揭秘基于FPGA异构计算的深兰科技AI加速器平台
AI世界AI加速器是一类专门的硬件电路或计算系统,旨在加速人工智能算法的实现,尤其是机器学习、自然语言处理、计算机视觉和语音识别等需要大规模计算的应用。典型的应用场景包括无人驾驶系统、机器人技术、监控安防等计算密集型任务场景。
AI加速器是涉及算法模型、网络框架、软件工具链、加速器IP和硬件平台的复杂AI算法实现系统。深兰科技AI加速平台采用异构计算的FPGA芯片,并自主研发了加速器IP及整套开发工具,在多任务处理方面的优势尤为突出。
深兰科技AI加速解决方案如下图所示
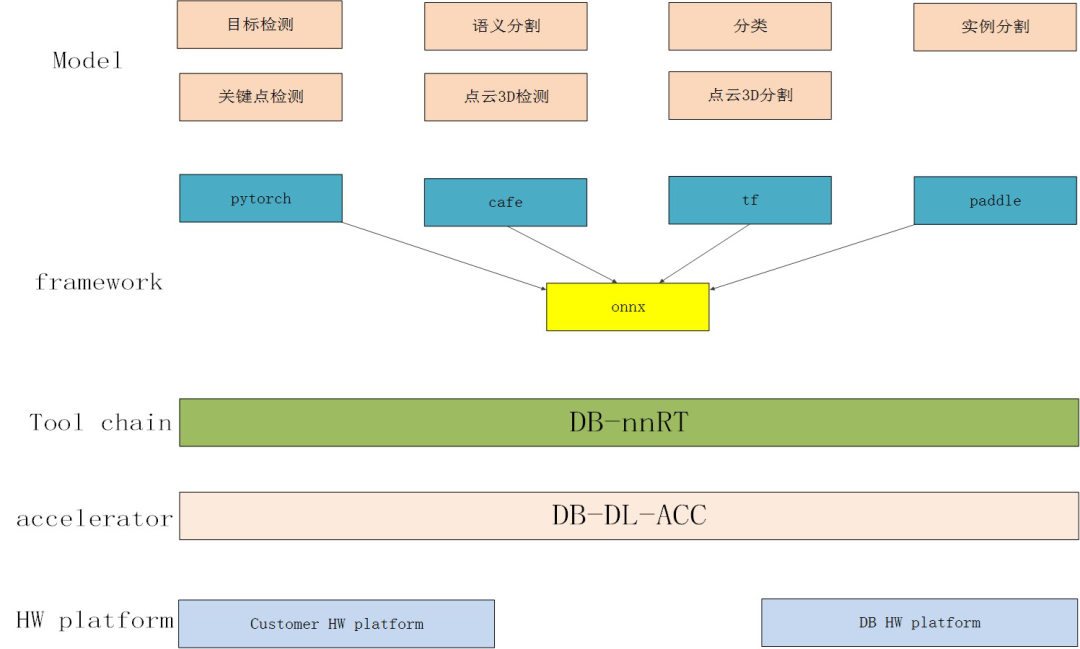
1.异构计算在AI加速领域的优势
深兰科技的AI加速硬件平台采用赛灵思的MPSOC系列FPGA。MPSOC是一种集成多处理器系统的异构计算芯片,其中的多处理器系统包括:CPU(applications processor),RTP(real-time processor),GPU(graphics processor)以及FPGA(Field Programmable Gate Array)。不同的处理器适合处理的任务不同,多处理器的异构计算系统在AI加速领域有着独特的优势。
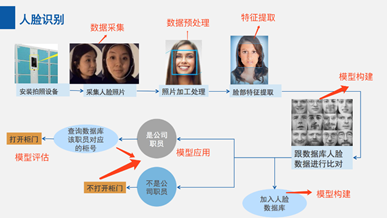
以人脸识别应用为例,来看一下异构计算平台在AI加速领域的表现。
1.数据采集阶段,计算平台要提供传感器接入的能力;
2.数据处理阶段,计算平台要提供常见的视频图像处理库;
3.特征提取和比对阶段,包含大量的数据调度和重复计算任务;
4.最终模型输出和显示阶段,计算平台要提供图像叠加和视频显示等功能。
单独的CPU更适合处理串行的控制流,不适用于大规模的并行计算;单独的GPU更适合处理大规模的并行计算,但是在处理控制流方面又显得捉襟见肘。MPSOC中的多核ARM适合视频采集和数据预处理,FPGA中各种加速算子适合特征提取和特征比对,Mali GPU适合最终输出显示。多种处理器协同合作才能高效的完成人脸识别任务。
深兰科技AI加速器如何高效工作
决定AI加速器工作效率的关键有三点:
1.高带宽的片外数据吞吐;
2.高效率的片上数据缓存;
3.针对性的大规模并行计算单元。
深兰科技AI加速器在设计的时候充分考虑了这三个因素
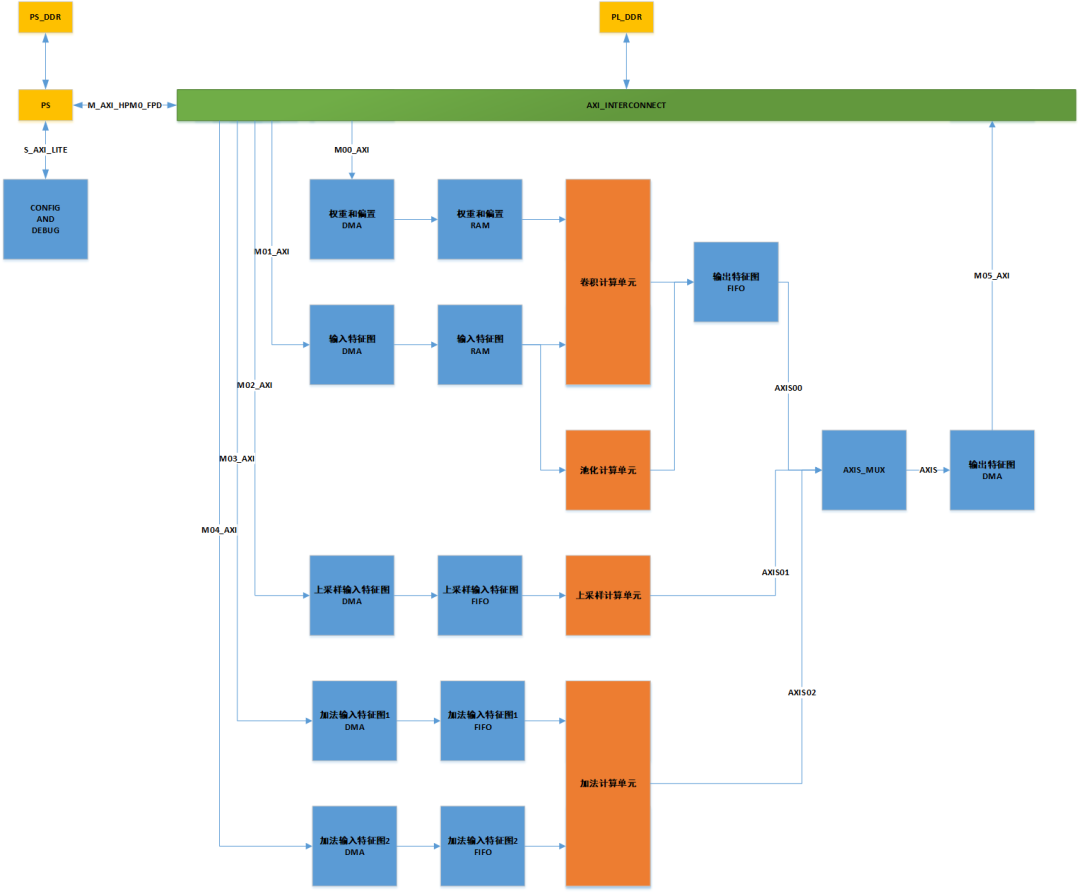
深兰科技自主研发的AI加速器采用ARM和FPGA协同工作的架构,ARM和FPGA上各挂有一组带宽高达150G的DDR4内存颗粒,两组内存统一编址,便于内存管理。内存颗粒和计算单元间采用AXI4高速总线互联,AXI_INTERCONNECT可以保证高效的多路数据总线读写仲裁,避免多路总线冲突及带宽分配不均衡。
高带宽的片外数据吞吐只能保证海量的数据可以送进FPGA,数据如果要进入计算单元,还要经过高效的片上数据重组和数据缓存。深兰科技的AI加速器按照NCHW的格式重组数据,重组完的数据被写入相应的片上缓存(RAM和FIFO)。
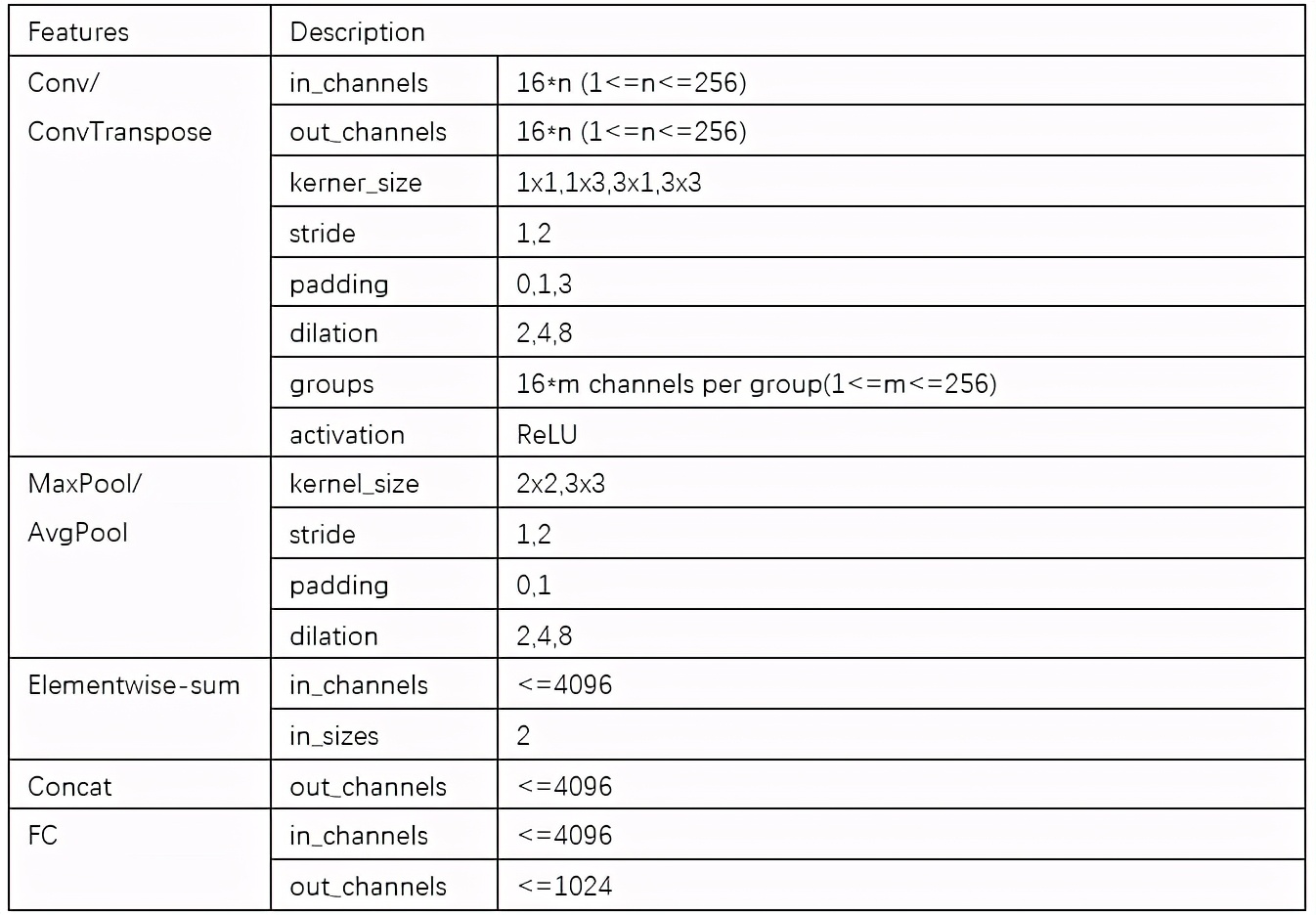
不同类型的计算任务由定制化开发的RTL算子完成,这样可以保证很高的计算效率。目前完成的算子包括卷积算子、池化算子、上采样算子、加法算子和softmax算子等,具体参数见下表。
3.深兰科技AI加速器应用案例展示
无人驾驶应用:
红绿灯识别,采用Mobilenet+Edlenet的组合神经网络提高小目标的识别准确性。

智能交通应用:
航拍目标检测,直升机高空俯视航拍,用于智能交通控制。
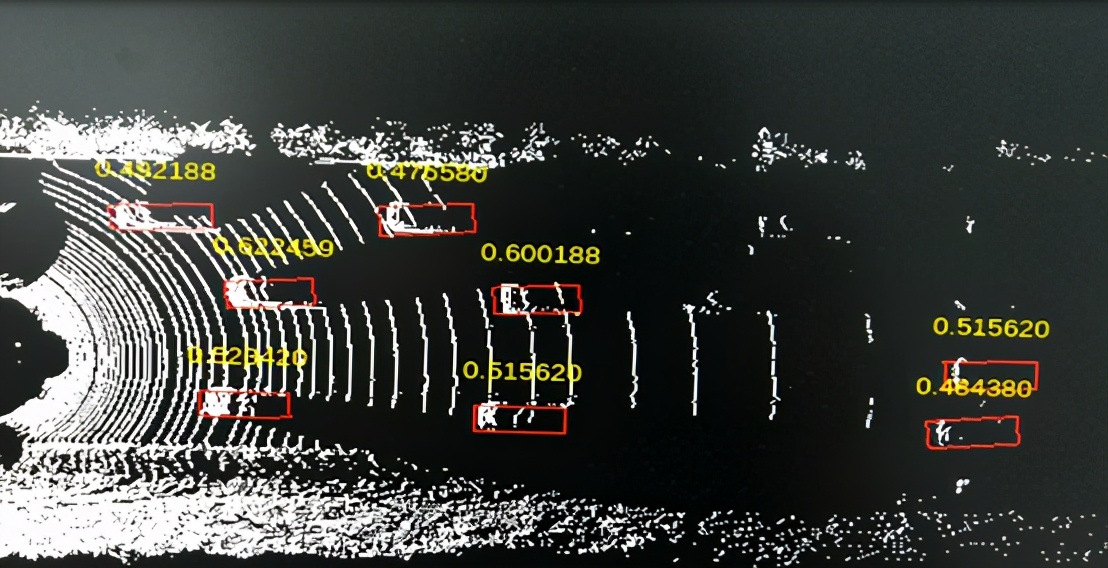
激光雷达应用:
点云数据目标检测,使用Pixornet神经网络进行3D 目标检测的鸟瞰图检测。
