58集团 x DorisDB:全面升级数据分析能力,满足多场景业务分析需求
58集团是中国互联网生活服务领域的领导者,旗下有国内最大的生活服务平台,覆盖各类业务场景,例如车业务、房产业务、本地服务、招聘业务、金融业务等等。
随着业务的高速发展,越来越多的分析需求涌现,例如:安全分析、商业智能分析、数仓报表等。这些场景的数据体量都较大,对数据分析平台提出了很高的要求。为了满足这些分析型业务的需求,DBA团队从2021年初就开始调研各类分析型数据库,其中包括DorisDB、TiFlash、ClickHouse等,评测他们的性能及功能。
总体评测下来,DorisDB表现全面,在单表/多表查询性能、物化视图及SQL支持等方面能力都契合集团业务需求。目前,我们已经落地了两套DorisDB集群,还有1-2套正在测试阶段,后续会进行进一步推广和落地更多应用。
一、评测信息
我们从两个方面来评测以上这些分析型数据库:一个是功能,一个是性能。每种数据库都有各自的特点。
1.功能方面

2.性能方面
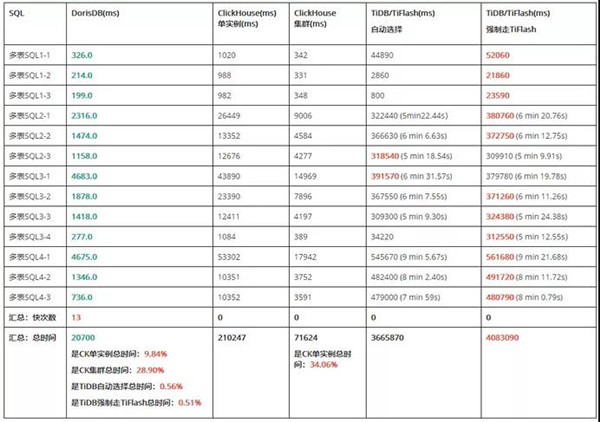
2021年初,我们完整对比过3种数据库的性能,包括TiFlash(4.0.10)、ClickHouse(20.3.8.53)、DorisDB(1.11.0)单表及多表join的性能情况。TiDB5.0的TiFlash已经支持MPP,此处为4.0版本,无MPP。
测试使用业界流行的Star Schema Benchmark星型模型测试集。结论如下:
·单表/多表查询,DorisDB总体时间均最短。
·单表查询:DorisDB最快次数最多,ClickHouse次之。
·多表查询:DorisDB所有执行均最快。
关于TiDB/TiFlash
·TiDB/TiFlash总体时间单表/多表查询均最长。
·TiDB执行计划多数走TiKV,导致执行时间长,且数据量越多,执行时间越长。
·TiDB强制走TiFlash,单表多数提速多,多表多数变慢,但4.0.10版本的执行计划多数不走。
关于Clickhouse
·ClickHouse多表查询需要更改SQL,使类型一致才可以,且字段名、表名区分大小写。
·ClickHouse单机性能强悍,性价比较高。
·ClickHouse大单表查询方式效率好,多表关联效率降低明显。
关于DorisDB
·DorisDB单表和多表关联查询速度都非常快。
【单表查询结果】

【多表关联查询结果】
二、业务需求及应用
1.安全分析相关业务
每天,内部服务器上的各类操作和运行情况,是内部安全人员比较关心的。但是服务器上每天有大量的信息,如何能快速收集落地、统一实时分析,是这个数据分析场景面临的挑战。具体来说,安全分析业务需要应对以下情况:
·写入数据量大,每天大约几亿的数据需要落地;
·实时快速的分析支持,例如:最近15分钟,机器信息的情况是怎样的;
·需要定期进行数据清理;
·数据量不断累积,数据总量规模增长快。
综合评估后,我们选择了DorisDB来支持安全分析相关业务。在使用初期,我们使用了DorisDB的明细模型(即保留所有历史数据),20天左右,数据行数总量就800亿+了,磁盘空间占用8T左右,由于明细数据量庞大导致查询性能也受到影响。
后与内部研发人员讨论,业务分析并不需要详细的历史明细,数据按照指定时间粒度进行聚合汇总即可。便将数据模型改成聚合模型,设置日期、小时和15分钟三个时间维度,指标数据按照这个级别的时间维度进行聚合,聚合后每天新增的数据在10亿左右,数据量降低了75%,查询性能也得到大幅提升。且采用kafka+routine load的方式在DorisDB中进行导入聚合,避免了引入冗余的组件,统一了技术栈。
2.DBA内部业务
MySQL中间件,我们使用的ProxySQL,ProxySQL支持展示SQL情况。但是操作较为繁琐,每次需要重置,才重新开始统计。如何分析指定时间的SQL情况,是困扰我们的另一问题。
每个ProxySQL有自己的全日志,我们可以分析全日志来获取需要的信息。第一个架构方案,我们想到了使用ES,ProxySQL全日志–>Filebeat采集–>Kafka–>Logstash–>ES。但是实际使用中,发现虽然可以查看流水,但是分析时就比较麻烦,不如写SQL的方便。
后来架构又改成了 ProxySQL全日志–>Filebeat采集–>Kafka–>DorisDB,这样就可以进行快速分析了。
另一个问题,因为线上的ProxySQL的日志量特别大,不能所有集群都开,我们设置了可以选择开启,这样有需要的集群才进行分析。降低存储的压力。
举例:分析某30分钟某集群的SQL执行情况,按照次数排序,查询很快。

除了上述两个场景之外,DorisDB还被用在了销售使用的报表系统等场景中,包含实时数据分析等业务场景,共50+张表,占用约100T存储空间,查询并发量100-500+。
三、系统运维
1.数据接入
DorisDB支持的数据导入方式很丰富,例如本地文件、HDFS、Kafka(支持csv、json格式)、外表、批量SQL等。数据接入时有以下需要注意的问题:
·HDFS导入需要提供Namenode的信息,有些不方便提供就支持不了。
·外表模式,创建外表后,可以使用insert into select的方式,循环导入到DorisDB的本地表,能比较方便的从MySQL、TiDB导入数据。
·日常最常用的是Kafka的Json格式的数据,需要开发提供:
··表字段、字段类型及模型(明细模型,聚合模型和更新模型)。
··Kafka信息:kafka_broker_list,kafka_topic,client.id等。
·Kafka的方式,DBA创建表及导入任务就可以导入数据了;日常需要注意的是:最好写个小工具,查看下Kafka的数据信息,然后指明字段,这样来保证成功率。
·查看导入任务:SHOW ROUTINE LOADG;关注Statistic,ErrorLogUrls。
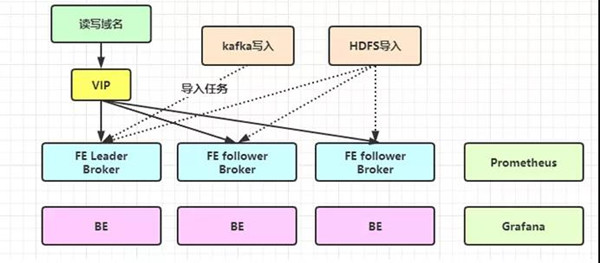
2.集群架构
目前为单套集群,3个FE,3个BE,Broker按需建立,搭建1套监控(Prometheus+Grafana),推荐使用kafka来接入数据。
3.运维及自动化
因为DorisDB标准版无管理组件,需要DBA自己实现:
·标准制定,例如:运维标准、开发接入标准等;
·自动化部署;
·自动化扩缩容;
·自动化升级;
·拓扑展示、登录;
·搭建开源监控;
·自己实现报警,例如存活报警、性能报警;
·相关运维报表,例如表大小、集群磁盘使用情况、流量情况、SQL情况等。
目前我们自己已经实现了部分运维规范的制定,例如集群端口、目录、拓扑架构等,并开发了拓扑工具:qdorisdb,可以查看所有集群、指定集群、登录、展示监控节点信息等。
后期我们会开发相关自动化管理工具,并整合至我们内部的CDB平台,开发相关报表、工单等,方便开发人员使用。
【查看指定集群拓扑】:

【查看所有集群】:

4.服务器
当前我们使用如下机器进行部署,后期会考虑将FE节点使用虚拟机部署。

四、发现的问题及注意事项
·如果想混合部署,需要提前计划好端口,集群间需要有一定间隔;
·DorisDB升级比较快,如果遇到bug可以咨询官方,及时升级避开;
·查询报错:2021-05-09 11:38:56-WARN
com.mysql.jdbc.PacketTooBigException:Packet for query is too large(1095400>1048576).You can change this value on the server by setting the max_allowed_packet’variable;
··处理:set global max_allowed_packet=102410248;
·账号授权跟MySQL不同,需要注意;
·标准版的周边较少,希望能不断丰富,让更多的人用起来;
·Json格式数据导入,字段没法复用,推荐官方添加上,例如:求最大最小时间,需要开发写入Kafka两个时间字段,无法复用一个;
·导入数据需要一定的调试经验,例如Kafka,可以自己写个工具,查看下Kafka里面的数据,再进行测试;
五、场景及定位
DorisDB是优秀的分析型数据库,可以满足多种数据分析场景的需求。但还有不少业务场景需要用其他数据库来服务,目前58DBA提供了多种数据库,方便业务方根据自身的场景进行选择。

总结
目前,我们已经落地了两套DorisDB集群,还有1-2套正在测试阶段,后续会进行进一步推广和落地更多应用。最后,十分感谢DorisDB鼎石科技团队专业的支持服务,希望我们能一起把DorisDB建设得更好。(作者:刘春雷 负责58同城MySQL、TiDB数据库、DorisDB的运维工作,主要从事数据库自动化、平台化的建设)
