照片秒变icon?日本研究员提出基于生成对抗网络的Iconify模型来帮忙!
将门创投图标(icon)广泛应用于各种类型的平面媒体中,其简单抽象的形象表示、简明扼要的信息表达受到了很多人的青睐。但一个好看、生动的优秀icon需要设计师基于多年的设计经验,对目标进行充分的抽象、变形,重新设计成更光滑圆润、形象生动的图标化结果。如果对于没有设计经验的人来说,从一张照片得到一个好看的图标并不容易。
为解决设计师的这一痛点,来自于日本九州大学和电气通信大学的研究人员提出了基于生成对抗网络的Iconify模型,可以将输入的图像转换为较为形象简洁的图标,为图标生成和构建提出了新的可行方向。

图像主体的图标化
图标化指的是对图像中的目标进行抽象和简化的过程,下图显示了一些典型的图标。与原始多代表的目标相比,图标不仅仅是图像的二值化,同时还对原始图像进行了有效地抽象和简化设计。例如人体的头部都用一个圆来代替、复杂形状和细节被简化成了简单的几何结构。图形设计师的专业能力就在于省略、抽象和简化复杂的细节而保留原始目标中具有辨识力的典型特征。

研究人员希望利用机器学习技术将照片直接转换为图标,其核心在于机器学习算法是否可以有效捕捉和模拟人类设计师对于目标的抽象和简化能力,来构建美观的图标。但实现这一目标需要解决以下三个困难:
1. 首先针对真实图像和图标没有与之相匹配的配图图像,真实图像和图标间没有直接对应的匹配关系使得研究人员无法使用基于U-Net的直接转换方法,而需要在数据集间寻求两个不同域间的对应关系;
2. 其次两种图像间具有较大的风格差异,例如人物的头部在真实图片中具有很多细节特征,而在图标中则用简单的原型代替,这就需要模型能够学习出两种风格间的映射;
3. 此外两种图像的外形特征也不尽相同,图标虽然是简化的平面图形,但不同目标的形状差异也很大。对应的照片也是各具特色、颜色不一的。
研究人员将图标生成任务视为在照片和图标间实现域迁移的生成任务。由于没有对应的配对数据集,研究人员采用了基于CycleGan和UNIT等方法来构建模型,学习出从图像到图标的图标化能力。
在神经风格迁移提出后,各种模型都在利用深度学习的创作艺术作品上展现出了强大的能力,特别是基于生成对抗网络的模型引领了风格化的研究潮流。其中Pix2Pix就是其中著名的代表,它可以利用配对图像训练出非常好迁移结果,但配对图像的需求限制了它在缺乏对应数据集领域的应用。而CycleGan和UNIT这类模型却可以学习出两个图像数据集间的映射关系,而无需一一对应的图像对数据对模型进行训练。
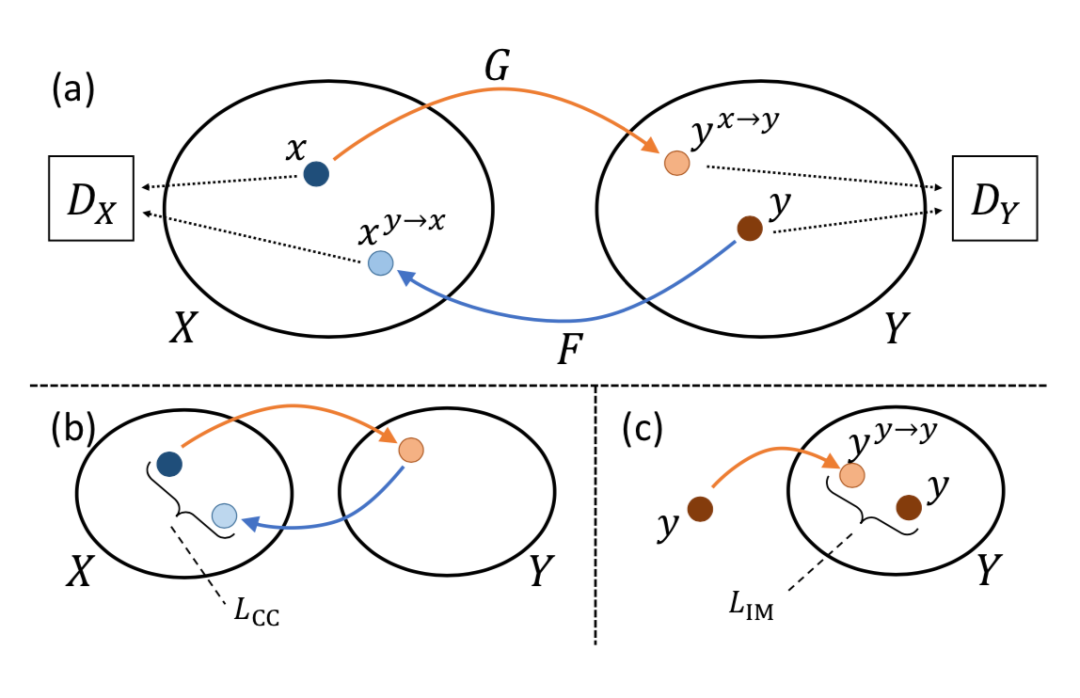
CycleGAN定义了两个图像集合X、Y间的映射,在不需要给定配对图像的情况下进行训练。它包含了两个生成器G和F以及两个判别器Dx和Dy,也就是两个生成对抗网络同时训练将X和Y两个不同的图像域耦合在了一起。在训练时一共定义了三个损失函数,包括用于训练GAN的对抗损失、用于双向训练XY间映射的循环连续性损失、以及保证颜色连续性的特性映射损失。
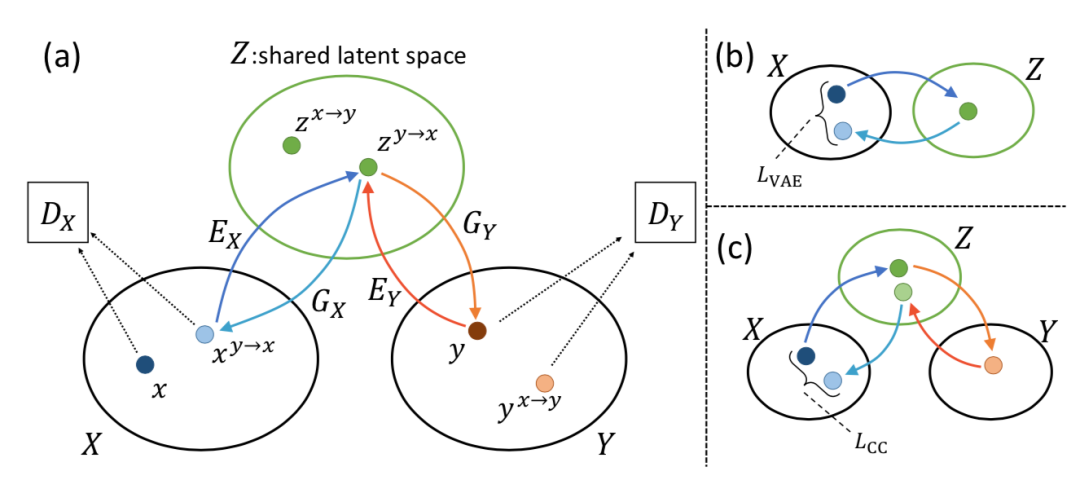
UNIT则可视为CycleGAN的拓展形式,实现了两个图像集合XY间的风格转换。UNIT与CycleGAN的主要不同在于需要满足原始图像与迁移后图像的表示变量需要在隐空间中保持一致。
下图展示了其基本架构,包含了两个编码器和两个生成器、以及两个判别器。这些模块利用VAE损失、对抗损失和循环损失共同训练,VAE损失的引入使得隐变量可以编码原始图像的足够信息。
为了训练CycleGAN和UNIT模型实现从图像到图标的迁移任务,研究人员利用了两个模型原始的代码代码版本进行了训练。其中图像数据来自于MS COCO数据集,从中选取了5000张图片包含11041个目标,并将其裁剪成了256x256大小的图像;而图标数据则来自于两方面,一方面利用你了ppt内自带的883张图片,并通过数据增强扩充到了8830张。此外,研究人员还使用了LLD数据集中的图像,包含了与本任务类似的logo风格迁移的数据集,研究人员选取了其中的20,000张并将其尺寸缩放成了256x256大小作为训练数据。
下图显示了数据集中的典型样本:


1 2 下一页>
