百模大战,谁是下一个ChatGPT?
光锥智能文|光锥智能,作者|周文斌,编辑|王一粟
“不敢下手,现在中国还没跑出来一家绝对有优势的大模型,上层应用没法投,担心押错宝。”投资人Jucy(化名)向光锥智能表示,AI项目看得多、投的少是这段时间的VC常态。
ChatGPT点燃AI大爆炸2个月中,中国一直在等待自己的GPT-3.5。
AI真的冒犯到了打工人。游戏团队替代掉30%的原画师、电商团队用AIGC生成低成本数字人模特、基础程序员也感受到了被降维打击的焦虑......眼看着GPT在国外要将所有领域都重新做一遍的趋势,科技颠覆裹挟着金钱的味道滚滚而来。
于是,除了焦虑的打工人,企业急着用大模型降本增效,创业者急着接入大模型推出新产品,股市急着用ChatGPT概念割韭菜,培训机构更是先赚一波为敬。
衬托之下,反而显得喜欢追逐风口的中国科技巨头们比以往更沉得住气。
果然,周期使人成长,公司也是。
终于,众望所归、望眼欲穿、姗姗来迟,4月第二周,中国也迎来了新一代大模型的密集发布。
·继通义千问开放测试4天后,张勇在接手阿里云后首次亮相,宣布所有阿里产品未来将接入“通义千问”大模型,进行全面改造;
·商汤科技在10日的技术交流会上,演示了“日日新”大模型的能力:对话、AI绘画、编程、数字人,第二天开盘大涨9%;
·华为盘古大模型在8日低调亮相,但并于10日发布新产品;
·明星创业者王小川公开亮相,携手搜狗老搭档茹立云正式开启AI创业的新征程,将在下半年推出百川智能的大模型;
·毫末发布首个自动驾驶大模型DriveGPT雪湖·海若,把人类反馈强化学习引入到驾驶领域。
就连游戏公司昆仑万维也赶来凑热闹,宣称“中国第一个真正实现智能涌现”的国产大语言模型将于17日启动邀请测试,但随后被媒体质疑其借热点炒作股价。
热热闹闹、真真假假,大模型一时竟然有点乱花渐欲迷人眼。中国的大模型怎么就一下子如雨后春笋般都冒了出来?如果不重复造轮子,大家还能干点什么?
虽然是摸着Open AI过河,但中国大模型也都迈入了无人区。
01 涌现之前:亦步亦趋,又分道扬镳
如果要为AI大模型找一个时间节点,2019年应该是关键的一个。
这一年2月,远在大洋彼岸的OpenAI推出了GPT-2,恰好也是这个时间点,微软慷慨的投入了10亿美元,让OpenAI从“非营利性”组织变成了“盈利上限”组织。
大概在一个月之后,太平洋的另一边,百度发布了ERNIE1.0,成为中国第一个正式开放的预训练大模型。
但这种第一其实有很多,比如华为的盘古大模型,业界首个千亿参数的中文语言预训练模型;比如阿里的M6,中国首个千亿参数多模态大模型;再比如腾讯HunYuan,国内首个低成本、可落地的NLP万亿大模型.....
总之,只要定语加的足够多,就总能在某个领域当第一。那段时间,从硅谷到北京西二旗、再从五道口到上海临港,包括华为、阿里、腾讯、商汤在内,凡是有能力的企业,都开始涉足AI大模型的相关研究。
但中国第一波AI大模型的“涌现”却是在两年之后。
2021年,曾任职过微软亚洲工程院院长、后被雷军亲自邀请到金山接替求伯君任CEO的张宏江,牵头成立的智源研究院发布“悟道1.0”,包括国内首个面向中文的NLP大模型、首个中文通用图文多模态大模型和首个具有认知能力的超大规模预训练的模型等等。
智源成立于2018年,也就是OpenAI发布GPT-1.0的前五个月,作为北京市和科技部牵头成立,并集合学界和头部科技企业资源的研究机构,智源其实是中国早期探索AI大模型的一个代表。
可以说,“悟道1.0”其实为中国后来所有AI大模型的一个样本。除此之外,智源研究院还为中国构建了大规模预训练模型技术体系,并建设开放了全球最大中文语料数据库WuDaoCorpora,为后来其他企业发展AI大模型打下了基础。
也正是在“悟道1.0”之后,中国大模型开始出现井喷的状态。
2021年,华为基于昇腾AI与鹏城实验室联合发布了鹏程盘古大模型。2022年,阿里发布了“通义”大模型系列,腾讯发布混元AI大模型......
在中国AI大模型如雨后春笋般涌现的同时,国外的AI大模型也走到了从量变到质变的节点。
2022年11月,OpenAI发布了基于GPT-3.5的ChatGPT,彻底打开了人工智能的魔盒,然后就是席卷全球的AI 2.0浪潮。
事实上,如果以2018年GPT-1发布为节点,中国的AI大模型的发展与国外的发展脉络一直都亦步亦趋,但ChatGPT为什么并没有出现在中国?
这其实和国内外AI大模型两种不同的发展路径有关。
从目前国外具有代表性的AI大模型产品来看,比如ChatGPT、Midjourney、Notion AI或者Stable diffusion等等,都是以C端用户为基础的产品。
而反观国内,目前大模型的主要应用场景的都在B端。
比如阿里的“通义”大模型的典型应用场景包括电商跨模态搜索、AI辅助设计、开放域人机对话、法律文书学习、医疗文本理解等等,而腾讯的HunYuan-NLP-1T大模型则应用在腾讯广告、搜索、对话等内部产品落地,或者像商汤的大模型,为自动驾驶、机器人等通用场景任务提供感知和理解能力支持。
之所以选择To B,一个重要的原因是,B端能够更容易进行商业化。
To B的行业特点导致中国的AI大模型并不需要做到非常大的参数规模,甚至于当ChatGPT出来之后,国内的公司讨论的一个重要方向,是如何将已有的大模型规模“做小”,应用到具体的行业上。
所以中国采用谷歌BERT路线的AI大模型会比较多,以更小的参数,做更有效率,更适合垂类的场景。
所以某种程度上,从出生的第一天,中国大模型就带着商业化的任务。

而国外To C的大模型则不同,如ChatGPT的用户在短短两个月就达到一亿,其底层预训练大模型GPT-3.5作为通用大模型,“大”成为参数的一个基本要求。
这在某种程度上促进OpenAI不停为GPT增加参数,然后激发更强大的“涌现”现象,最终实现“大力出奇迹”的ChatGPT。
因此,To B和To C两种完全不一样的发展路径,也将中国和美国的AI大模型引向了两种完全不同的发展方向。
02 不要重复造轮子,但大家都想当轮子
“基建狂魔”的称号在大模型上再次得到验证。
到目前为止,中国已经发布的AI大模型产品已经发布了5个,而这之后,还有5个AI大模型产品正在赶来的路上。
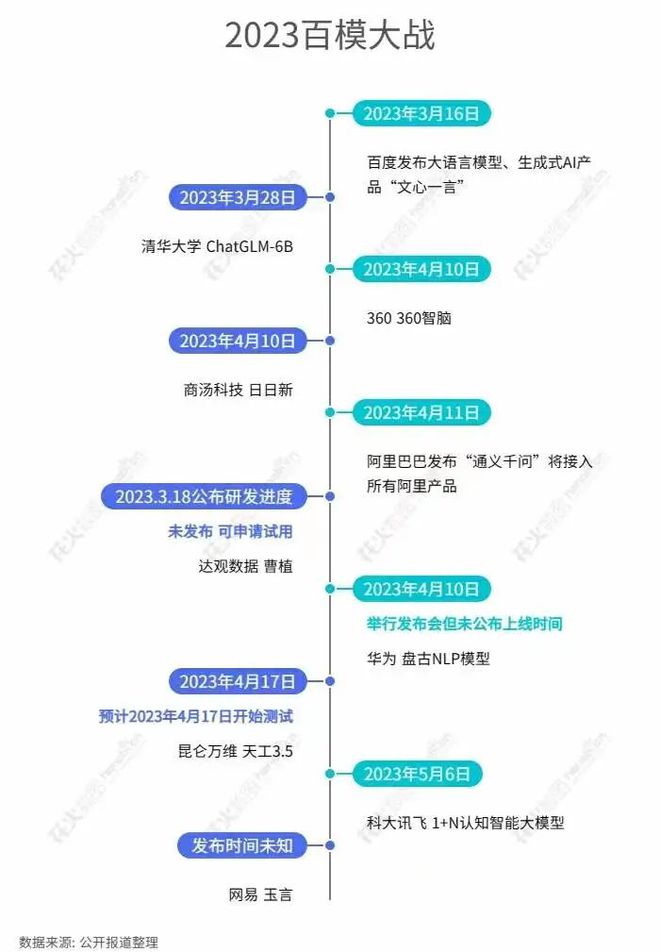
模型大乱斗已经开始。
大部分国内的大模型能力都在GPT-2的水平上,但关注度却远远高于GPT-2推出时,这就造成了一种尴尬的局面——明知道还没有完全准备好,但却不得不积极地在推进模型发布,似乎稍微晚一点就会错过整个市场。
的确,无论是市场还是技术本身,都在要求企业更快地将大模型推向市场。
从技术上讲,越早进入市场就能越早地获得用户的使用数据,进而推动模型优化迭代。从市场角度而言,当国外AI大模型与产业结合带来更高效率的同时,国内企业也存在同样的需求。
比如目前,光锥智能向多个SaaS公司调研发现,几乎都已经接入GPT-3.5,目前在同步测试文心一言中。
而对于推出大模型的企业来说,这个时候抢占市场先机就变得尤为重要。
某头部机构负责AI的投资人告诉光锥智能,“中国现在被排除在ChatGPT生态之外是非常危险的。”
他认为,虽然应用层存在更大的创业机会,但应用层的所有应用却都依赖于大模型而存在。就像PC互联网时代,所有的桌面应用都基于Windows开发,而移动互联网时代所有APP又都基于Android或iOS系统一样,在模型即服务的时代,也需要出现一些“操作系统”级别的底层大模型。
目前国外GPT-4已经明确可以成为这样的存在,但国内还没有相应的大模型出现。因此,在底层大模型的格局还未明朗的情况下,一旦大模型的市场格局发生变化,建立在大模型之上的应用也将付之东流。

这也成为许多投资人不愿意现在就下场的原因,他们想让这个市场再跑一跑,等待一个明确能够成为“操作系统”级别的底层大模型出现。
所以,无论是百度还是阿里,在推出大模型之后,第一件关心的事就是——是否有更多企业能够达成合作。
比如,在2月份明确文心一言推出计划后,百度就开始积极推进不同行业的企业接入文心一言,到3月16日百度发布文心一言时,已有超过650家企业宣布接入文心一言生态。而在4月7日,阿里官宣“通义千问”之后,第一件事也是向企业开放测试邀请。
如今国内的AI大模型正处在竞争“谁能成为底层操作系统”的阶段,各家积极推出自己的大模型,开放内测,引导企业入驻,一个核心目标就是围绕大模型建立起自己的模型生态。
这是大厂能否在下一个时代继续成为大厂的关键。下一个AI时代的船票并不是大模型,而是围绕大模型建立起来的生态。
因此,即便所有人都在口口声声表示不要重复造轮子,不要浪费资源建立一个同样的大模型,但机会当前,所有人都在重复造轮子。
但如今从百度到阿里,再从华为到商汤,底层大模型的战争也才刚刚刚开始,毕竟不只是像腾讯、字节这样的科技巨头,还有像王小川、王慧文、李开复等创业大佬也在虎视眈眈。
王小川、王慧文都先后入驻搜狐网络科技大厦,五道口似乎又恢复了之前的荣光。
毕竟,许多人都感觉到,“这是一次文艺复兴”。
到目前为止,更多具有竞争力的玩家还没有完全下场,但底层大模型的“百团大战”却已经一触即发。
03 AI热“两极化”,中间真空
大模型让AI公司越来越重。
4月10日,商汤在公布“日日新SenseNova”大模型体系的同时,其实还提到另一个关键点,即依托于AI大装置SenseCore实现“大模型+大算力”的研发体系。
为了满足大模型海量数据训练的需求,原本可以轻装上阵的算法公司,开始自己做云,也自建人工智能数据中心(AIDC)。
另一个案例就是毫末,这家自动驾驶公司为了用大模型训练数据,也建了自己的智算中心。
这些垂类的AI巨头和独角兽,之所以要自己做的这么重,最重要的原因之一,就是市面上几乎没有高性能的现成产品可以满足。
近年来,大模型参数量以指数级的速率提升,而数据量随着多模态的引入也将大规模增长,因此就必然会导致对算力需求的剧增。例如,过去5年,超大参数AI大模型的参数量几乎每一年提升一个数量级。过往的10年,最好的AI算法对于算力的需求增长超过了100万倍。
一位商汤员工表示,商汤上海临港AIDC的服务器机柜设计功耗10千瓦~25千瓦,最大可同时容纳4台左右英伟达A100服务器,但普通的服务器机柜普遍设计功耗以5千瓦居多,而单台A100服务器的功耗即高达4.5千瓦左右。
科技巨头就更是如此,每个巨头都希望在自己的生态中形成闭环,一定程度上也是因为整个国内开源的生态不够强大。
目前,大模型产业链大致可以分为数据准备、模型构建、模型产品三个层次。在国外,AI大模型的产业链比较成熟,形成了数量众多的AI Infra(架构)公司,但这一块市场在国内还相对空白。
而在国内,巨头们都有一套自己的训练架构。
比如,华为的模型采用的是三层架构,其底层属于通识性大模型,具备超强的鲁棒性的泛化性,在这之上是行业大模型和针对具体场景和工作流程的部署模型。这种构架的好处是,当训练好的大模型部署到垂类行业时,可以不必再重复训练,成本仅是上一层的5%~7%。
阿里则是为AI打造了一个统一底座,无论是CV、NLP、还是文生图大模型都可以放进去这个统一底座中训练,阿里训练M6大模型需要的能耗仅是GPT-3的1%。
百度和腾讯也有相应的布局,百度拥有覆盖超50亿实体的中文知识图谱,腾讯的热启动课程学习可以将万亿大模型的训练成本降低到冷启动的八分之一。
整体来看,各个大厂之间的侧重点虽然有所不同,但主要特点就是降本增效,而能够实现这一点,很大程度上就是受益于“一手包办”的闭环训练体系。
这种模式在单一大厂内部固然有优势,但从行业角度而言,也存在一些问题。
国外成熟的AI产业链形成了数量众多的AI Infra公司,这些公司有的专门做数据标注、做数据质量、或者模型架构等。
这些企业的专业性,能够让他们在某一个单一环节的效率、成本、质量上都要比大厂亲自下场做得更好。
比如,数据质量公司Anomalo就是Google Cloud和Notion的供应商,它可以通过ML自动评估和通用化数据质量检测能力,来实现数据深度观察和数据质量检测。
这些公司就像汽车行业的Tier 1,通过专业的分工,能够让大模型企业不必重复造轮子,而只需要通过整合供应商资源,就能快速地搭建起自己模型构架,从而降低成本。
但国内在这一方面并不成熟,原因在于:一方面国内大模型的主要玩家都是大厂,他们都有一套自己的训练体系,外部供应商几乎没有机会进入;另一方面,国内也缺乏足够庞大的创业生态和中小企业,AI供应商也很难在大厂之外找到生存的空间。
以谷歌为例,谷歌愿意将自己训练的数据结果分享给它的数据质量供应商,帮助供应商提高数据处理能力,供应商能力提升之后,又会反过来给谷歌提供更多高质量数据,从而形成一种良性循环。
国内AI Infra生态的不足,直接导致的就是大模型创业门槛的拔高。
王慧文刚下场做光年之外的时候曾提出5000万美金的投入,这笔钱其实是李志飞为他算的,具体可以分为2000万美金搞算力,2000万美金找人,1000万美金做数据。这体现出一个直接的问题,如果将在中国做大模型比喻成吃上一顿热乎饭,那必须从挖地、种菜开始。
目前,在AI 2.0的热潮中,一个重要的特点就是“两极化”:最热门的要么是大模型层、要么就是应用层。而类似AI Infra(架构)的中间层,反而有很大的真空。
别都盯着造轮子,能造一颗好的螺丝也很重要。
04 结语:巨头&创新者
王小川和百度的隔空口水战,成为最近大模型混战中一个热闹的插曲。
“高富帅”李彦宏认为,中国基本不会再出OpenAI,用巨头的就可以了。
“直男”王小川说,行业中有些人(李彦宏)对未来的观点从来就没有判断对过,一直活在平行宇宙里。
除了陈年恩怨,这大体上可以看作是巨头和创业者之间的立场对立:巨头都喜欢包揽一切,而创业者则喜欢打破常规。
而科技行业的成功似乎更依仗于创新。毕竟,从打造AlophaGo的DeepMind,到发布ChatGPT的OpenAI,没有一个是从巨头中孵化出来的。
这就是创新者的窘境。
对于科技巨头而言,自己造轮子固然重要,但能找到、孵化出下一个OpenAI又未尝不可呢?
