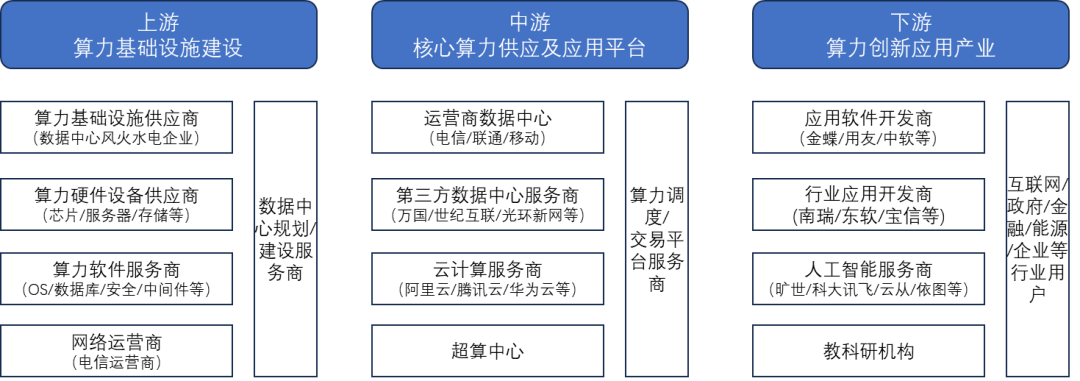
算力产业链,图源:科智咨询整理
另外,GPU服务器运营与分层次的排查也会更频琐,整体运维的难度与工作量也会高很多。
因此,云所提供的稳定计算、高速网络与专业的运维,可以为算法工程师大大减轻基础设施的压力,让他们把精力放在模型的构建与算法的优化上。
腾讯云打造的面向模型训练的新一代HCC高性能计算集群,搭载最新代次的GPU,结合多重加速的高性能存储系统,加上3.2T超高互联带宽、低延时的网络传输,整体性能比过去提升了三倍。

在大模型训练场景,速度是核心,运算速度更快意味着一切繁复的运算和模拟会更快、更准确。结合腾讯自研的软硬件技术,为企业的AI计算、高性能计算需求提供算力底座。
另外,计算集群越大,产生的额外通信损耗越多。大带宽、高利用率、信息无损,是算力集群面临的核心挑战。
为解决传输质效的问题,腾讯云通过自研“星脉”高性能网络,在软件和硬件层面,如交换机、通信协议、通信库以及运营系统等方面,都进行了升级和创新,带来的计算效果提升也是明显的。
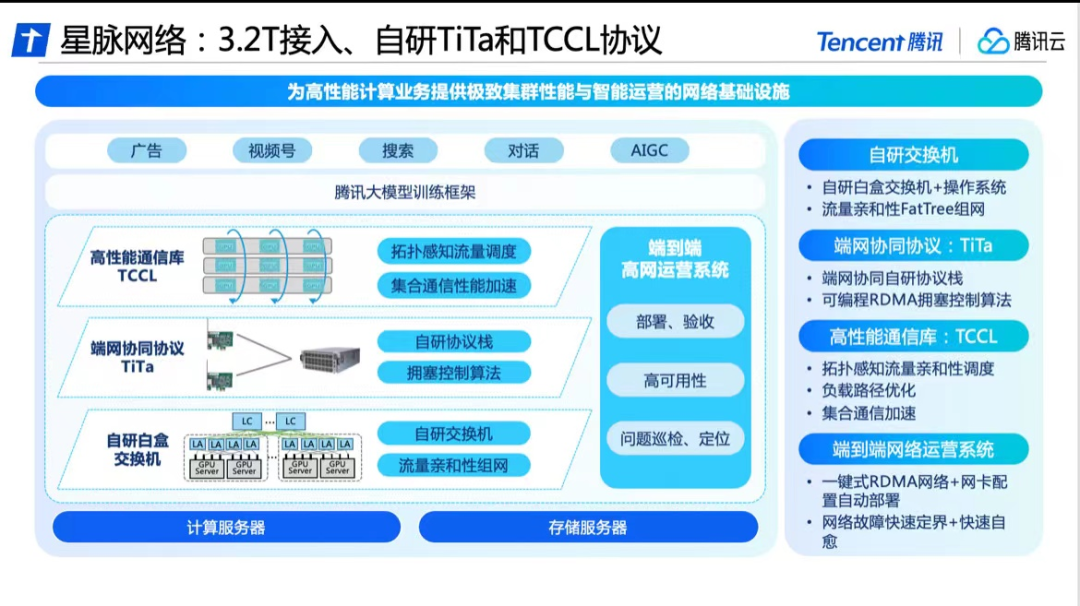
“星脉”能够提升40%的GPU利用率,节省30%-60%的模型训练成本,为AI大模型带来10倍的通信性能提升。
另外,目前的大模型都是预训练模型,对于训练截止日之后发生的事情一无所知。主要表现为没有实时的数据,并且缺乏私域数据或者企业数据。
而向量数据库作为一种专门用于存储、管理、查询、检索向量的数据库,可以通过存储最新信息或者企业数据有效弥补了这些不足。
向量数据库和大模型结合,可以降低企业训练大模型的成本,提高信息输出的及时性和准确度。最终大模型和向量数据库的结合,会成为一种通用的呈现形态或率先在垂直领域体现价值。
在扩展性方面,向量数据库可以轻松地通过添加更多节点来扩展系统性能;在检索方面,向量数据库能够实现低时延高并发检索;在兼容性方面,向量数据库不仅支持多种类型和格式的向量数据,还支持多种语言和平台的接口及工具。
腾讯云向量数据库(Tencent Cloud VectorDB),最高支持业界领先的10亿级向量检索规模,并将延迟控制在毫秒级。在大模型预训练数据的分类、去重和清洗上,可以实现10倍效率提升。

但仅有硬件远远不够,下一代的AI需要在硬件和算法方面都进行创新,大模型要想突破至下一站,需要对落地的途径进行重新审视。
2
大模型的中场战事,产业化应用正提速
从今年3月百度率先发布语言大模型生成式AI产品“文心一言”后,各大科技互联网巨头纷纷入局,国内大模型瞬间遍地开花。包括阿里、华为、商汤科技、科大讯飞、360、腾讯等,纷纷推出各类大模型。

图源:来源:ImfoQ发布的大模型评测报告
人工智能正在进入大规模落地应用关键期。
在IDC近日发布的《中国人工智能公有云服务市场份额2022》报告中,腾讯云凭借其2022年在计算机视觉、对话式AI等领域的领先优势,营收增速达到 124.6%,成为国内收入增速最快的公有云厂商。
企业拥抱大模型的方式和路径正在重构,可以预见,大模型能力落地和核心就是应用场景。
此前,腾讯对外表示,其自研的腾讯混元大模型目前已经进入公司内应用测试阶段。自身的企业级应用已经率先基于腾讯自研的混元大模型,针对不同的应用场景提供了更智能的服务,也为用户提高了工作效率。
腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ浏览器等多个腾讯内部业务和产品,已经接入腾讯混元大模型测试并取得初步效果,更多业务和应用正在逐步接入中。
在行业落地方面,如何面向广泛客户群体的同时,又能给出针对性的解决方案,腾讯云试图在两者的特质上给出答案。
其打造的大模型一站式服务平台MaaS(Model-as-a-Service)内置多个高质量行业大模型,涵盖金融、传媒、文旅、政务、教育等多个行业场景。腾讯云TI平台已经全面接入Llama 2、Falcon、Dolly、Vicuna、Bloom、Alpaca等20多个主流模型。
基于这些基础模型,腾讯云的客户只要加入自己的场景数据,就可以生成契合自身业务需要的专属模型;同时也可根据自身业务场景需求,适配不同参数、不同规格的模型服务。
具体而言,是基于腾讯云此前发布的高性能计算集群HCC、自研星脉计算网络架构、向量数据库这些技术底座,以及包含了数据标注、数据训练、加速组件等在内的TI平台,搭建面向垂类行业的大模型平台。垂类行业企业在其中进行挑选,再针对性进行数据精调,将其升级为企业专属大模型。
在一周后的9月7日,2023腾讯全球数字生态大会将在深圳正式开幕,此次大会的主题为“智变加速,产业焕新”,届时大会对云计算、大数据、人工智能、SaaS等核心数字化工具做出新的进展公布,可以看出当下腾讯云在各领域的实践状况。
3
写在最后
一家致力于AI声音克隆领域创业者赵子清告诉奇偶派,虽然自己平时在批量处理一些文件、需要写一个简单的程序时会使用ChatGPT,但像他这样频繁利用GPT的人,其实仅限于有技术背景的从业者,大部分创业者在大模型问答尝鲜后活跃度都不高。
根据调查,在大模型的创业公司中,超过80%的从业者对大模型有着深入的理解和使用经验,而在普通人群中,仅有不到5%的人了解大模型。对大模型有限的了解,造成了国内大模型创业的局限性。
但与大部分人只知道Chat的情况不同的是,各行各业中都存在着亟需大模型能力来提升生产力的场景,而利用大模型能力提升效率,是各大厂商追求的目标,也是未来发展的方向。
而腾讯也将于一周后为我们展现其在人工智能领域的最新进展,究竟有哪些行业、哪些从业人员将被大模型从繁杂的工作中“解放”出来,就让我们一起拭目以待吧。
