一文了解清理数据的重要性
磐创AI介绍
在精神上和卫生上进行清洁的概念在任何健康的生活方式中都是非常有价值的。数据集有些是相同的。如果没有在数据科学生命周期中进行清理或作为日常活动进行清理,那么出于任何目的的代码将根本无法工作。在数据分析中,选择了许多生命周期。在这里,我选择了CRISP-DM框架,并专注于步骤3 –数据准备。
好处和学习成果:
用于教育目的的参考指南
解决代码中的几个问题之一
数据类型和数据结构
熟悉DataBricks,RStudio和Python编程Shell
适应各种环境中的Python和R编程之间的转换
熟悉CRISP-DM框架中的一些步骤
要求可能包括:
数据类型的基础知识
对细节的稍加注意
统计和数学的基础知识
适应在不同平台上切换编程语言和编码语言
关于CRISP-DM的基础知识
“大数据”软件的基本知识,例如用于Python编程的Apache Spark及其相关库
本文将结合Python Shell、DataBricks和RStudio,介绍Python编程和R编程。
注意:这假定库和代码都兼容并且熟悉对上述平台的合理访问。
顺序
1. CRISP-DM:数据准备
2. CRISP-DM:数据建模

一、CRISP-DM:数据准备
无论代码中包含哪些包和模块,数据类型都将决定是否可以使用代码将数据集输入算法中。以下Python编程数据类型可以包括但不限于:
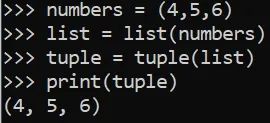
元组
numbers = (4,5,6)
list = list(numbers)
tuple = tuple(list)
print(tuple)
(4,5,6)
向量转换
在DataBricks中将字符串或字符串数组转换为Vector数据类型
DataBricks是一个类似于云的在线平台,允许出于教育目的进行编码。
DataBricks由其自己的结构和目录或路径组成。为了使用任何编程语言,始终必须启动“内核”。
该平台几乎类似于一个编程笔记本,可视化数据是用户友好的。
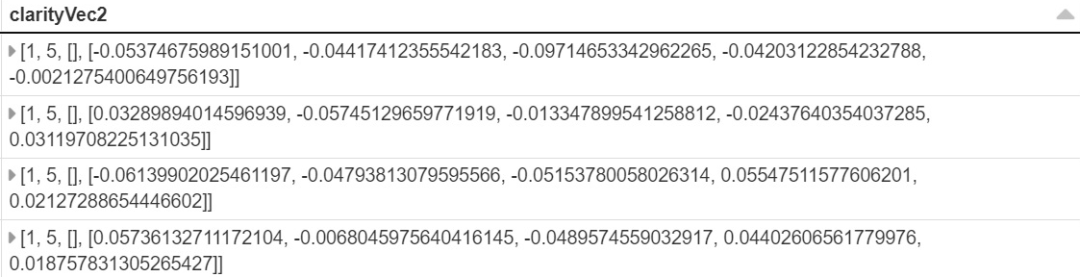
import Word2Vec
word2Vecclarity = Word2Vec(vectorSize=5, seed-42, inputCol="clarityVec", outputCol="clarityVec2")
model=word2vecclarity.fit(diamonds)
diamonds = model.transformation(diamonds)
display(diamondsa)
矩阵
数组(不止一个)维的数量确定该数组是否为矩阵。
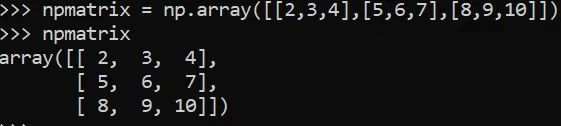
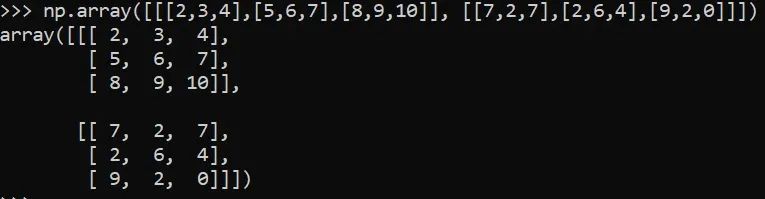
np.array([[2,3,4],[5,6,7],[8,9,10]])
np.array([[[2,3,4],[5,6,7],[8,9,10]], [[7,2,7],[2,6,4],[9,2,0]]])
数组
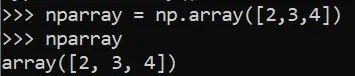
np.array([2,3,4])
列表

ingredients = 'apple', 'orange', 'strawberry'
list = list(ingredients)
print(list)
['apple','orange','strawberry']
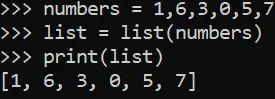
numbers = 1, 6, 3, 0, 5, 7
list = list(numbers)
print(list)
[1, 6, 3, 0, 5, 7]
字符串

str('I have quotation marks')
整数
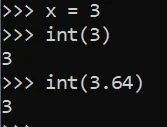
x = 3
int(x)
int(3.64)
3
浮点数
整数将在其值上添加小数点后第十位。
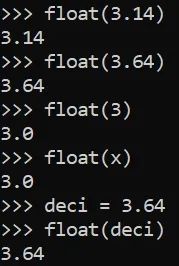
负浮点数
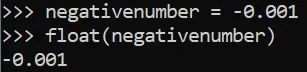
在将数据集转换为视觉图像,存储数据和将数据集用于机器学习预测时,数据类型很重要。
二、CRISP-DM:数据建模
成功清理数据后,即可完成数据建模。以下是一些模型以及每个模型的简要提要:
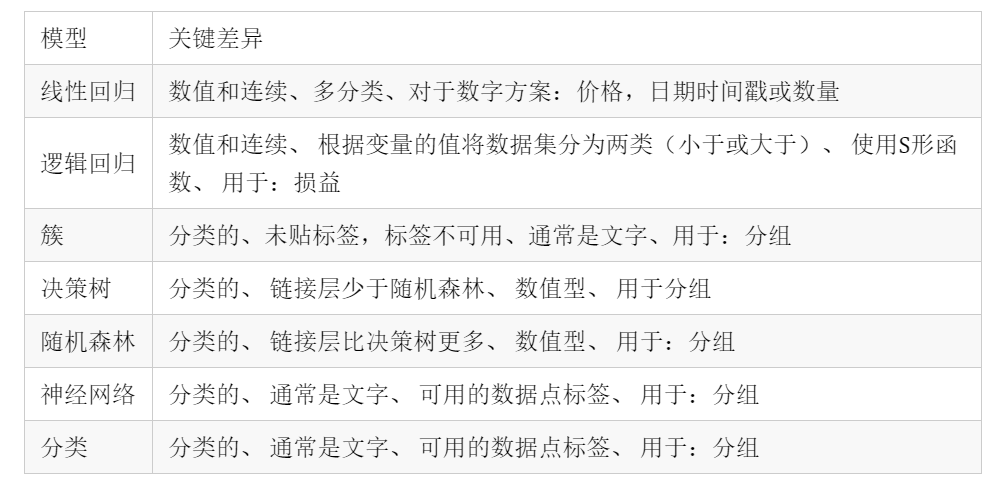
尽管这些是通常的定义,但是模型可以组合到一个代码中,并且可以用于不同的目的。
了解一些统计概率分布将有助于衡量性能和准确性得分。概率分布的另一个目的是假设检验。
假设检验:

示例1:使用数值多元分类的线性回归
该数据集与珠宝价格有关。Databricks平台上显示的用于python中向量的示例可以帮助解释任何机器学习代码或算法如何需要特定的数据结构和数据类型。从文本到数字,更改选定列的数据类型可以产生有效的数据集,并输入到机器学习算法中。由于在此示例中涉及价格,因此包含了称为连续数的数字的不同变化。这表明这是一个使用数字多重分类方法进行测量的方法。下图是数据集的数据类型方案:

将清理后的数据集输入到你选择的任何机器学习算法中(此示例使用Python Spark)后,即可进行可视化。
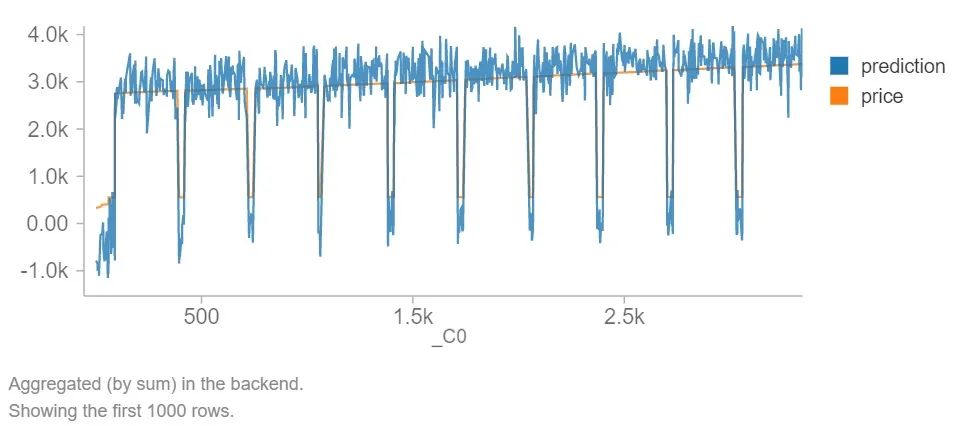
下图是DataBricks中数据集的可视化。
解释:预测与价格密切相关,但代码中有一些噪音。这是一个成功的机器学习代码和可视化图。如果没有DataBricks,则根据你喜欢的库(Matplotlib,Seaborn)绘制图形,并将价格和预测与所选图的图形标签和颜色重叠。
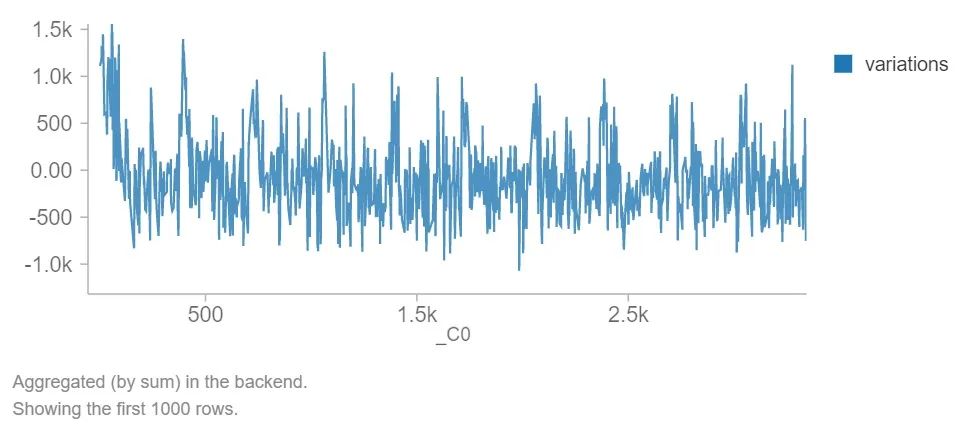
解释:预测和价格数据点之间的差异。_C0是一个ID号,在相关性或统计结果中没有太大的价值。但是,它确实显示了波动的模式,有峰有谷。这是一次对噪音的仔细检查。
清理后的另一个好处是可以使用度量标准来度量结果。
这是一份不错的结果清单。结果表明,该代码可以预测珠宝的价格。虽然列出了解释的方差,均方根误差,均方根绝对误差和均方根误差,但在判断结果之前要参考特定范围。判断基于先前的研究结果,并确定将这些结果与过去进行比较的可信度和可靠性。这些数字最终将被置于一定范围内。如果这些数字在最小和最大范围之间,则可以接受。如果不是,那是不可接受的。简而言之,它基于上下文。始终知道R平方值和R值是介于0和1之间的数字。0表示弱,1表示强。
从数学中导入sqrt后,可以进行以下度量。
print(metrics.explainedvariance)
print(metrics.rootMeanSquaredError)
print(metrics.meanAbsoluteError)
print(metrics.meanSquaredError)
print(metrics.r2)
print(sqrt(metrics.r2))
explained variance: 16578542.773449434
root mean squared error: 432.08042460826283
mean absolute error: 338.73641536904915
mean squared error: 186693.4933296567
r-squared value: 0.9881558295874991
r-value: 0.9940602746249843
示例2:使用K-均值聚类
二进制或限于两个类别
该数据集与金融信贷数据有关。目的是在继续为个人帐户提供服务之前检测财务欺诈。选项是无限的,这是有几个在RStudio中使用Python编程语言的示例。下面的代码显示:软件包安装,内核和Spark上下文设置
library(reticulate)
repl_python()
from pyspark.sql.session import SparkSession
from pyspark import *
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.sql.functions import col
from pyspark.sql import SQLContext
import ctypes
import pandas as pd
import numpy as np
# Change "kernel" settings
kernel32 = ctypes.WinDLL('kernel32', use_last_error=True) # should equal to 1
# This line of code should output 1
kernel32.SetStdHandle(-11, None) # should equal to 1
# This line of code should also be an output of 1
kernel32.SetStdHandle(-12, None)
conf = SparkContext(conf=SparkConf().setMaster("local").setAppName("PySparkR").set('spark.executor.memory', '4G'))
sqlContext = SQLContext(conf)
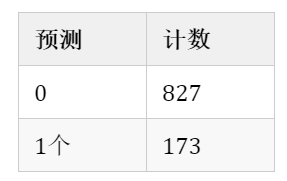
K-均值聚类是用于在本示例中构造预测的统计模型,用于将数据集预测二进制或分类为两个区域。结果有助于区分数据点以准确预测未来价值。此处,“ Predictionst” –在Python Spark数据帧内计算所选集群的数量。
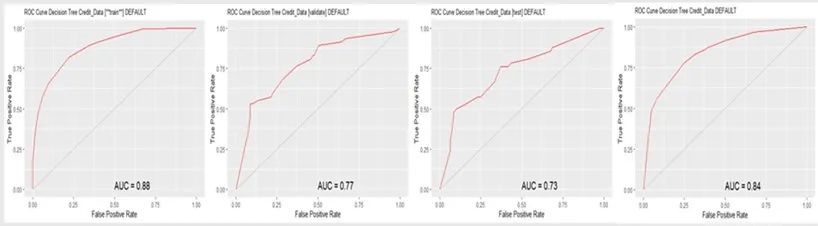
示例3:具有ROC / AUC分数的决策树
该数据集与前面提到的金融信用数据集大致相同。以下是数据集的一些指标得分。ROC(receiver operating characteristic curve)在RStudio中使用Rattle评分。从Python编程语言中输入的RStudio数据集,可以将保存数据集的变量转换为R和Rattle。使用了不同的模型,但是使用了相同的数据集。ROC / AUC分数被认为是不错的分数。部分决策树输出:
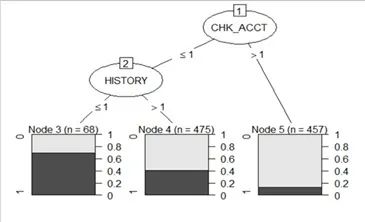
解释:该图像是决策树的一部分。图片显示了数据集中每个变量的优缺点。
解释:下图使用R-Programming中的Rattle来显示数据点之间判别坐标的可视化。因为设置了2个聚类的K均值,所以显示了两个聚类,并且数据点用一个极值表示的三角形表示,将另一个极值表示成圆形。
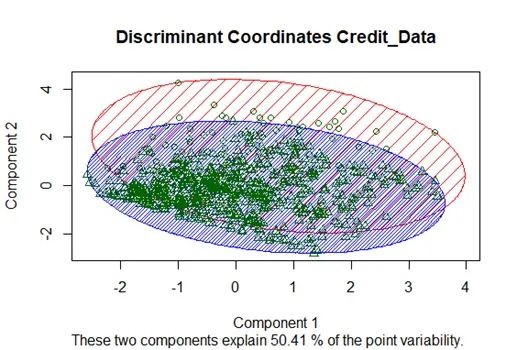
总结与结论
数据准备后,可以成功处理数据建模和评估。
数据准备是CRISP-DM框架的第一步。
如果没有数据准备或清理数据集,代码将带来错误。
尽管这不是编码中的唯一问题,但这无疑是以下几个原因之一。
有益的是学习一种以上的编程语言来实现一个共同的目标。
数据模型和概率分布可以组合。
使用其他编程语言可以轻松访问视觉效果。
可以使用一种通用平台以多种语言编写。
参考文献
[1] W3schools, (2020). Python Change Tuple Values. Python Tuple Data Types on W3schools.
[2] W3schools, (2020). Python – Matrix. Python Matrix on W3schools.
[3] Scikit-Learn, (2020). Choosing the right estimator. Estimators on Scikit-Learn.
