AI计算的未来,GPU上岸,IPU崛起
Ai芯天下前言:
AI近些年的大火,直接促进了CPU和GPU的发展,而英伟达的GPU真正借此迅速成为AI市场的主流产品之一,其势头甚至盖过了CPU。
而AI应用需要专门的处理器,而IPU正是这样的处理器。目前,AI在各行各业均得到广泛应用,IPU可以基于自身优势为世界的智能化进程增添不竭动力。

英伟达专注的GPU优势逐渐缩小
从专注图像渲染崛起的英伟达的GPU,走的也是相当于ASIC的技术路线,但随着游戏、视频渲染以及AI加速需要的出现,英伟达的GPU也在向着GPGPU的方向演进。
当硬件更多的需要与软件生态挂钩时,市场大多数参与者便会倒下。在竞争清理过后,GPU形成了如今的双寡头市场,并且步入相当成熟的阶段。
ASIC本身的成本、灵活性缺失,以及应用范围很窄的特点,都导致它无法采用最先进制程: 即便它们具备性能和能效优势,一旦无法采用最先进制程,则这一优势也将不再明显。
为保持其在GPU领域的寡头地位,使得英伟达必须一直保持先进的制程工艺,保持其通用性,但是要牺牲一定的效能优势。
相比于来自类GPU的竞争,英伟达不应该忽视Graphcore的IPU,特别是Graphcore一直都在强调其是为AI而生,面向的应用也是CPU、GPU不那么擅长的AI应用。
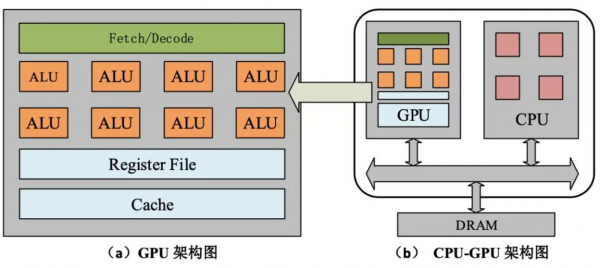
利用AI计算打侧面竞争战
不管CPU还是GPU都无法从根本上解决AI问题,因为AI是一个面向计算图的任务、与CPU的标量计算和GPU的矢量计算区别很大。
而另一边的IPU,则为AI计算提供了全新的技术架构,同时将训练和推理合二为一,兼具处理二者工作的能力。
作为标准的神经网络处理芯片,IPU可以支持多种神经网络模型,因其具备数以千计到数百万计的顶点数量,远远超过GPU的顶点规模,可以进行更高潜力的并行计算工作。
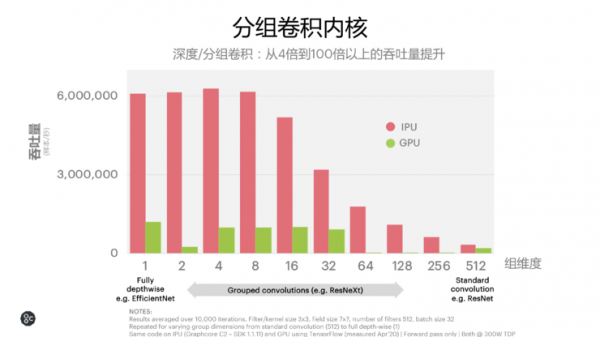
计算加上数据的突破可以让IPU在原生稀疏计算中展现出领先IPU 10-50倍的性能优势,到了数据稀疏以及动态稀疏时,IPU就有了比GPU越来越显著的优势。
此外,如果是在IPU更擅长的分组卷积内核中,组维度越少,IPU的性能优势越明显,总体而言,有4-100倍的吞吐量提升。
在5G网络切片和资源管理中需要用到的强化学习,用IPU训练吞吐量也能够提升最多13倍。

两种芯片势能英伟达与Graphcore的较量
Graphcore成立于2016年,是一家专注于机器智能、同时也代表着全新计算负载的芯片制造公司,其包括IPU在内的产品研发擅长大规模并行计算、稀疏的数据结构、低精度计算、数据参数复用以及静态图结构。
英伟达的潜在竞争对手Graphcore的第二代IPU在多个主流模型上的表现优于A100 GPU,两者将在超大规模数据中心正面竞争。
未来,IPU可能在一些新兴的AI应用中展现出更大的优势。
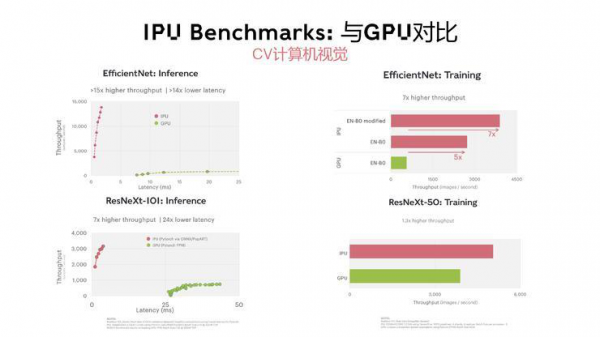
第二代IPU相比第一代IPU有两倍峰值算力的提升,在典型的CV还有NLP的模型中,第二代IPU相比第一代IPU则展现出了平均8倍的性能提升。
如果对比英伟达基于8个最新A100 GPU的DGX-A100,Graphcore 8个M2000组成的系统的FP32算力是DGX-A100的12倍,AI计算是3倍,AI存储是10倍。

1 2 下一页>
