机器学习模型:拟合神经网络和预测结果可视化
拓端数据科技摘要:神经网络一直是迷人的机器学习模型之一,不仅因为花哨的反向传播算法,而且还因为它们的复杂性(考虑到许多隐藏层的深度学习)和受大脑启发的结构。
神经网络并不总是流行,部分原因是它们在某些情况下仍然存在计算成本高昂,部分原因是与支持向量机(SVM)等简单方法相比,它们似乎没有产生更好的结果。然而,神经网络再一次引起了人们的注意并变得流行起来。在这篇文章中,我们将拟合神经网络,并将线性模型作为比较。
一 数据集
波士顿数据集是波士顿郊区房屋价值数据的集合。我们的目标是使用所有其他可用的连续变量来预测自住房屋(medv)的中值。首先,我们需要检查是否缺少数据点,否则我们需要修复数据集。apply(data,2,function(x)sum(is.na(x)))然后我们拟合线性回归模型并在测试集上进行测试。index < - sample(1:nrow(data),round(0.75 * nrow(data))) MSE.lm < - sum((pr.lm - test $ medv)^ 2)/ nrow(test)
该sample(x,size)函数简单地从向量输出指定大小的随机选择样本的向量x。
二 准备拟合神经网络
在拟合神经网络之前,需要做一些准备工作。神经网络不容易训练和调整。作为第一步,我们将解决数据预处理问题。
因此,我们在继续之前分割数据:maxs < - apply(data,2,max) scaled < - as.data.frame(scale(data,center = mins,scale = maxs - mins))train_ < - scaled [index,]test_ < - scaled [-index,]
请注意,scale返回需要强制转换为data.frame的矩阵。
参数据我所知,虽然有几个或多或少可接受的经验法则,但没有固定的规则可以使用多少层和神经元。通常,如果有必要,一个隐藏层足以满足大量应用程序的需要。就神经元的数量而言,它应该在输入层大小和输出层大小之间,通常是输入大小的2/3
该hidden参数接受一个包含每个隐藏层的神经元数量的向量,而该参数linear.output用于指定我们是否要进行回归linear.output=TRUE或分类linear.output=FALSE
Neuralnet包提供了绘制模型的好工具:plot(nn)
这是模型的图形表示,每个连接都有权重:
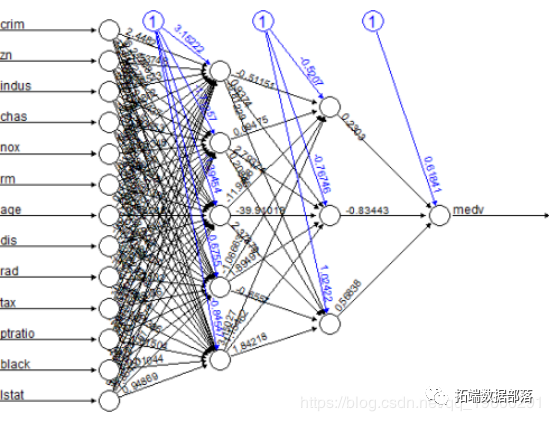
黑色线条显示每个层与每个连接上的权重之间的连接,而蓝线显示每个步骤中添加的偏差项。偏差可以被认为是线性模型的截距。
三 使用神经网络预测medv
现在我们可以尝试预测测试集的值并计算MSE。 pr.nn < - compute(nn,test _ [,1:13])
然后我们比较两个MSE显然,在预测medv时,网络比线性模型做得更好。再一次,要小心,因为这个结果取决于上面执行的列车测试分割。下面,在视觉图之后,我们将进行快速交叉验证,以便对结果更有信心。
下面绘制了网络性能和测试集上的线性模型的第一种可视方法输出图
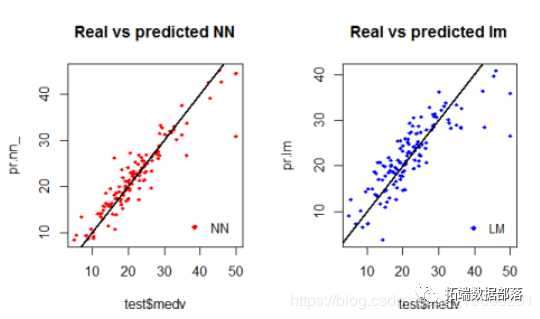
通过目视检查图,我们可以看到神经网络的预测(通常)在线周围更加集中(与线的完美对齐将表明MSE为0,因此是理想的完美预测),而不是由线性模型。下面绘制了一个可能更有用的视觉比较:
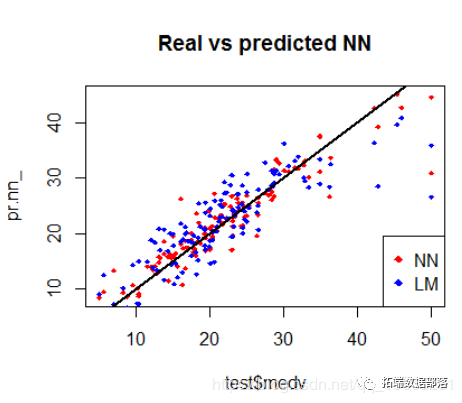
交叉验证交叉验证是构建预测模型的另一个非常重要的步骤。虽然有不同类型的交叉验证方法 然后通过计算平均误差,我们可以掌握模型的运作方式。我们将使用神经网络的for循环和线性模型cv.glm()的boot包中的函数来实现快速交叉验证。
据我所知,R中没有内置函数在这种神经网络上进行交叉验证,如果你知道这样的函数,请在评论中告诉我。以下是线性模型的10倍交叉验证MSE:
lm.fit < - glm(medv~。,data = data)
请注意,我正在以这种方式分割数据:90%的训练集和10%的测试集以随机方式进行10次。我也正在使用plyr库初始化进度条,因为我想要密切关注过程的状态,因为神经网络的拟合可能需要一段时间。过了一会儿,过程完成,我们计算平均MSE并将结果绘制成箱线图
cv.error10.3269799517.640652805 6.310575067 15.769518577 5.730130820 10.520947119 6.1211608406.389967211 8.004786424 17.369282494 9.412778105
上面的代码输出以下boxplot:
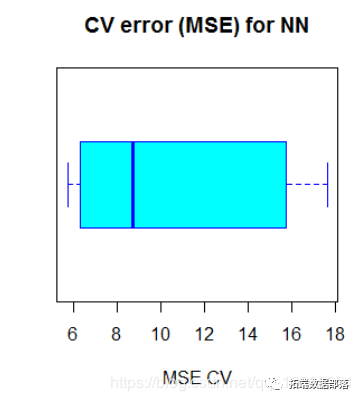
神经网络的平均MSE(10.33)低于线性模型的MSE,尽管交叉验证的MSE似乎存在一定程度的变化。这可能取决于数据的分割或网络中权重的随机初始化。
四 模型可解释性的最后说明
神经网络很像黑盒子:解释它们的结果要比解释简单模型(如线性模型)的结果要困难得多。因此,根据您需要的应用程序类型,您可能也想考虑这个因素。此外,正如您在上面所看到的,需要格外小心以适应神经网络,小的变化可能导致不同的结果。
