动态生成掩膜预测网络生成模型CondInst,助力FCN重夺实例检测颠峰
将门创投实例分割是计算机视觉领域的基础任务,需要算法预测出图像中每个实例的掩膜和对应的分类标签。Mask R-CNN作为一种性能优异的算法,在实例分割领域取得了巨大成功,这种两阶段的方法主要依赖于ROI操作来获取最终的实例掩膜。
而在这篇文章中,作者从全新的角度解决了实例分割问题,来自澳大利亚阿德莱德大学的研究人员在实例条件下提出了动态实例生成的网络模型,代替了先前逐个实例的ROI区域作为预测的输入。
这种全卷积网络消除了对于ROI区域测裁剪操作和特征配准方法,其次由于动态生成的条件卷积大幅提升了网络容量使得mask分支变得非常紧凑,推理速度得到了大幅度提升。实验表明这种方法无需更长时间的训练,在COCO数据集上取得了比Mask R-CNN更好的结果,同时在精度和速度上都得到了明显提升。

实例分割
Mask R-CNN是近几年来实例分割领域非常重要的突破,它使用了Faster R-CNN来为每个实例预测边界框,而后针对每个实例利用ROIAlign操作对在特征图中进行ROI区域裁剪,最后利用紧凑的全卷积网络来对每一个实例的掩膜进行预测。
然而这种基于ROI的方法也有着诸多需要克服的困难:
首先ROI一般都是和图像坐标轴对齐的边框,当遇到非常规不规则物体时框中就会包含较多的背景或者其他实例的部分。虽然可以通过旋转ROI解决这一问题,但随之而来是更为复杂的计算代价和处理流程;其次为了区分前景和背景或者其他杂乱的实例,mask端需要堆叠更多的卷积层来获取更大的感受野,这使得计算量大幅增加;第三由于ROI尺寸各不相同,为了有效利用批(batch)处理计算它们会被重置为相同的大小,这会限制大范围实例的分辨率。
在计算机视觉领域与实例分割最相近的要数语义分割了,全卷积网络FCN在这一任务上取得了巨大的成功。此外FCN同时也在其他逐像素的预测任务上表现优异,像图像去噪、超分辨这类底层图像处理任务、光流估计和边缘检测这类中级任务,单发目标检测、单目深度估计和目标计数这类高级任务都有着FCN的贡献。但在实例分割任务中几乎所有的纯粹FCN方法都没有达到最先进的水平。究竟是什么原因让强大的FCN在实例分割中败下阵来呢?
研究人员发现主要的问题在于,网络对于同一张图像需要针对不同类别预测出不同的掩膜,这会让FCN陷入两难的境地。例如针对两个人A和B,在图像中具有相同的外观和形状特征,但在预测A的掩膜时网络需要将B视为背景,这会让网络陷入到一定程度的迷茫中。所以ROI才需要将目标区域特征图剪切出来。
本质上来讲,实例分割网络需要两种类型的信息:外观形状特征信息用于确定目标类别、位置信息用于从同一类中区分出不同的实例。基于ROI的方法都隐式地编码了目标实例的位置信息。而这篇文章的方法则探索对对于实例位置敏感的卷积层来尝试解决目标位置信息问题。
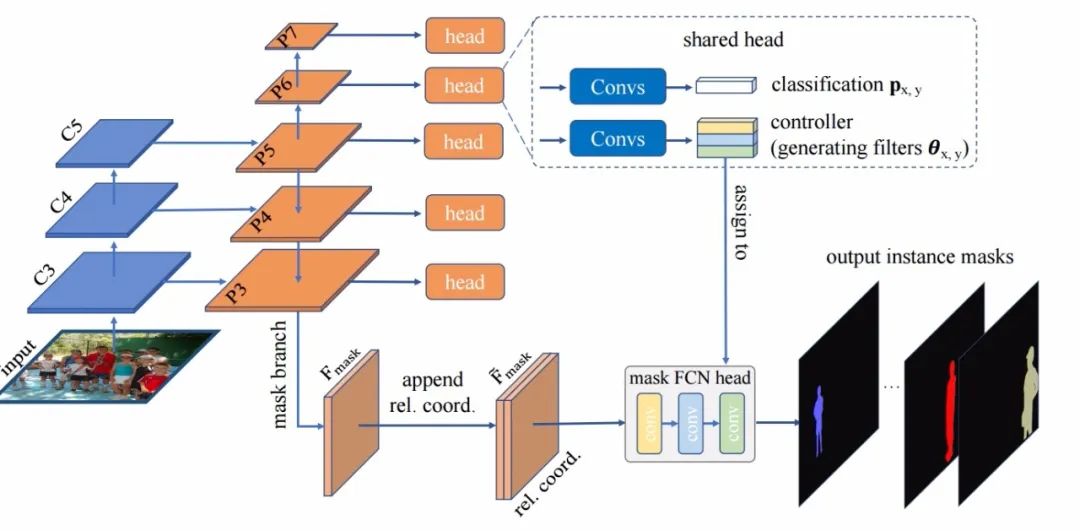
基于这样的考量,研究人员提出了新的解决方法,来代替标准的、由一系列固定权重滤波器组成的ConvNet来作为实例预测端针对所有实例进行处理,利用了一种参数基于待预测实例自适应的网络结构来进行预测。在动态滤波器和条件卷积的启发下,控制子网络会针对每一个实例动态生成mask FCN的网络参数(也就是基于带预测实例的中心区域来生成),随后这些参数实例化为mask FCN用于预测对应实例的掩膜。
其中的思想在于网络参数能够编码实例的特征、并仅激活这一实例的像素,巧妙地避开了前面提到的问题。得到的条件mask端作用于整个特征图免去了获取ROI的操作。这一方法也许在有的人看来会带来非常多的网络参数(由于实例的数量很多),但研究人员巧妙地利用了动态生成的滤波器来构建紧凑的FCN mask预测端,在提高性能的同时,大幅度减少了计算复杂性。
CondInst
实例分割模型的目标在于通过输入图像为图中的实例预测出对应的掩膜,实例数量的不确定对于传统的FCN来说十分困难。本文工作的核心在于,针对图中待处理的K个实例,模型会动态生成K个不同的掩膜处理端,每个掩膜处理分支将目标实例的特征包含在了其参数中。当其作用于特征图时仅仅会激活实例上的像素用于掩膜预测。下图显示了模型的主要架构:
1 2 下一页>
