数据孤岛下的 AI 向善与联邦迁移学习
学术头条9 月 4 日 - 6 日,由中国中文信息学会社会媒体处理专委会主办,浙江大学承办的第九届全国社会媒体处理大会(SMP 2020)在线上召开。
会议集结了包括潘云鹤院士、杨强教授在内的多名顶尖科学家、企业家与研究者,畅谈从自然语言到大数据智能,从社交机器人到计算传播学,研究金融科技、教育以及技术投资等最前沿的科技话题。
作为特邀重磅嘉宾,香港科技大学计算机与工程系,同时也是微众银行首席人工智能执行官的杨强教授,发表了题为 “数据孤岛:AI 向善与联邦迁移学习” 的演讲。
杨强教授是人工智能业界的国际专家,在学术界和工业界做出了许多贡献,尤其近些年为中国人工智能和数据挖掘的发展起到了重要的作用。
他是国际人工智能界 “迁移学习” 领域的发起人和带头人,同时为国际 “联邦学习” 的发起人之一及带头人。他当选为国际人工智能协会(AAAI)院士,成为第一位获此殊荣的华人,之后又当选为 AAAI 执行委员会委员,是首位 AAAI 华人执委,同时他也是第一位担任 IJCAI 理事会主席的华人科学家。
学术君就杨强教授在论坛中的精彩演讲进行整理,内容略有删改:
非常荣幸在 SMP 开场的时候有机会和大家交流我最近的一些研究心得。题目的缘起是数据孤岛和 AI,我们知道现在 AI 的热潮主要来自深度学习,而深度学习是离不开大数据的,但是其实我们周边更多看到的是小数据,数据难以获取、质量差的情况普遍存在,这些称为 “数据孤岛”,而且这些数据同时受到法律法规的限制,大部分不能进行使用,由此对各行业研究有一定影响。
面临这样的挑战,我们做技术的研究人员应该有对策,我们的对策有两条,一条是面对小数据,我们利用在别的地方获取大数据的经验,把这种知识迁移到小数据领域来。而我们作为人在解决问题的时候也经常使用这么一种迁移能力,像在教育领域,就有一个词叫 “学习迁移”,大致意思是学习能力比学习内容更重要。
第二个办法呢,我们知道知识常常散落在不同的地方,那么我们要把数据汇聚起来,形成大数据,往往是不能用简单粗暴的办法把数据聚集在一起。那么有一个更巧妙的办法,把模型建立起来,但是不用把数据汇聚起来。这里举一个例子,迁移学习就像一个老师在教一个学生,老师把自己的知识迁移到学生的大脑。那联邦学习就像一群大学生形成一个学习小组,来共同解决一个问题,大家都是单独的研究人员,但是在合作的时候形成互补,使得 1+1>2。那么今天的主题就是小数据能不能聚合成大数据。
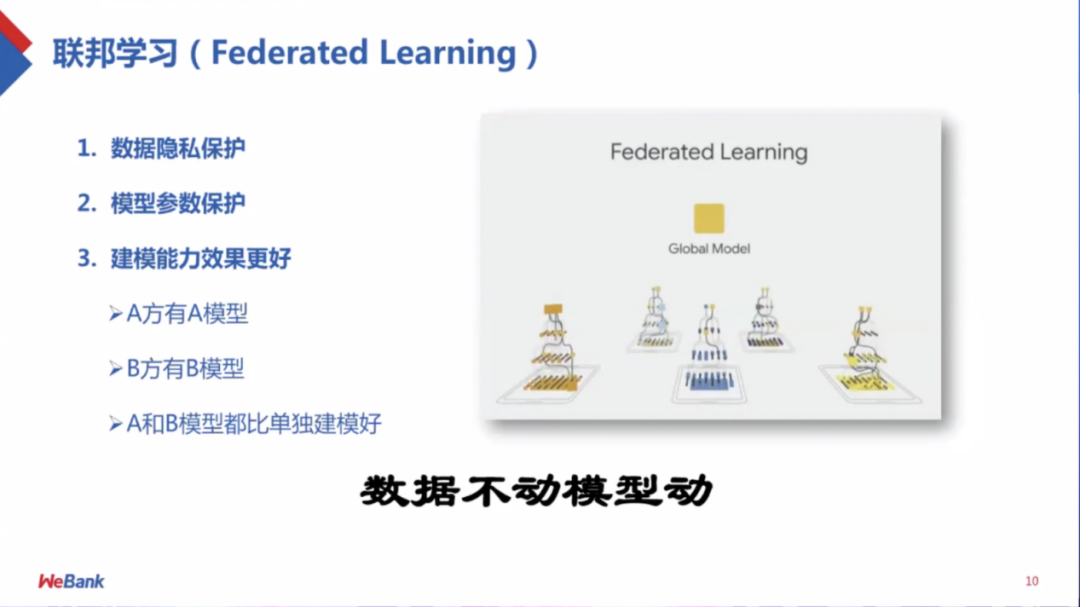
首先是“ 数据不动,模型动 ”的思想,意思是说把数据保留在本地,那么模型参数可以在加密的状态下进行沟通,最后希望得到的模型的效果和这些数据物理聚合在一起的效果是差不多的,有几种办法可以达到这一点。一种办法是按样本分割,横向切割数据,为了把所使用的数据量扩大,在本地建立带有参数的模型,把这些参数加密,然后整合到中心服务器,在加密的情况下进行操作。
除了横向切割,还有纵向切割数据,不同的数据集不同点在于特征不一样。比如对于一家医院,它擅长做 CT 扫描,另一家医院擅长做核酸检测,如果将两者合起来,特征空间就会变大,我们的模型也会变好,这种合并并没有增加样本量,因此叫做纵向。
联邦学习是一种手段,能够让不同的数据集合理合法合规地把模型建立起来,同时尽量不让数据出本地,让参数保密。由此也出现一些研究问题,比如算法是否合规,是否安全?若有坏人是参与方,我们是否能识别出来,能否防御?除此外,算法是加密条件下的分布式机器学习,那还需要考虑两个数据集不是同构或同分布的问题。
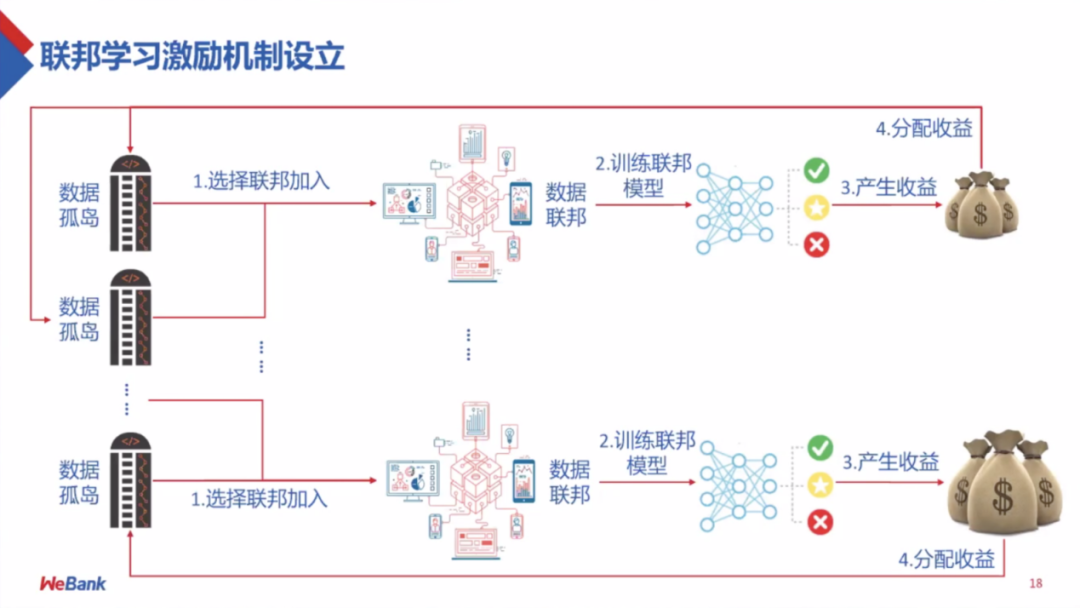
一个技术的兴起离不开大范围的应用,所以我们建立了一个联盟机制,它需要多个参与方的参与,而拥有数据孤岛的参与方越早参与越有利。首先加入联盟,需要参与到训练联邦,之后产出一定的效果,这个效果属于整个联盟,同时联盟也有一个分红机制,早加入贡献大的可以获得较多奖励。
但是如何持续吸引参与方加入联盟呢?这就需要我们不仅仅建立像经济学和博弈论的模型,同时还需要一个模拟的场景,那么这个场景就是我们最近研究的,需要考虑有哪些合理的激励机制,比较公平的分配方案。因此参与者可以看到通过联盟得到的收益以及需要它投入的成本。
1 2 下一页>
