人工智能之ICA算法
AI优化生活人工智能机器学习有关算法内容,请参见公众号“科技优化生活”之前相关文章。人工智能之机器学习主要有三大类:1)分类;2)回归;3)聚类。今天我们重点探讨一下ICA算法。 ^_^
ICA独立成分分析是近年来出现的一种强有力的数据分析工具(Hyvarinen A, Karhunen J, Oja E, 2001; Roberts S J, Everson R, 2001)。1994年由Comon给出了ICA的一个较为严格的数学定义,其思想最早是由Heranlt和Jutten于1986年提出来的。

ICA从出现到现在虽然时间不长,然而无论从理论上还是应用上,它正受到越来越多的关注,成为国内外研究的一个热点。
ICA独立成分分析是一种用来从多变量(多维)统计数据里找到隐含的因素或成分的方法,被认为是PCA主成分分析(请参见人工智能(46))和FA因子分析的一种扩展。对于盲源分离问题,ICA是指在只知道混合信号,而不知道源信号、噪声以及混合机制的情况下,分离或近似地分离出源信号的一种分析过程。
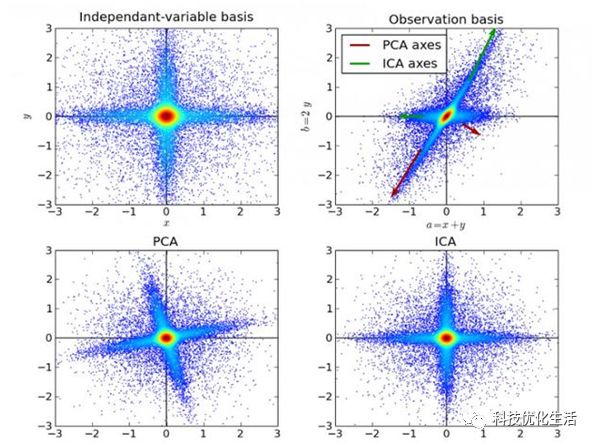
ICA算法概念:
ICA(IndependentComponent Analysis) 独立成分分析是一门统计技术,用于发现存在于随机变量下的隐性因素。ICA为给观测数据定义了一个生成模型。在这个模型中,其认为数据变量是由隐性变量,经一个混合系统线性混合而成,这个混合系统未知。并且假设潜在因素属于非高斯分布、并且相互独立,称之为可观测数据的独立成分。
ICA与PCA相关,但它在发现潜在因素方面效果良好。它可以应用在数字图像、档文数据库、经济指标、心里测量等。
ICA算法本质:
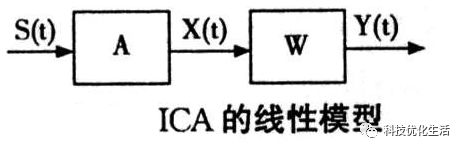
ICA是找出构成信号的相互独立部分(不需要正交),对应高阶统计量分析。ICA理论认为用来观测的混合数据阵X是由独立元S经过A线性加权获得。ICA理论的目标就是通过X求得一个分离矩阵W,使得W作用在X上所获得的信号Y是独立源S的最优逼近,该关系可以通过下式表示:
Y = WX = WAS , A = inv(W)
ICA相比与PCA更能刻画变量的随机统计特性,且能抑制高斯噪声。
从线性代数的角度去理解,PCA和ICA都是要找到一组基,这组基张成一个特征空间,数据的处理就都需要映射到新空间中去。
ICA理论基础:
ICA理论基础如下:
1)标准正交基
2)白化
3)梯度下降
ICA目标函数:
ICA的目标函数如下:
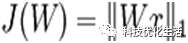
样本数据 x 经过参数矩阵 W 线性变换后的结果的L1范数,实际上也就是描述样本数据的特征。
加入标准正交性约束(orthonormality constraint)后,ICA独立成分分析相当于求解如下优化问题:
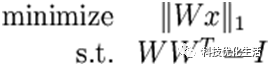
这就是标准正交ICA的目标函数。与深度学习中的通常情况一样,这个问题没有简单的解析解,因此需要使用梯度下降来求解,而由于标准正交性约束,又需要每次梯度下降迭代之后,将新的基映射回正交基空间中,以此保证正交性约束。
ICA优化参数:
针对ICA的目标函数和约束条件,可以使用梯度下降法,并在梯度下降的每一步中增加投影(projection )步骤,以满足标准正交约束。过程如下:
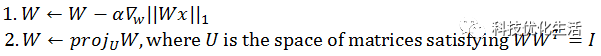
ICA算法流程:
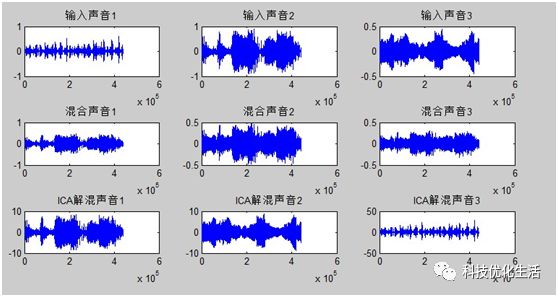
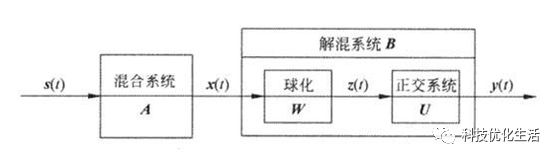
已知信号为S,经混和矩阵变换后的信号为:X=AS。对交叠信号X,求解混矩阵B,使Y=WX各分量尽量相互独立。求解W的过程并不一定是近似A的逆矩阵,Y也不是信号S的近似,而是为了使Y分量之间相互独立。目的是从仅有的观测数据X出发寻找一个解混合矩阵。
常见的方法:InfoMax方法(用神经网络使信息最大化),FastICA方法(固定点算法,寻求X分量在W上投影(W^t)*X)的非高斯最大化。
主要算法流程如下:
1、预处理部分:1)对X零均值处理
2)球化分解(白化)
乘球化矩阵S,使Z=SX各行正交归一,即ZZ’=I
2、核心算法部分: 寻求解混矩阵U,使Y=UZ,Y各道数据尽可能独立(独立判据函数G)。
1)、由于Y独立,各行必正交。且通常取U保持Y各行方差为1,故U是正交变换。
2)、所有算法预处理部分相同,以后都设输入的为球化数据z,寻找正交矩阵U,使Y=Uz独立。
由于独立判据函数G的不同,以及步骤不同,有不同的独立分量分析法。
3、Fast ICA算法思路:
思路:属于探查性投影追踪
目的:输入球化数据z,经过正交阵U处理,输出Y=Uz
1)输入球化数据z,经过正交阵某一行向量ui处理(投影),提取出某一独立分量yi。
2)将此分量除去,按次序依次提取下去,得到所有的yi ,以及ui。
3)得到独立的基向量U
U=WX
Fast ICA算法程序如下:
function [Out1, Out2, Out3] =fastica(mixedsig, varargin)
%FASTICA(mixedsig) estimates theindependent components from given
% multidimensional signals. Each row ofmatrix mixedsig is one
% observed signal.
% = FASTICA (mixedsig); the rows oficasig contain the
% estimated independent components.
% = FASTICA (mixedsig); outputs the estimatedseparating
% matrix W and the corresponding mixingmatrix A.
mixedsig为输入向量,icasig为求解的基向量。
A即为混合矩阵,可以验证mixedsig=A×icasig。
W即为解混矩阵,可以验证icasig=W×mixedsig。
ICA算法优点:
1)收敛速度快。
2)并行和分布计算,要求内存小,易于使用。
3)能通过使用一个非线性函数g便能直接找出任何非高斯分布的独立分量。
4)能够通过选择一个适当的非线性函数g而使其达到最佳化。特别是能得到最小方差的算法。
5)仅需要估计几个(不是全部)独立分量,能极大地减小计算量。
ICA算法缺点:
1) 特征矩阵W的特征数量(即基向量数量)大于原始数据维度会产生优化方面的困难,并导致训练时间过长;
2) ICA模型的目标函数是一个L1范数,在 0 点处不可微,影响了梯度方法的应用。
注:尽管可以通过其他非梯度下降方法避开缺点2),也可以通过使用近似值“平滑” L1 范数的方法来解决,即使用 ( x2+ε )1/2 代替 |x|,对 L1 范数进行平滑,其中 ε 是“平滑参数”(smoothing parameter)。
ICA与PCA区别:
1) PCA是将原始数据降维并提取出不相关的属性,而ICA是将原始数据降维并提取出相互独立的属性。
2) PCA目的是找到这样一组分量表示,使得重构误差最小,即最能代表原事物的特征。ICA的目的是找到这样一组分量表示,使得每个分量最大化独立,能够发现一些隐藏因素。由此可见,ICA的条件比PCA更强些。
3) ICA要求找到最大独立的方向,各个成分是独立的;PCA要求找到最大方差的方向,各个成分是正交的。
4) ICA认为观测信号是若干个统计独立的分量的线性组合,ICA要做的是一个解混过程。而PCA是一个信息提取的过程,将原始数据降维,现已成为ICA将数据标准化的预处理步骤。
ICA算法应用:
从应用角度看,ICA应用领域与应用前景都是非常广阔的,目前主要应用于盲源分离、图像处理、语言识别、通信、生物医学信号处理、脑功能成像研究、故障诊断、特征提取、金融时间序列分析和数据挖掘等。
结语:
ICA是一种常用的数据分析方法,是盲信号分析领域的一个强有力方法,也是求非高斯分布数据隐含因子的方法。从样本-特征角度看,使用ICA的前提条件是,认为样本数据由独立非高斯分布的隐含因子产生,隐含因子个数等于特征数,要求的是隐含因子。ICA算法已经被广泛应用于盲源分离、图像处理、语言识别、通信、生物医学信号处理、脑功能成像研究、故障诊断、特征提取、金融时间序列分析和数据挖掘等领域。
