一文教你使用卷积神经网络进行图像分类
磐创AI介绍卷积神经网络属于深度学习的子域。深度学习中的算法以与人脑相同的方式来处理信息,但其规模很小,因为我们的大脑太复杂了(我们的大脑大约有860亿个神经元)。为什么使用CNN进行图像分类?图像分类通过从图像中提取特征,以观察数据集中的某些模式。由于可训练参数变得非常大,因此使用ANN进行图像分类最终会在计算上造成很高的成本。例如,如果我们有一张50 X 50的猫图像,并且我们想在该图像上训练传统的ANN,以将其分类为狗或猫,则可训练参数变为–(50 * 50)* 100图像像素乘以隐藏层 + 100 偏差+ 2 * 100 输出神经元+ 2 偏差= 2,50,302我们在使用CNN时使用了过滤器,过滤器根据其用途而存在许多不同类型。

不同过滤器及其效果的示例过滤器通过在神经元之间执行局部连接模式来帮助我们利用特定图像的空间局部性。卷积操作是指两个函数的逐点乘法以产生第三个函数,这里一个函数是我们的图像像素矩阵,另一个是我们的过滤器。我们在图像上滑动卷积核,并获得两个矩阵的点积,生成的矩阵称为“激活图”或“特征图”。
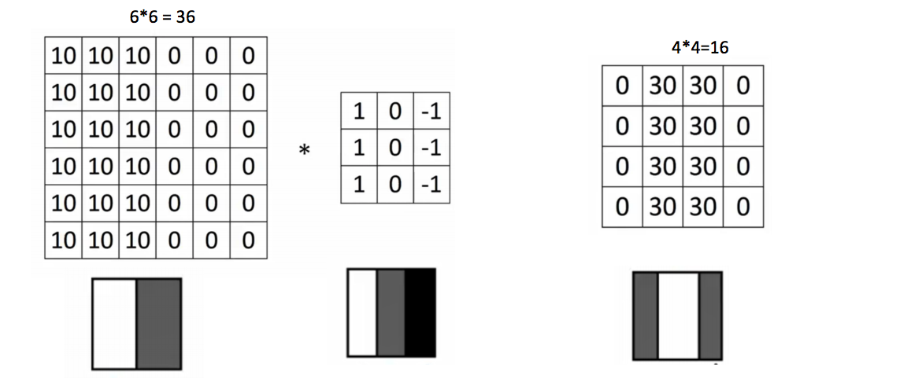
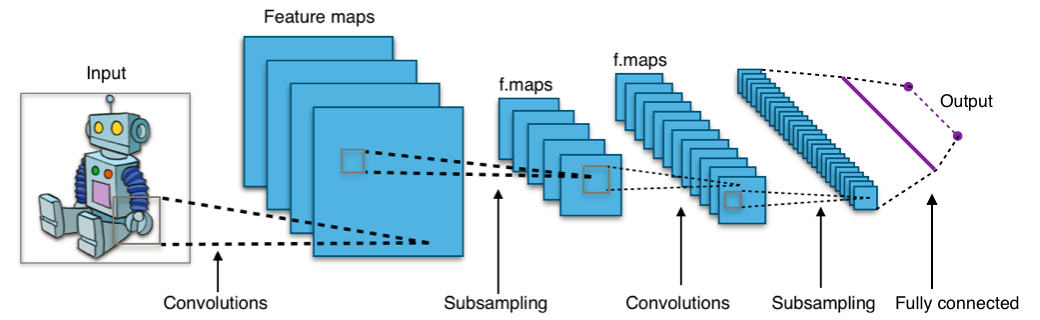
在此处使用垂直卷积核对6X6图像进行卷积有多个卷积层从图像中提取特征,最后从输出层中提取特征。
实用:分步指南我将使用Google Colab,并且已经通过Google Drive连接了数据集,因此,如果使用相同的设置,则我提供的代码应该是可以使用,切记根据你的设置进行适当的更改。步骤1:选择一个数据集选择你感兴趣的数据集,或者你也可以创建自己的图像数据集来解决自己的图像分类问题。在kaggle上可以获取到很多数据集。我要使用的数据集可以在这里找到。
该数据集包含12,500个血细胞增强图像(JPEG),并带有相应的细胞类型标签(CSV)。这4种不同的细胞类型每种大约有3,000张图像,这些图像分为4个不同的文件夹(根据细胞类型)。细胞类型是嗜酸性粒细胞,淋巴细胞,单核细胞和嗜中性粒细胞。这是我们需要的所有库以及导入它们的代码。from keras.models import Sequential
import tensorflow as tf
import tensorflow_datasets as tfds
tf.enable_eager_execution()
from keras.layers.core import Dense, Activation, Dropout, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD, RMSprop, adam
from keras.utils import np_utils
from sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifier
from sklearn import metricsfrom sklearn.utils import shuffle
from sklearn.model_selection import train_test_splitimport matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import os
import cv2
import randomfrom numpy import *
from PIL import Image
import theano
步骤2:准备训练资料集准备我们的数据集进行训练,需要设置路径和创建类别(标签),并调整图像大小。将图像调整为200 X 200path_test = "/content/drive/My Drive/semester 5 - ai ml/datasetHomeAssign/TRAIN"
CATEGORIES = ["EOSINOPHIL", "LYMPHOCYTE", "MONOCYTE", "NEUTROPHIL"]
print(img_array.shape)IMG_SIZE =200
new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))
步骤3:建立训练资料训练的输入数据是一个数组,其中包含了图像像素值和“类别”列表中图像的索引。training = []def createTrainingData():
for category in CATEGORIES:
path = os.path.join(path_test, category)
class_num = CATEGORIES.index(category)
for img in os.listdir(path):
img_array = cv2.imread(os.path.join(path,img))
new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))
training.append([new_array, class_num])createTrainingData()
步骤4:随机整理资料集random.shuffle(training)
步骤5:分配标签和特征这两个列表的这种形状将在使用NEURAL NETWORKS的分类中使用。X =[]
y =[]for features, label in training:
X.append(features)
y.append(label)
X = np.array(X).reshape(-1, IMG_SIZE, IMG_SIZE, 3)
步骤6:标准化X并将标签转换为分类数据X = X.astype('float32')
X /= 255
from keras.utils import np_utils
Y = np_utils.to_categorical(y, 4)
print(Y[100])
print(shape(Y))
步骤7:将X和Y拆分以用于CNNX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 4)
步骤8:定义,编译和训练CNN模型
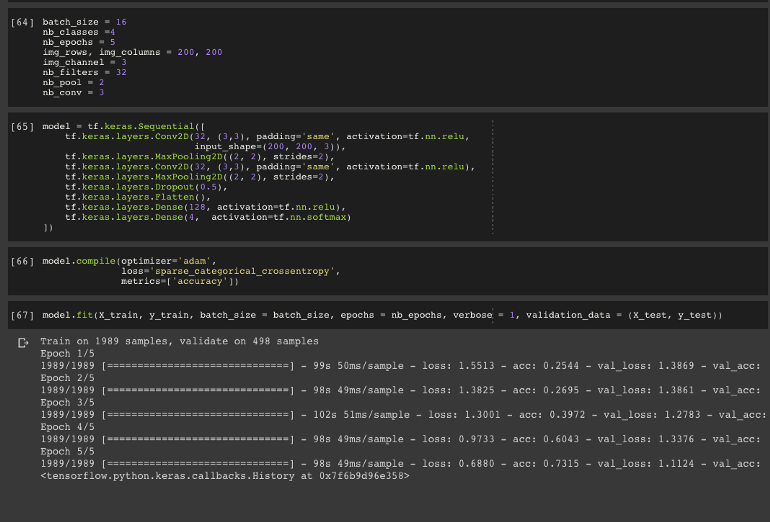
batch_size = 16
nb_classes =4
nb_epochs = 5
img_rows, img_columns = 200, 200
img_channel = 3
nb_filters = 32
nb_pool = 2
nb_conv = 3
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3,3), padding='same', activation=tf.nn.relu,
input_shape=(200, 200, 3)),
tf.keras.layers.MaxPooling2D((2, 2), strides=2),
tf.keras.layers.Conv2D(32, (3,3), padding='same', activation=tf.nn.relu),
tf.keras.layers.MaxPooling2D((2, 2), strides=2),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(4, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
model.fit(X_train, y_train, batch_size = batch_size, epochs = nb_epochs, verbose = 1, validation_data = (X_test, y_test))
步骤9:模型的准确性和得分score = model.evaluate(X_test, y_test, verbose = 0 )
print("Test Score: ", score[0])
print("Test accuracy: ", score[1])

在这9个简单的步骤中,我们准备了卷积神经网络模型并使用这些技能来解决实际问题。你可以在Analytics Vidhya和Kaggle等平台上练习这些技能。你还可以通过更改不同的参数并发现如何获得最佳的准确性和得分来解决问题,可以尝试更改CNN模型中的batch_size,epoch数,甚至添加/删除图层。
