深度解析Spark底层执行原理(建议收藏)
园陌Spark简介
Apache Spark是用于大规模数据处理的统一分析引擎,基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量硬件之上,形成集群。
Spark源码从1.x的40w行发展到现在的超过100w行,有1400多位大牛贡献了代码。整个Spark框架源码是一个巨大的工程。下面我们一起来看下spark的底层执行原理。
Spark运行流程
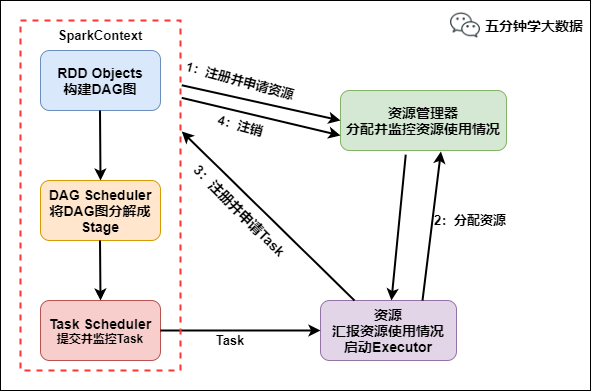
Spark运行流程
具体运行流程如下:
SparkContext 向资源管理器注册并向资源管理器申请运行Executor
资源管理器分配Executor,然后资源管理器启动Executor
Executor 发送心跳至资源管理器
SparkContext 构建DAG有向无环图
将DAG分解成Stage(TaskSet)
把Stage发送给TaskScheduler
Executor 向 SparkContext 申请 Task
TaskScheduler 将 Task 发送给 Executor 运行
同时 SparkContext 将应用程序代码发放给 Executor
Task 在 Executor 上运行,运行完毕释放所有资源
1. 从代码角度看DAG图的构建Val lines1 = sc.textFile(inputPath1).map(...).map(...)
Val lines2 = sc.textFile(inputPath2).map(...)
Val lines3 = sc.textFile(inputPath3)
Val dtinone1 = lines2.union(lines3)
Val dtinone = lines1.join(dtinone1)
dtinone.saveAsTextFile(...)
dtinone.filter(...).foreach(...)
上述代码的DAG图如下所示:
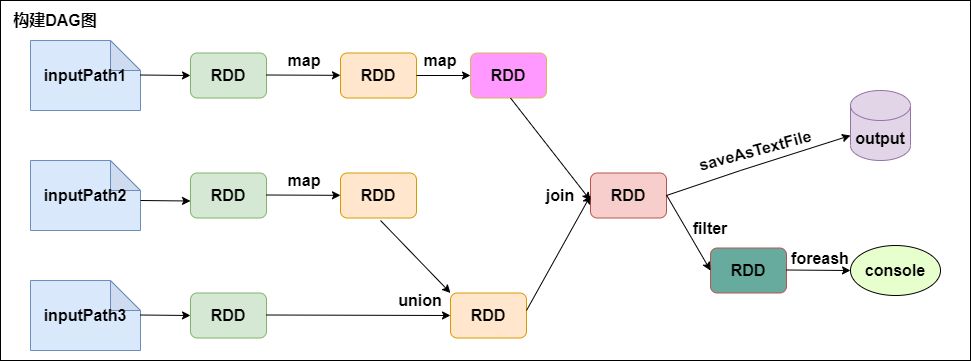
构建DAG图
Spark内核会在需要计算发生的时刻绘制一张关于计算路径的有向无环图,也就是如上图所示的DAG。
Spark 的计算发生在RDD的Action操作,而对Action之前的所有Transformation,Spark只是记录下RDD生成的轨迹,而不会触发真正的计算。
2. 将DAG划分为Stage核心算法
一个Application可以有多个job多个Stage:
Spark Application中可以因为不同的Action触发众多的job,一个Application中可以有很多的job,每个job是由一个或者多个Stage构成的,后面的Stage依赖于前面的Stage,也就是说只有前面依赖的Stage计算完毕后,后面的Stage才会运行。
划分依据:
Stage划分的依据就是宽依赖,像reduceByKey,groupByKey等算子,会导致宽依赖的产生。
回顾下宽窄依赖的划分原则:
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖。即一对一或者多对一的关系,可理解为独生子女。 常见的窄依赖有:map、filter、union、mapPartitions、mapValues、join(父RDD是hash-partitioned)等。
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)。即一对多的关系,可理解为超生。常见的宽依赖有groupByKey、partitionBy、reduceByKey、join(父RDD不是hash-partitioned)等。
核心算法:回溯算法
从后往前回溯/反向解析,遇到窄依赖加入本Stage,遇见宽依赖进行Stage切分。
Spark内核会从触发Action操作的那个RDD开始从后往前推,首先会为最后一个RDD创建一个Stage,然后继续倒推,如果发现对某个RDD是宽依赖,那么就会将宽依赖的那个RDD创建一个新的Stage,那个RDD就是新的Stage的最后一个RDD。
然后依次类推,继续倒推,根据窄依赖或者宽依赖进行Stage的划分,直到所有的RDD全部遍历完成为止。
1 2 下一页>
