技术分析:计算机视觉与机器学习等领域不平衡数据处理综述
磐创AI简介在现实世界中,我们收集的数据在大多数时候是严重不平衡的,所谓不平衡数据集就是训练样本不是平均分布在目标类中,例如,如果我们以个人贷款分类问题为例,就很容易得到“未批准”的数据,而不是“已批准”的信息,结果,模型会更偏向具有大量训练实例的类,这降低了模型的预测能力。在典型的二元分类问题中,它还会II型错误的增加。这一障碍不仅局限于机器学习模型,而且也主要存在于计算机视觉和自然语言处理领域。这些问题可以通过对每个区域分别使用不同的技术来有效地处理。注意:本文将简要概述各种可用的数据增强方法,但不深入技术细节,这里展示的所有图像都来自Kaggle。
目录
- 机器学习——不平衡数据(上采样和下采样)
- 计算机视觉——不平衡数据(图像数据增强)
NLP——不平衡数据(Google交易和分类权重)
1. 机器学习——不平衡数据
处理类不平衡的两种主要方法是上采样/过采样和下采样/欠采样。抽样过程只应用于训练集,对验证和测试数据不作任何更改。python中的Imblearn库可以方便地实现数据重采样。上采样是将合成生成的数据点(对应于少数类)注入数据集的过程,在这个过程之后,两个标签的计数几乎是相同的,这种均衡过程防止了模型向多数类倾斜,而且目标类之间的交互(边界)保持不变,同时,上采样机制由于附加信息的存在而给系统带来偏差。我们可以通过分析Google Analytics的贷款预测问题来解释这些步骤。这里使用的训练数据集可以在以下链接中找到。
SMOTE(SyntheticMinorityOversamplingTechnique)——upsampling: 上采样SMOTE基于knearestneighbors算法,综合生成数据点,这些数据点位于已经存在的数量被超过的群体附近。应用此方法时,输入记录不应包含任何空值。
#import imblearn library
from imblearn.over_sampling import SMOTENC
oversample = SMOTENC(categorical_features=[0,1,2,3,4,9,10], random_state = 100)
X, y = oversample.fit_resample(X, y)
datduplicate—upsampling: 在这种方法中,已存在的数据点被随机抽取并重复。from sklearn.utils import resample
maxcount = 332
train_nonnull_resampled = train_nonnull[0:0]
for grp in train_nonnull['Loan_Status'].unique():
GrpDF = train_nonnull[train_nonnull['Loan_Status'] == grp]
resampled = resample(GrpDF, replace=True, n_samples=int(maxcount), random_state=123)
train_nonnull_resampled = train_nonnull_resampled.append(resampled)
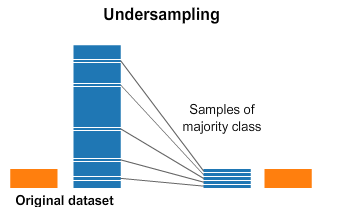
下采样是一种减少训练样本落在多数类下的机制。因为它有助于平衡目标类别的计数,但删除收集到的数据,我们往往会丢失很多有价值的信息。
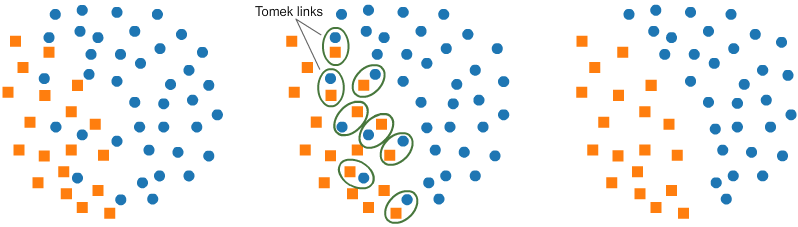
Tomek (T-Links): -
T-Link基本上是来自不同类(最近的邻居)的一对数据点,其目标是丢弃与多数类(数量较多的类)相对应的样本,从而减少占主导地位的标签的数量。这也增加了两个标签之间的边界空间,从而提高了性能准确性。
from imblearn.under_sampling import TomekLinks
undersample = TomekLinks()
X, y = undersample.fit_resample(X, y)
质心
2. 计算机视觉——不平衡数据
对于非结构化数据,如图像和文本输入,上述平衡技术将不会有效。在计算机视觉中,模型的输入是图像中像素的张量表示,所以只是随机改变像素值(为了添加更多的输入记录)就可以完全改变图片本身的意义。有一种概念叫做数据增强,即图像经过大量转换后仍然保持其意义不变。各种图像转换包括缩放、剪切、翻转、填充、旋转、亮度、对比度和饱和度变化,通过这样做,仅使用单个图像,就可以创建一个庞大的图像数据集。让我们看看Analyticsvidhya中发布的计算机视觉hackathon,使用的数据集可以在这里找到。
要求是将车辆分为紧急和非紧急两类。为了便于说明,我们使用“0.jpg”图像。

from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
img = load_img('images/0.jpg')
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
print(x.shape)
# the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='preview', save_prefix='vehichle', save_format='jpeg'):
i += 1
if i > 19:
break # otherwise the generator would loop indefinitely
在GitHub存储库中可以找到整个代码和一个预训练过的模型。
3. NLP——不平衡数据
自然语言处理模型处理序列数据,如文本、移动图像,其中当前数据与之前的数据有时间依赖性。由于文本输入属于非结构化数据,所以我们要以不同的方式处理这些场景。例如,以票据分类语言模型为例,其中IT票据必须根据输入文本中出现的单词顺序分配给不同的组。谷歌翻译(google trans python包): 这是扩展少数群体数量的有用技术之一。
在这里,我们把给定的句子翻译成“非英语”语言,然后再翻译成“英语”,通过这种方式,可以维护输入消息的重要细节,但是单词的顺序/有时具有相似意义的新词作为新记录引入,从而增加了不足类的计数。输入文字- "warning for using windows disk space"数据补充文字-“Warning about using Windows storage space”即使上面的句子的意思是一样的,它也引入了新单词,从而通过扩大输入样本的数量来提高语言模型的学习能力。下面执行的代码可以在GitHub存储库中找到。googletrans.readthedocs.io/en/latest/from googletrans import Translatortranslator = Translator()
def German_translation(x): print(x) german_translation = translator.translate(x, dest='de') return german_translation.text
def English_translation(x): print(x)
english_translation = translator.translate(x, dest='en') return english_translation.text
x = German_translation("warning for using windows disk space")
English_translation(x)
类权重: 该方法是在拟合模型过程中利用类权重参数。对于目标中的每个类别,都分配一个权重,与多数类相比,少数类将获得更多的权重,因此,在反向传播过程中,与少数类相关联的损失值越大,模型会对输出中的所有类一视同仁。import numpy as np
from tensorflow import keras
from sklearn.utils.class_weight import compute_class_weight
y_integers = np.argmax(raw_y_train, axis=1)
class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
d_class_weights = dict(enumerate(class_weights))
history = model.fit(input_final, raw_y_train, batch_size=32, class_weight = d_class_weights, epochs=8,callbacks=[checkpoint,reduceLoss],validation_data =(val_final, raw_y_val), verbose=1)
这个选项在机器学习分类器中也可用,如我们给class_weight = ' balanced '的' SVM '。# fit the training dataset on the classifier
SVM = svm.SVC(C=1.0, kernel='linear', degree=3, gamma='auto', class_weight='balanced', random_state=100)
结论到目前为止,我们已经讨论了不同领域处理不平衡数据的各种方法,如机器学习、计算机视觉和自然语言处理。尽管这些方法只是解决多数Vs少数目标群体问题的开始,还有其他先进的技术可以进一步探索。
