BEBLID:减少执行时间的同时提高图像匹配精度!
磐创AIOpenCV发行版4.5.1包含了BEBLID,这是一个新的本地特性描述符。opencv4.5.1中最令人兴奋的特性之一是BEBLID(Boosted effective Binary Local Image Descriptor),它是一种新的描述符,能够在减少执行时间的同时提高图像匹配精度!本文将向你展示一个具体的例子,所有源代码都存储在此GitHub存储库中:https://github.com/iago-suarez/beblid-opencv-demo/blob/main/demo.ipynb在这个例子中,我们将通过一个视角的改变来匹配这两个图像:

首先,确保安装了正确版本的OpenCV。
在你喜爱的环境中,你可以使用以下工具安装和检查OpenCV Contrib版本:pip install "opencv-contrib-python>=4.5.1"
python
>>> import cv2 as cv
>>> print(f"OpenCV Version: {cv.__version__}")
OpenCV Version: 4.5.1
在Python中加载这两个图像所需的代码是:import cv2 as cv
# Load grayscale images
img1 = cv.imread("graf1.png", cv.IMREAD_GRAYSCALE)
img2 = cv.imread("graf3.png", cv.IMREAD_GRAYSCALE)
if img1 is None or img2 is None:
print('Could not open or find the images!')
exit(0)
为了评估我们的图像匹配程序,我们需要在两幅图像之间进行正确的几何变换。这是一个称为单应性的3x3矩阵,当我们将第一个图像中的一个点(在齐次坐标中)相乘时,它将返回第二个图像中该点的坐标。让我们加载它:# Load homography (geometric transformation between image)
fs = cv.FileStorage("H1to3p.xml", cv.FILE_STORAGE_READ)
homography = fs.getFirstTopLevelNode().mat()
print(f"Homography from img1 to img2:{homography}")
下一步是检测图像中容易在其他图像中找到的部分:局部图像特征。在这个例子中,我们将用一个快速可靠的探测器ORB来检测角点。ORB通过比较不同尺度下的角点来检测强角点,并利用FAST或Harris响应来选择最佳的角点,同时它还使用局部分块的一阶矩来确定每个角点的方向。允许在每个图像中检测最多10000个角点:detector = cv.ORB_create(10000)
kpts1 = detector.detect(img1, None)
kpts2 = detector.detect(img2, None)
在下图中,你可以看到用绿点标记的检测响应最强的500个角点特征:
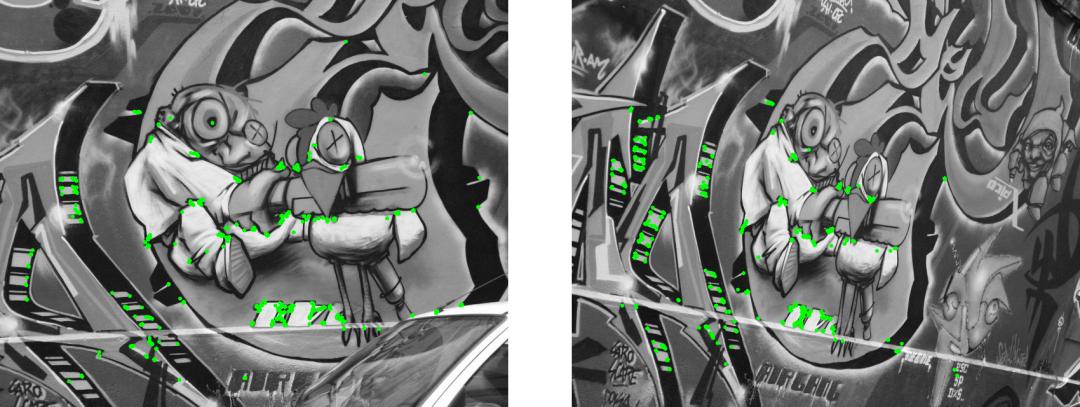
现在使用该方式来表示这些关键点,我们可以在另一幅图中找到它们,这一步称为描述,因为每个角点附近的局部分块中的纹理由来自图像上不同操作的数字向量表示(即描述)。有很多描述符,但如果我们想要一些准确的东西,即使在移动电话或低功耗设备上也能实时运行,OpenCV有两种重要的方法:ORB(Oriented FAST and Rotated BRIEF):一个经典的替代品,已经有10年的历史了,效果相当不错。BEBLID(Boosted effective Binary Local Image Descriptor):2020年推出的一种新的描述符,在多个任务中被证明可以提高ORB。由于BEBLID适用于多种检测方法,因此必须将ORB关键点的比例设置为0.75~1。# Comment or uncomment to use ORB or BEBLID
descriptor = cv.xfeatures2d.BEBLID_create(0.75)
# descriptor = cv.ORB_create()
kpts1, desc1 = descriptor.compute(img1, kpts1)
kpts2, desc2 = descriptor.compute(img2, kpts2)
现在是时候匹配两幅图像的描述符来建立对应关系了。让我们使用暴力算法,基本上比较第一个图像中的每个描述符与第二个图像中的所有描述符。当我们处理二进制描述符时,比较是用汉明距离来完成的,也就是说,计算每对描述符之间不同的位数。这里还使用了一个称为比率测试的小技巧,它不仅确保描述符1和2彼此相似,而且没有其他描述符像2那样接近1。matcher = cv.DescriptorMatcher_create(cv.DescriptorMatcher_BRUTEFORCE_HAMMING)
nn_matches = matcher.knnMatch(desc1, desc2, 2)
matched1 = []
matched2 = []
nn_match_ratio = 0.8 # Nearest neighbor matching ratio
for m, n in nn_matches:
if m.distance < nn_match_ratio * n.distance:
matched1.append(kpts1[m.queryIdx])
matched2.append(kpts2[m.trainIdx])
因为我们知道正确的几何变换,所以让我们检查有多少匹配是正确的(inliers)。如果图2中的点和从图1投射到图2的点距离小于2.5像素,我们将认为它是有效的。inliers1 = []
inliers2 = []
good_matches = []
inlier_threshold = 2.5 # Distance threshold to identify inliers with homography check
for i, m in enumerate(matched1):
# Create the homogeneous point
col = np.ones((3, 1), dtype=np.float64)
col[0:2, 0] = m.pt
# Project from image 1 to image 2
col = np.dot(homography, col)
col /= col[2, 0]
# Calculate euclidean distance
dist = sqrt(pow(col[0, 0] - matched2[i].pt[0], 2) + pow(col[1, 0] - matched2[i].pt[1], 2))
if dist < inlier_threshold:
good_matches.append(cv.DMatch(len(inliers1), len(inliers2), 0))
inliers1.append(matched1[i])
inliers2.append(matched2[i])
现在我们在inliers1和inliers2变量中具有正确的匹配项,我们可以使用cv.drawMatches对结果进行定性评估。每个对应点都可以帮助我们完成更高层次的任务,例如单应性估计,透视n点,平面跟踪,实时姿态估计或图像拼接。单应性估计:https://docs.opencv.org/4.5.1/d9/d0c/group__calib3d.html#ga4abc2ece9fab9398f2e560d53c8c9780透视n点:https://docs.opencv.org/4.5.1/d9/d0c/group__calib3d.html#ga549c2075fac14829ff4a58bc931c033d平面跟踪:https://docs.opencv.org/4.5.1/dc/d16/tutorial_akaze_tracking.html实时姿态估计:https://docs.opencv.org/4.5.1/dc/d2c/tutorial_real_time_pose.html图像拼接:https://docs.opencv.org/4.5.1/df/d8c/group__stitching__match.htmlres = np.empty((max(img1.shape[0], img2.shape[0]), img1.shape[1] + img2.shape[1], 3), dtype=np.uint8)
cv.drawMatches(img1, inliers1, img2, inliers2, good_matches, res)
plt.figure(figsize=(15, 5))
plt.imshow(res)

由于很难比较这种定性的结果,所以我们需要一些定量的评价指标,最能反映描述符可靠性的指标是inliers的百分比:
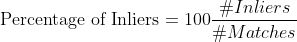
Matching Results (BEBLID)
*******************************
# Keypoints 1: 9105
# Keypoints 2: 9927
# Matches: 660
# Inliers: 512
# Percentage of Inliers: 77.57%
使用BEBLID描述符可以获得77.57%的inliers。如果我们在description单元格中注释BEBLID并取消注释ORB descriptor,结果将下降到63.20%:# Comment or uncomment to use ORB or BEBLID
# descriptor = cv.xfeatures2d.BEBLID_create(0.75)
descriptor = cv.ORB_create()
kpts1, desc1 = descriptor.compute(img1, kpts1)
kpts2, desc2 = descriptor.compute(img2, kpts2)
Matching Results (ORB)
*******************************
# Keypoints 1: 9105
# Keypoints 2: 9927
# Matches: 780
# Inliers: 493
# Percentage of Inliers: 63.20%
总之,用BEBLID替换ORB描述符只需一行代码,就可以将两幅图像的匹配结果提高14%,这对需要局部特征匹配才能工作的更高级别任务有很大收益。
