如何用Python抓取上海美团火锅的数据?
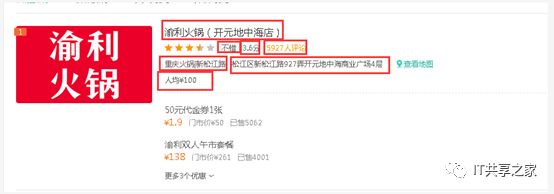
Python进阶学习交流最近有个小伙伴在群里问美团数据怎么获取,而且她只要火锅数据,她在上海,只要求抓上海美团火锅的数据,而且要求也不高,只要100条,想做个简单的分析,相关的字段如下图所示。
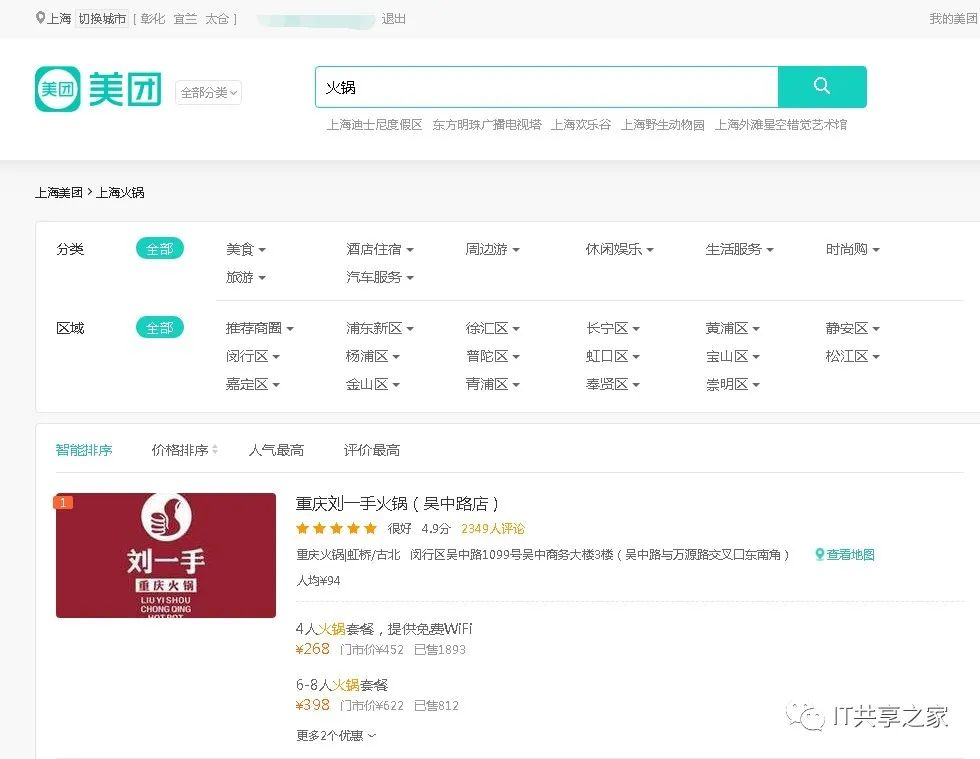
乍一看,这个问题还真的是蛮难的,毕竟美团也不是那么好抓,什么验证码,模拟登陆等一大堆拂面而来,吓得小伙伴都倒地了。
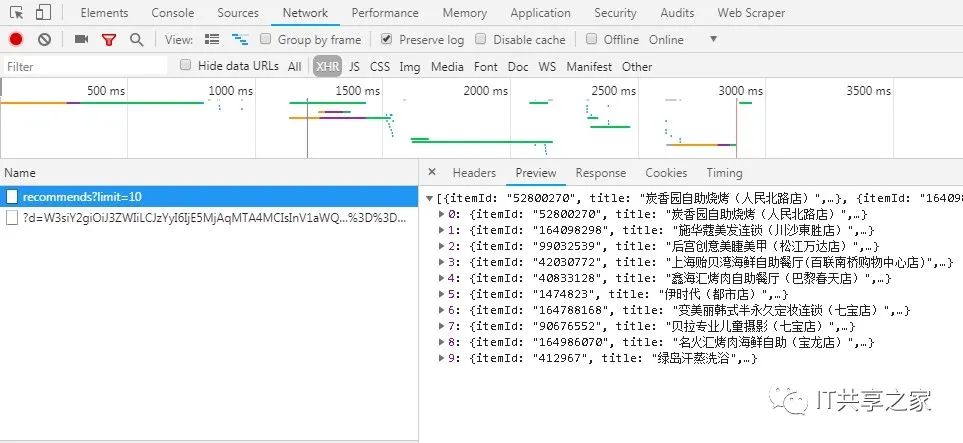
通过F12查看,抓包,分析URL,找规律,等等操作。
不过白慌,今天小编给大家介绍一个小技巧,另辟蹊径去搞定美团的数据,这里需要用到抓包工具Fiddler。讲道理,之前我开始接触网络爬虫的时候也没有听过这个东东,后来就慢慢知道了,而且它真的蛮实用的,建议大家都能学会用它。这个工具专门用于抓包,而且其安装包也非常小,如下图所示。

接下来,我们开始进行抓取信息。
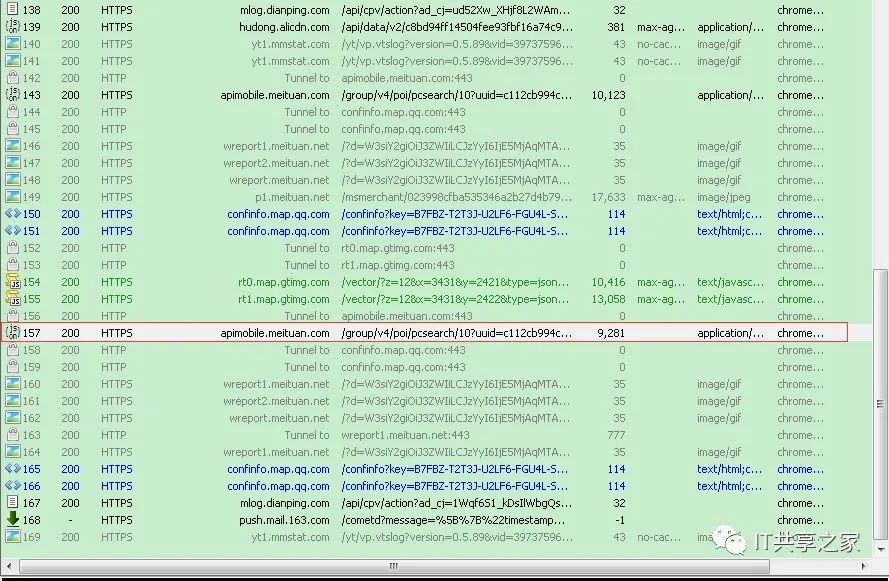
1、在Fiddler的左侧找到meituan网站的链接,如下图所示。链接的左边返回的response(响应)的文件类型,可以看到是JSON文件,尔后双击这一行链接。
1 2 3 下一页>
