基于ARM的AWS EC2实例上的PG性能测试
yzsDBAARM处理器在数据中心中的应用一直是一个热门话题,我们很想看看他在PG中表现怎么样。用于测试和评估基于ARM的服务器,其可用性一直是一个主要障碍,当AWS 2018年宣布在他们的云中提供基于ARM的处理器时,转机出现了。但是还不能太过激动,因为很多人认为这是个实验性的东西。我们也很谨慎将它推荐给关键用途,而且在测试时也没太过用心。但是2020年5月Graviton2发布后,可以认真考虑了。我们决定从PG运行角度独立研究实例的价格/性能。
要点:请注意,尽管在x86和arm上比较PG很有吸引力,但这是不正确的。这些测试比较了两个虚拟云中的PG,保护的移动部件不止CPU。我们主要关注基于两种不同体系架构的两个特定AWS EC2实例的性价比。
测试设置
本测试中,选择了两个相似的是,一个是教老的m5d.5xlarge,一个是新型基于Graviton2的m6gd.8xlarge。两个实例都有一个本地”短暂性”存储。使用非常快速的本地驱动可有助于暴露系统其它部分的差异,并避免测试云存储。这些实例并不是完全相同,正如下面看到的,但也非常接近,可以被认为是相同级别。我们使用来自pgdg repo的PG13.1和ubuntu20.04 AMI,小内存和大数据量进行测试。
实例
实例的规范和按需定价,参考Northern Virginia region的定价信息,按目前的挂牌价格,m6gd.8xlarge便宜25%。
Graviton2 (arm) Instance: Instance : m6gd.8xlarge Virtual CPUs : 32 RAM : 128 GiB Storage : 1 x 1900 NVMe SSD (1.9 TiB) Price : $1.4464 per HourRegular (x86) Instance: Instance : m5d.8xlarge Virtual CPUs : 32 RAM : 128 GiB Storage : 2 x 600 NVMe SSD (1.2 TiB) Price : $1.808 per Hour
操作系统及PG设置
我们选择ubuntun20.04 LTS AMIS,操心系统上没有做任何修改,在m5d.8xlarge上两个本地的NVME SSD统一在一个raid0中。PG使用PGDG存储库中提供的.deb包进行安装。
postgres=# select version(); version ---------------------------------------------------------------------------------------------------------------------------------------- PostgreSQL 13.1 (Ubuntu 13.1-1.pgdg20.04+1) on aarch64-unknown-linux-gnu, compiled by gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0, 64-bit(1 row)
aarch64 表示64位的ARM架构。
下面是PG配置:
max_connections = '200'shared_buffers = '32GB'checkpoint_timeout = '1h'max_wal_size = '96GB'checkpoint_completion_target = '0.9'archive_mode = 'on'archive_command = '/bin/true'random_page_cost = '1.0'effective_cache_size = '80GB'maintenance_work_mem = '2GB'autovacuum_vacuum_scale_factor = '0.4'bgwriter_lru_maxpages = '1000'bgwriter_lru_multiplier = '10.0'wal_compression = 'ON'log_checkpoints = 'ON'log_autovacuum_min_duration = '0'
Pgbench进行测试
执行命令:pgbench -c 16 -j 16 -T 600 -r
16个客户端连接和16个pgbench job。
无checksum的读写
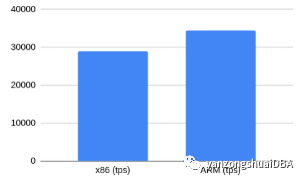

在ARM上有19%的提升.
有checksum的读写
Checksum计算会因架构不同而有不同性能吗?开启PG checksum命令:pg_checksums -e -D $PGDATA

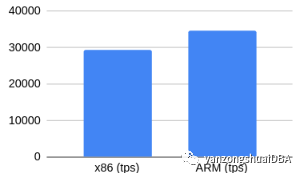
令人惊讶的是,结果稍微好点,不同只有1.7%,可以认为是噪声。至少可以得出这样的结论:在现代处理器上,启用checksum不会有明显的性能下降。
无checksum的只读
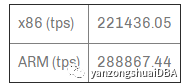
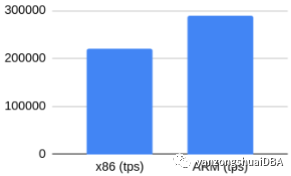
指定负载可以认为是CPU型,因数据大小能够全部放到内存,消除了IO影响。ARM下有30%的提升。
有checksum的只读


同样类似,有30%的提升。Checksum也没带来性能衰减。
注意:当PG从缓冲池读取或写出时会计算checksum并写入页。另外启用checksum后,总是会记录hint bits,增加了WAL IO的压力。为了争取验证checksum开销,需要更长更大的测试,就行增加对sysbench tpcc所做的一样。
sysbench-tpcc进行测试
我们决定使用sysbench-tpcc执行更详细的测试。注意感兴趣的是数据可全放到内存的情况。另一方面,虽然ARM服务器上PG没有问题,但是与x86服务器相比,sysbench根据挑剔。
每个测试执行下面步骤:
1)restore必要规模的数据目录(10/200)
2)用相同参数进行10分钟预热
3)PG端checkpoint
4)进行测试
16个线程,在内存
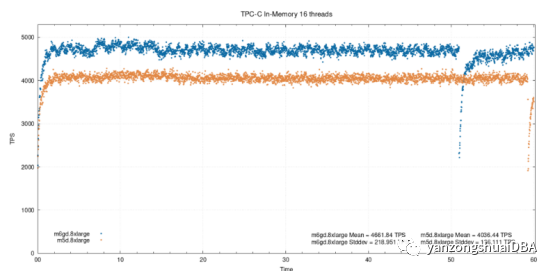
这种中等负载下,ARM实例性能提升了15.5%。此处及之后结果,百分比差异基于平均TPS值。
可能会思考,为什么测试在结束时性能会突然下降。他与full_page_writes的checkpoint有关。即使对于内存测试,使用了pareto分布,但是每个checkpoint后仍会写出相当多的页面。本实例中,显示WAL早于对应点触发checkpoint,所有进行的测试都会有这种下降。
32个线程,在内存
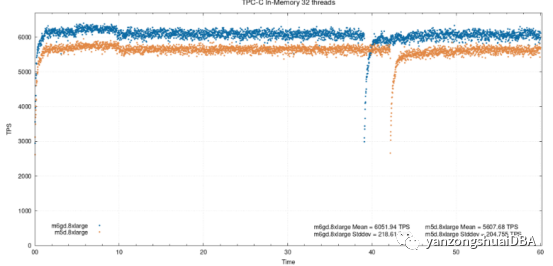
32个线程下,性能的不同减小到了将近8%。
64个线程,在内存
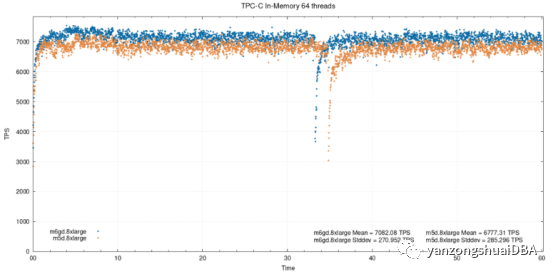
64个下,减小到了4.5%。
128个线程,在内存
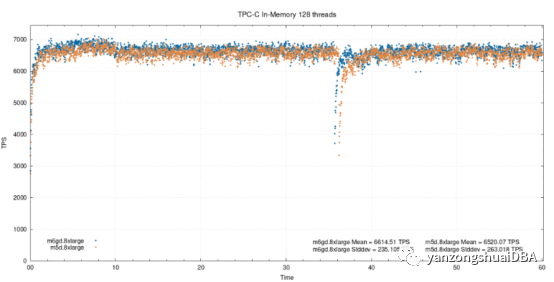
两个实例超过饱和点,性能差异就很小了。经仍保持在1.4%水平。此外可以看到ARM的tps下降了6-7%,在x86上下降了4%。
并不是所有测试都有利于Graviton2的实例。在IO绑定测试中,看到两个实例之间的差异很小,64个128个线程上,常规的m5d实例性能更好,从下面组合图上可看到这一点:
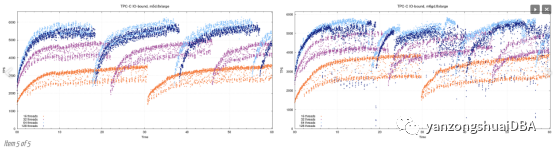
造成这种情况的一个可能原因,特别对于m6gd.8xlarge的128线程上的严重衰减,是因为缺少m5d.8xlarge所拥有的第二个驱动器。目前还没有完全可比较的实例可用,因此我们认为这是一个比较公平的测试。每个实例类型都有一定优势。需要更多测试和分析。可以使用EBS执行IO绑定测试,以尝试删除本地驱动器。
有关测试设置、结果、使用脚本和测试之间生产的数据的更详细信息,访问https://github.com/arronax/scratch/tree/master/performance/graviton2-postgres
总结
执行测试中,ARM实例比x86慢的情况不多。过去的几天测试中,结果一致。虽然基于ARM的实例便宜了25%,但与x86相比,能够在大多数测试中有15-20%的提升。因此基于ARM的实例在各方面提供了更好的性价比。
讨论的邮件列表:
https://news.ycombinator.com/item?id=25875342
