【编译器玄学研究报告】第一期——位域和volatile
TXP嵌入式【写在前面的话】
在鸽了将近4年之后,我终于良心发现,决定重新恢复【裸机思维】公众号的更新。谢谢大家的长久守候和等待——非常非常抱歉。这段期间,发生了很多事情,我也憋了很多内容想跟更多的朋友分享。作为一个开端,我准备踏踏实实的从一些小的话题开始,慢慢恢复写作状态。《编译器的玄学研究报告》就是这样一个系列,我会为大家分析一些常见的、同时也是最新的、嵌入式编译器使用中可能会遇到的问题——尤其是那些看似是玄学的现象——为大家庖丁解牛、由浅入深,不仅给个痛快,也给大家个明明白白——我最终的目的是希望大家不惧怕优化,不要把编译器的行为看作是玄学,最终人人都拥有屈驾最高优化等级的知识和信心。在正文开始前,给大家提个小问题:你们用过的最高优化等级是什么(编译器是什么)?遇到过什么问题?欢迎大家在评论区留言。我会筛选最高赞的评论,并尝试在以后的《编译器玄学报告》中为大家解答。
【正文】
位域和volatile大家再熟悉不过了:前者用于将指定类型的整形变量按照我们的意愿像蛋糕一样切分成或大或小的若干份;后者用于告诉编译器“绝不允许对被修饰的变量动手动脚(做优化)”,因为在“编译器不知道的情况下”,这个变量的值是可能会因为各种原因被更新或者是改变的。
外设(peripheral)本质上就是大家最近热炒的“硬件加速器”。在遥远的过去,UART、SPI这类外设其实都只是一个通信协议,由软件通过操作GPIO(最多配合引脚上的外中断)来实现。后来,为了降低CPU的负担(offload CPU)、提高能效比(Energy Efficiency),软件UART和SPI的硬件加速器被制造了出来——这就是大家熟知的硬件UART和SPI的由来。
说到“降低CPU负担”,实在有个槽不吐不快:外设存在的意义就是为了“解放CPU”——让原本通过软件来实现的功能由硬件来做——不仅做得更好更可靠,而且消耗的能量更少。问题是,当CPU解放以后,CPU应该做啥呢?或者说多出来的CPU时间、多出来的运算性能CPU应该用来做啥呢?一般来说,有以下几个直接的选项:
时间空出来了,我就可以做更多别的事情了呗……
时间空出来了,我好像没别的事情做,那就……睡一会儿呗……
然而,我们广大的可爱的朋友们用实际行动告诉我们:
时间空出来了,我就托着腮看着外设,直到它完成工作……呗……
//! 我故意不用STM32的例子,以防止更多的人受到冒犯//! 一个串口发送单个字符的例子,这个代码是我自己写的int stdout_putchar(char txchar){ CMSDK_UART0->DATA = (uint32_t)txchar; while(CMSDK_UART0->STATE & CMSDK_UART_STATE_TXBF_Msk); //!托腮 return (int) txchar;}

以上内容扯远了……
为了后续的讨论更加简单直接,我想重复下很多你们“肯定”注意到了的“废话”:
外设是可以跟CPU同时工作的
外设寄存器的值在CPU没有改写的情况下是会被外设自己更新的
正因为如此,定义外设寄存器的时候要用volatile来修饰
接下来,我再来介绍一些很多人一般不会注意到的事实:
寄存器的访问是有对齐限制的
一个只支持WORD对齐访问的寄存器,如果你直接用Half-WORD的地址去访问,比如访问一个4字节寄存器的高16位,你是很可能会触发bus fault的
通常,大部分外设都支持多种访问对齐形式,比如WORD对齐、Half-WORD对齐和字节对齐,所以你不太会遇到这类问题。但有些外设本身设计比较“朴素”——你可能就会遇到这类没有盖上盖子的下水道。

寄存器的访问是有大小限制的
一个只支持以WORD大小访问的寄存器(只支持用volatile uint32_t *指针类型来访问的寄存器),哪怕你地址对齐了到了WORD,如果你用字节大小去访问(用volatile uint8_t *指针类型来访问),你也是很有可能会触发bus fault的。
通常,大部分外设都支持多种大小的访问,比如WORD大小的访问、Half-WORD大小的访问和字节大小的访问,所以你不太会遇到这类问题。但是,有些外设本身设计比较“朴素”——你可能就会遇到这类没有盖上盖子的下水道。
目前几乎所有32位处理器中使用的寄存器都是32位的,所以谁还会用字节大小去非对齐的访问32寄存器呢?(何况大部分情况下,寄存器的头文件都是官方提供的)。
NO,NO,NO,你太天真了。让我们来看一个案例(同时为了防止人们对号入座,以下当事人和代码都已经打码)

typedef struct { volatile uint32_t SEL : 8;} example_reg_t
#define EXAMPLE_REG_ADDR 0x40000000#define EXAMPLE_REG (*(example_reg_t*) EXAMPLE_REG_ADDR)
void set_selection_field(uint_fast8_t chSelection){ //! 使用位域来直接访问 SEL[0:7] EXAMPLE_REG.SEL = chSelection;}在这个代码里我们用位域定义了一个寄存器叫EXAMPLE_REG,它的地址是0x4000-0000,其BIT0~BIT7是一个叫做SEL的8bit无符号整型位域。这里,volatile正确告诉了编译器“不要对操作进行优化”,而uint32_t则正确的告诉了编译器SEL所寄宿的整形类型是一个WORD——“飞龙骑脸怎么输”?
事实证明,在Arm Compiler 5(也就是大家熟知的armcc)下的确没有问题,这是生成的代码:
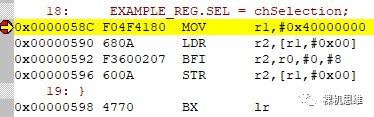
为了方便大家理解,这里逐条解释如下:MOV r1,#0x40000000 ; 将地址值 0x40000000 存入r1LDR r2,[r1,#0x00] ; 将 r1 当作指针变量,读取偏移量为0x00的一个word到r2中BFI r2,r0,#0,#8 ; 将保存在r0中由用户传入的值提取低8位覆盖r2的低8位STR r2,[r1,#0x00] ; 将 r1 当作指针变量,写入r2中的WORD到目标地址BX lr ; 返回上一级函数
可见,这里的代码生成完全满足我们的要求。当我们移植同样的代码到LLVM或者基于LLVM的Arm Compiler 6下,神奇的一幕发生了:
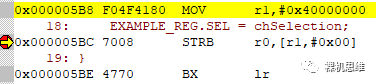
注意,这里Arm Compiler 6使用了跟Arm Compiler 5一样的优化等级(-O1),可见原本的5条指令变成了3条,这里逐条解释如下:
MOV r1,#0x40000000 ; 将地址值 0x40000000 存入r1STRB r0,[r1,#0x00] ; 将 r1 当作指针变量,写入r2中的BYTE到目标地址BX lr ; 返回上一级函数
等一等?且不论之前的“读改写”被成功的“优化掉了”(这个是没有问题的,因为原本的寄存器定义中,我们就没有给出剩下28bit的内容,这等于告诉编译器我们对这部分值是不在乎的,所以这里编译器也没有对剩下的28bit做“读改写”保护),
为什么uint32_t所明确标记的word操作被替换成了byte操作??
我volatile白加了么?说好的不会优化呢?
编译器你怎么不按套路出牌?
难道位域在Arm Compiler 6不能使用了么?——万一我的寄存器是只支持WORD大小访问的怎么办?
这是编译器的bug么?实锤了么?
Arm Compiler 6果然是垃圾么?果然还是armcc大法好!
先别急,我们再来看看定义本身:
typedef struct { volatile uint32_t SEL : 8;} example_reg_t
注意到没有?这里volatile只覆盖了位域SEL,也就是说我们其实只告诉编译器uint32_t中只有低8位是volatile的(只有一个字节是volatile的)——换句话说:“对uint32_t中的第一个字节的访问是不允许优化的”,而其它部分我们没有规定。这是不是意味着,LLVM和Arm Compiler 6编译器特别较真,它觉得我们本意就是告诉它“要以byte的形式去访问一个uint32_t整形的第字节”呢?而且还“不允许优化”。
为了验证这个想法,我们将剩下的部分补齐:
typedef struct { volatile uint32_t SEL : 8; volatile uint32_t : 24;} example_reg_t
重新编译工程,生成代码如下:
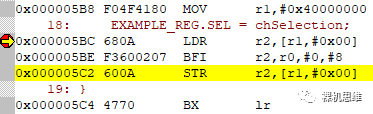
果然,不仅读改写回来了,针对寄存器访问的大小也乖乖变回了uint32_t。
【玄学说法】“Arm Compiler 6(armclang)比 Arm Compiler 5 不可靠、容易生成错误的代码”
【实际情况】Arm Compiler 6比Arm Compiler 5在语法理解上更严格,而Arm Compiler 5在语法理解上更宽松,并且隐含了一些编译器自己的“私货”,大家只不过是先入为主,早已习惯了armcc而已。
【后记】
armcc并不比Arm Compiler 6更可靠,实际上,作为一个已经停止维护的编译器 armcc拥有众多隐藏的天坑,后面有机会我将向大家展示几个匪夷所思的armcc编译器bug,到时候就问你们怕不怕
