云厂商的新战场:如何用MaaS赚钱?
市值榜
文 :武占国,编辑 :何玥阳,出品 : 数智界
今年,大模型之风,在国内已经刮了一波又一波。
无论是在乌镇召开互联网大会,还是各大互联网论坛,大模型一次又一次被大佬们捧上C位,如今百模大战的硝烟仍未停止,最终会不会是像“百团大战、百云大战”一样,赢者通吃,犹未可知。
至少目前,大部分都属于烧钱研发阶段,实现盈利、变现的屈指可数。但是,这场针对大模型训练的云厂商之战,已经拉开帷幕,各大云厂商纷纷发布了各自对大模型的服务方案。
截至目前,国内外云厂商,包括阿里云、华为云、腾讯云、百度云、京东云、微软云Azure等云计算大厂,都已经推出了MaaS服务。
推出MaaS服务对云厂商有什么影响?云厂商如何通过MaaS进行变现?MaaS能不能成为云厂商新的业务增长极?本文将回答这些问题。
一、云厂商鏖战MaaS
MaaS是模型即服务,是IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)之外的一个新概念,也是云厂商的新业务,但目前主流云厂商对MaaS的定义并未形成统一的说法。
曾经制定过IaaS、PaaS和SaaS技术标准的美国国家标准与技术研究所(NIST),目前也没有给出MaaS的技术标准,国际上也没有其他权威认证。
根据云厂商的描述,MaaS模式的核心价值可归纳为:降低算法需求侧的开发技术和使用成本门槛,用户可以直接通过API调用基础大模型,为不同的业务场景,来构建、训练和部署专属模型。
主流云厂商发力MaaS服务,存在着主动和被动两方面的原因。
第一,主流云厂商的传统业务增长放缓。
总体看,云厂商的传统业务大多是基于IaaS层的公有云业务,而PaaS和SaaS层的业务规模相对较小。在IaaS层提供服务的显著特点是,重资产、重投入,靠规模吃饭,但同质化严重,所以利润率较低。
再加上运营商的加入,竞争更加激烈,价格战频频上演。
另一方面,阿里云、腾讯云等云厂商调整了以往要规模的路线,通过主动放弃一些低利润项目,来保利润率。如互联网云厂商所愿,这两年云厂商的利润率有所改善,但增长落入10%以下的区间。比如排第一的阿里云,2023年增速已经趋近于零,相比前两年高达20%-100%的增速,已经大幅下降。
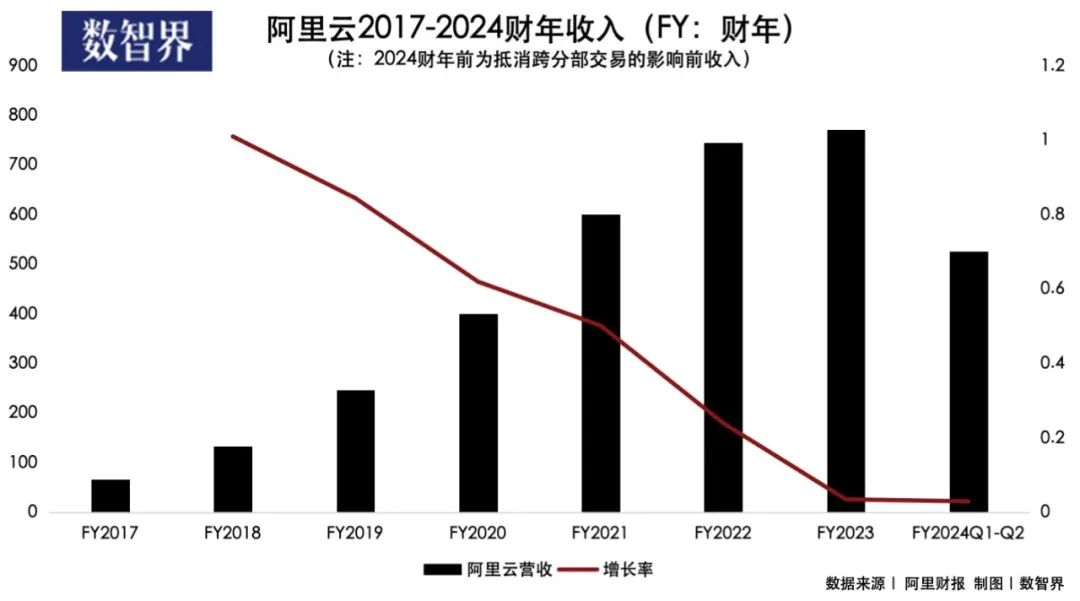
在利润率更高的PaaS和SaaS层,由于基础开发软件和SaaS业务端需求不足,国内这两层的业务量规模较低,占整个公有云市场的比例也远低于国外。
第二,大模型训练和运营,存在算力和服务缺口。
随着ChatGPT的爆火,各个大厂、企业纷纷下场做大模型,截至10月份,我国拥有10亿参数规模以上大模型的厂商及高校院所共计254家,国内已经发布了238个大模型,相较于6月份的79个,在四个月内增长了三倍。
这么多大模型的训练和运营都需要巨大的算力支持。比如OpenAI训练大模型,前期GPT-3的训练一次需要购买49台服务器,成本140万美元,日常运行成本则更高,以早期的每日2500万访问量计算,需要购买3798台服务器,成本7.59亿美元。
华为预测,2030年通用计算总量比2020年增长10倍,至3.3ZFLOPS;AI计算总量将增长500倍至105ZFLOPS。
基于这样的预期,云厂商纷纷推出了各自MaaS业务。
今年3月,李彦宏在文心一言发布会上提出,大模型时代MaaS将取代IaaS,成为主流。4月,阿里发布通义千问大模型,同时,阿里云峰会上,张勇表示,阿里云已形成模型即服务(MaaS)、平台即服务(PaaS)、基础设施即服务(IaaS)三层架构。从这样的表述也可以看出阿里云对于MaaS的重视。
今年7月初,华为云公布了盘古大模型3.0和昇腾AI云计算服务,盘古3.0可以提供从100亿到1000亿参数等四种系列化基础大模型,昇腾AI云可以提供单集群2000P Flops等算力服务。
9月初,腾讯发布自研混元大模型,同时国内企业可以通过腾讯的公众云平台接入混元,并根据具体需要进行微调。
二、云厂商如何通过MaaS变现?
目前业界对MaaS的定义存在分歧,包括MaaS与IaaS、PaaS、SaaS之间的关系,以及未来MaaS是否会重新定义IaaS、PaaS、SaaS,这些都存在不同看法。
目前云厂商,已推出的MaaS相关服务,主要包括基于IaaS的AI算力服务,以及通过自研大模型或开源大模型提供API调用服务。
第一,API调用服务是MaaS最核心的变现方式。
API调用服务就是,云计算平台将机器学习模型封装成可以调用的云服务,用户通过API接口或者其他方式,来调用模型的能力。
这个过程中,云厂商可以根据用量或者时间来收费。
比如,OpenAI推出GPTs及相应自然语言开发工具。OpenAI共制定了四种收费模式,分别是ChatGPT Plus订阅收费、API(除GPT模型接口外,还包括模型微调接口和嵌入接口)调用量收费、文生图按生成量收费和音转文按分钟收费、模型实例租用收费。
其中,GPT-3.5模型是按调用token(分解单元,中文大致等同于一个词)数量计费,每10万个token收取4美分。美国应用市场排名靠前的应用,服务营销文案的Jasper和聊天机器人Chat with Ask AI都是基于OpenAI旗下模型开发的应用,其最核心的成本也是给OpenAI的API调用费。
第二,给训练、运行大模型提供AI算力服务。
算力服务一直是云计算最初级的服务,也就是IaaS层的服务。IaaS,最初就是为企业提供集中服务器、数据存储等底层的技术服务,后来在此基础上发展出了PaaS和SaaS。
跑大模型需要的是AI算力,而非以往的通用算力,AI算力的需求,对云厂商IaaS层的服务器、网络、存储等都产生了重构。比如,在提供算力的服务器,需要采购大量的搭载英伟达的GPU服务器,重新搭建建立在其基础之上的系统和网络服务。
大模型未来也有可能重构PaaS层和SaaS层。
在此基础之上,云厂商也可以探索新的付费模式,比如基于开源模型,形成开发者社区,实现AI PaaS服务,给开发者提供除算力和模型之外的服务,比如提供开发者训练大模型需要的数据库、中间件等服务。
此外,在SaaS层,更多企业的SaaS产品开始基于AI(AI-based-SaaS),AI从SaaS的辅助工具到AI原生SaaS(基于特定大模型的SaaS产品),再到AI agent SaaS(智能体即服务),都将经历在应用层探索。
三、通过MaaS赚钱,存在哪些困难
首先我们需要厘清,云厂商提供MaaS服务,想赚谁的钱?
模型厂商的钱,包括大模型和行业模型,比如百川智能就是在阿里云上跑的,行业模型是一个趋势。最终赚的是B端企业的钱,针对C端的AI应用变现问题,我们在此前的文章《大模型太卷,AI应用就好做吗?》中讨论过。
云厂商也可以自己去做行业模型,不过每个行业来一遍,投入高,周期也比较长,增加了盈利的难度。
当大模型投资热回归理性之后,理想的循环是,企业客户可以将行业大模型以及其提供的工具,应用于自身运营、生产、财务管理等多个业务中,应用之后效率提升,才会愿意持续付费,这样一来模型厂商赚钱,云厂商也赚钱。
技术落地的过程是从模型到工具再到场景,商业化却是从应用场景开始的。
中国的PaaS和SaaS占公有云市场比重低,部分原因在于盈利能力弱,所以评估收益与成本之后,为SaaS付费意愿不高。
所以,云厂商通过MaaS服务可能会遇到与SaaS相似的问题,即从供给端到需求端,都未形成如国外那样成熟的管理模式和市场环境,也没有形成标准化产品,无法进行低成本复制。(详见《中国SaaS之殇:差距是如何被一步步拉大的》)
当然,MaaS与SaaS也有不同,因为有大模型的辅助,MaaS在用户定制化的需求上,能够有更好的适配,因此在标准化和定制化之间的两难,会得到一定解决。
赚不赚钱,另一个重要的因素在于成本。
提供MaaS服务对AI算力有极高的要求,云厂商需要采购大量的GPU芯片,用来搭建新的服务,来满足日益增长的AI算力需求。今年微软和Meta各买了英伟达15万片H100GPU,百度、阿里和字节分别买了3万、2.5万和2万片。这些芯片,都将部署在新的适配于大模型训练和运行的服务器上。
除了外部采购,国内云厂商也在加紧脚步布局自研AI芯片,或拓展其他购买渠道。
今年10月23日,美国开始实施新的芯片出口管制,英伟达高性能AI芯片——A800、H800、L40S等,被禁止出口。这导致国内云厂商,无法买到国外高性能芯片,这些成为制约国内云厂商提供AI算力的制约因素。
一份研报显示,一台搭载英伟达A100芯片的服务器成本在20万美元,单个服务器搭载7片A100芯片,单片芯片价格在1.5万美元左右。
云厂商斥巨资买来的计算资源,需要足够大的使用量级和用户规模,才能产生效益。而随着大模型热褪去,是否会出现资源的闲置,谁都说不好。
