隐私计算迎来“开源革命”,高质量项目有哪些?
算力智库如果说隐私计算赛道,最近的热门关键词是什么?
“开源”当属其一。
随着数据要素市场培育提速,隐私计算作为数据安全流通的关键技术解,如何加快其技术开发以及商业化的速度成为市场关切。
从2020商业落地元年,再至今年,在隐私计算技术服务商与B端客户的深度磨合和诉求匹配中,市场越发共识到,隐私计算的“商业化蓝图”中,高性能算力、开源生态、软硬件工程优化以及场景适配成为“标配项”,缺一不可。而“开源”则被视为隐私计算通向性能提升、规模化落地的重要路径和技术手段。
去年10月,央行等部门联合印发《关于规范金融业开源技术应用与发展的意见》,强调“鼓励开源技术提供商,加快提升技术创新能力,切实掌握开源技术核心代码,形成自主知识产权,夯实产业支撑能力”。
算力智库发现,自今年至8月份,已先后有蚂蚁集团宣布开源隐私计算框架“隐语”,九章云极发布YLearn因果学习开源项目,原语科技推出隐私计算开源平台Primihub,翼方健数宣布开源翼数联邦学习与翼数安全计算,肉眼可见,开源逐渐“风行”,开源队伍也已不是阿里、字节、百度等大厂专属,一些诸如原语科技、翼方健数这样新锐的力量也在陆续加入。
与此同时,今年5月份,由产学研用近50家单位联合发起的国内首个国际化自主可控隐私计算开源社区——开放群岛(Open Islands)开源社区也正式成立。
“开源吞噬一切”,这是极客们口中的箴言,拥抱开源成为全球基础软件行业的主流之路,在过去的25年,开源驱动了绝大多数的技术创新,从我们智能手机上搭载的应用,到浏览的每一个网站、平台,再到物联网时代万物之间的协同交互,可以说世界上90%以上的代码,背后都有开源的身影。
而对于尚处技术萌芽期的隐私计算而言,开源革命才刚刚开始。
隐私计算二连问:
为什么要开源?为什么是现在?
隐私计算作为数据流通的基础设施,其开源的必要性,不仅在于实现技术本身优化迭代的通用需求,同时也是基于其服务数据要素流通的特殊性。
“如果隐私计算和联邦学习技术只是掌握在少数寡头的手里,我们还是得不到真正的数据流通,也得不到真正的数字经济发展,因此必须把门槛降低,其中一个有效手段就是开源,能够让人人都可以使用这样的技术,人人都能贡献到这样的技术”,香港科技大学计算机与工程系讲席教授、FATE开源社区技术指导委员会主席杨强如是表示,同时他也是上述开放群岛(Open Islands)开源社区的执行主席。
从目标导向来说,数据使用的边际收益是递增的,只有实现广泛流通的数据要素市场,才能创造释放更大的数据价值,这意味着必须要打通基础设施的闭环,消解技术孤岛,如果巨头们皆出于商业趋利性,而实行技术封闭垄断,是无利于隐私计算的可持续长远发展,对于隐私计算这种“作用于和栖身于”数据流通场景中的技术属性而言,开放性、普惠性才是其应有之义。一位隐私计算行业从业者向算力智库表示。
杨强也表达了同样的观点,他认为在隐私计算、联邦学习的商业路线图上,安全、效率、有效性、普惠是纬线,开源生态主导的技术迭代与场景普及是经线,开源促进了隐私计算的“普惠”与价值共生。以联邦学习开源社区FATE为例,FATE的开源开启了国内隐私计算技术的开源浪潮,有效降低了“联邦学习”的技术门槛,据中国信通院调研统计显示,55%的国内隐私计算产品是基于或参考了开源项目,FATE开源社区加速了联邦学习从“大厂”向小微B端企业的覆盖与普及的同时,让联邦学习产业生态及参与方从“单兵作战”走向生态化。
此外,另一个显而易见的原因是“从技术开发的供给侧来说,利用现有资源,不需要重复开发,再造一次轮子,站在既有的技术基础上,抓住已经锤炼验证过的生态系统和场景,再钻研添加自己的创新,也不会造成技术资源浪费。
从银行金融、医疗机构等需求侧来看,不同技术路线的隐私计算产品在互联互通上存在先天壁垒,“各自割据”,以至于在实际支撑数据计算分析和跨业务决策上无法兼容通用;而且一个很重要的问题是,隐私计算以算法驱动,其“算法黑箱和数据黑盒”后门风险也伴随而生,虽然隐私计算厂商一直承诺“安全可信可靠”,不会窃取和留用数据,但如何能真正取信于人,自证清白呢?蚂蚁集团隐私智能计算部总经理、“隐语”框架负责人王磊亦表示:“从技术层面,如果别人看不到我们的代码,就不能确认产品的安全性,那又谈何信任,只有以开源共享的方式,吸引更多优秀的开发者加入,才能凝聚技术合力降低隐私计算开发者和使用者的技术门槛。”
可以观察到,近几年来,无论是监管合规层面、还是个人信息保护、业务风控上对于算法和模型的可解释性及安全性要求越来越高,比如2021年3月,央行发布并实施的《人工智能算法金融应用评价规范》要求,应用AI算法需满足安全性和可解释性;2021年末,四部委联合发布的《互联网信息服务算法推荐管理规定》,其中在用户权益保障方面,特别规定算法推荐服务提供者应当以显著方式告知用户其提供算法推荐服务的情况,并以适当方式公示算法推荐服务的基本原理、目的意图和主要运行机制等。
“可解释性”和“零信任”应该成为技术基因,隐私计算也不例外,开源通过全代码的公开可验证有利于使用者了解其技术逻辑,促进技术透明化,才能做到不证自明”,上述那位隐私计算行业从业者继续表示。
值得注意的是,就在前几年,开源在隐私计算圈并未流行开来,而至如今,开源走热,呼声高涨。
“为什么隐私计算开源开放越来越被重视,是因为恰逢其时,首先,是顺应全国统一大市场的趋势,一开始我们更多地强调隐私计算使用的是哪一项技术,而不是特别关心要达到什么目的,所以可能有点跑偏了,比如有些厂商特别强调隐私计算要使用多方计算才安全,使用其他的一些技术就不安全。所以在技术选型上,A金融机构用的是一类技术,B用的是另一类技术,C可能是大数据公司,用的第三类技术,标准不一,以至于当大家想互联互通的时候,却发现这些技术之间很难沟通,所以现在提出统一大市场非常及时;其次,某种程度上,开源也是隐私计算逐步走向成熟的标志,越来越多的企业选择开源,一是相信自己的产品和技术实力,二是开源可以为隐私计算大规模落地应用和创新提供更加高效的解决方案,基于开源协作的方式,用户、生态伙伴等更多角色的参与,使得技术接受更多维度检验,也能够建立起更加敏捷、全面的反应机制,随时响应安全风险,极大提高了软件算法的安全性与迭代效率。”杨强表示。
技术赛马,有哪些高质量开源项目?
开源成为“潮流”,高质量选手云集。
据算力智库不完全统计,近年来国内外很多大厂和创业团队都在积极开源。
表1:隐私计算主要开源框架/平台
(数据统计:信通院、算力智库)
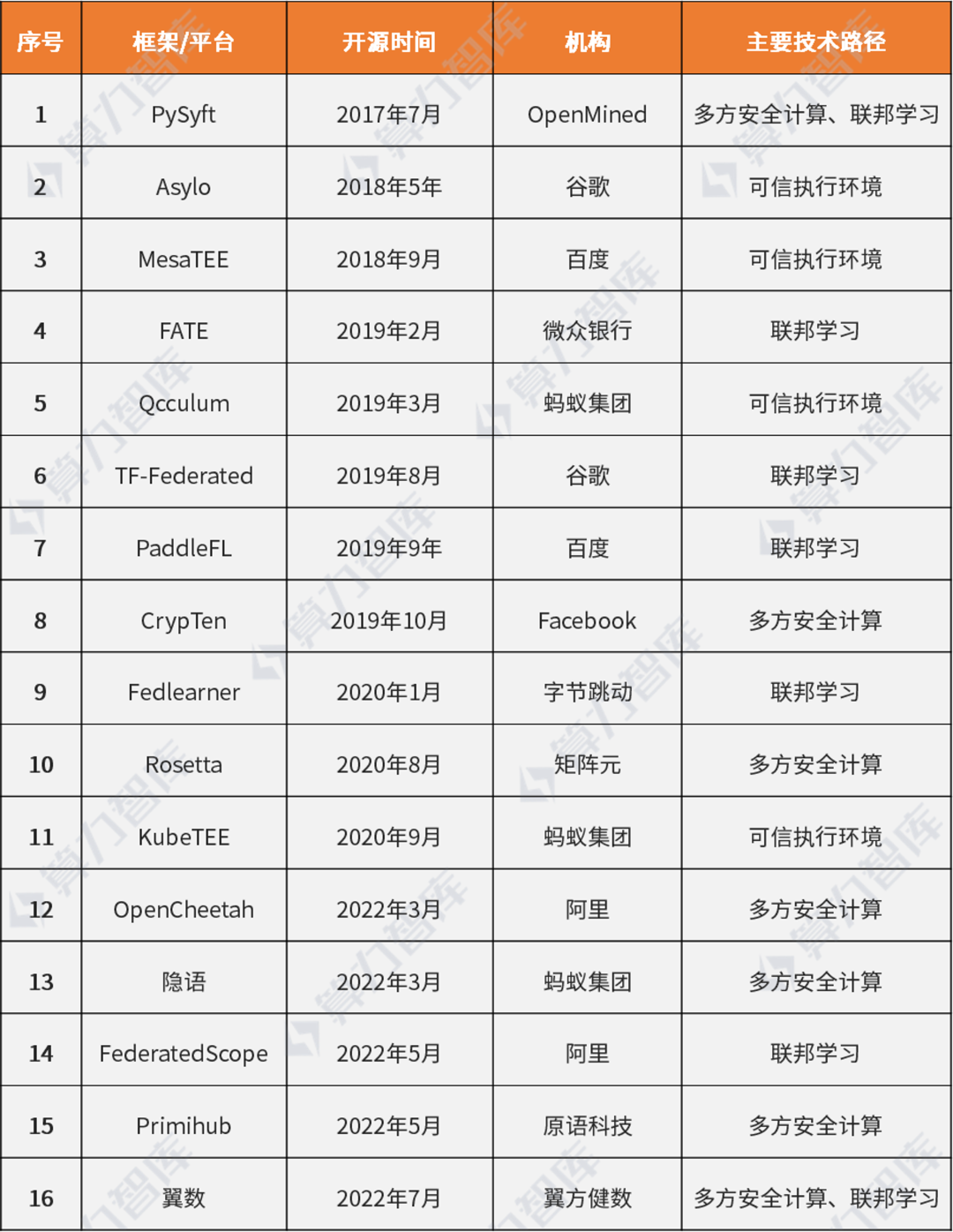
当前隐私计算开源项目大致可分为协议框架开源和产品开源,协议框架开源大部分是针对于某一技术,如MPC领域的mp-spdz、OpenCheetah等,专注于安全与性能提升。另外也有对产品平台的开源,更易形成生态。总体来讲,优秀的底层开源协议可以嵌入到平台中被广泛应用,而隐私计算的产品开源项目大部分仍处于初期,仅代码开放但社区建设不完备。上表是国内外主要的开源平台或协议框架,可以看出近三年越来越多的企业加入隐私计算开源队伍,有包括底层技术协议,也有企业的平台类项目。
面对目前市场上的众多开源方,开发方和使用机构更关注哪些指标?一位隐私计算企业技术负责人透露:目前在各种隐私计算的开源框架中,以联邦学习和多方安全计算开源框架居多,这两种技术路径相对比较成熟且逐渐形成主流。在和一些大型商业银行合作时,他们通常会考虑在成熟框架上自研,从联合开发起步。
蚂蚁集团隐私智能计算技术部总经理王磊也指出,银行在招标和共建时主要关注技术的易用性和合规性,如果一个框架使用门槛高就很难用起来,另外,比较关注技术合规标准问题,但这方面行业仍在摸索阶段。
客观来说,软件生态建设比软件本身的研发更加困难,隐私计算若想取得工业级规模化应用,还需要做很多超出隐私计算之外的事情,而生态构建是关键一步,通过开源开放可以增强生态中各界之间的粘度。
翼方健数首席科学家张霖涛亦表示:伴随技术发展,越来越多的行业玩家都已具备了相当的技术实力,想要进一步拉开竞争差距,就必须对行业有更深入的洞察,而不再是纯技术问题。人工智能等新科技领域的开源历史已经给隐私计算提供了借鉴参考,获得绝对技术优势也变得更难,TensorFlow、PyTorch等开源框架的出现,就在技术竞争之上转向吸引更多人进入AI赛道,推动AI的整体发展。
可见,“开源”正在拉开隐私计算技术赛马的下一征程,从比拼技术,到重生态,整个赛道的价值观和站位开始向“更具包容性、扩展性和连接性”倾斜,成人达己,合力共建开源生态社区和数据要素市场,才是长期主义的发展路径。
参考资料
中国经营报《隐私计算开源创新 数据市场有望提速》经济观察报《杨强:隐私计算为何要开源?》雷锋网leiphone《蚂蚁“隐语”开源,迈过隐私计算的「界河鸿沟」》SegmentFault思否《我们对“开源”的力量一无所知,却无限期待》隐私计算联盟《发布|2022隐私计算十大观察》
