深兰科技打破传统!用强化机器学习实现无人机轨迹规划
AI世界近年来,无人机已被广泛应用于很多领域,它不仅可以完成很多的任务,包括轨迹规划、避障、巡航等,在民用、军事都有很广泛应用,而且还有降低成本、提高效率、减少损失等很多作用。
但是传统的无人机任务都采用飞控控制,需要人为操作。为了使无人机可以具备更广的适用性,或者从技术上来说拥有更好的泛化能力,深兰科技科学院尝试用强化学习来训练无人机做指定的任务。如果训练效果能够达到足够稳定的性能,则可以进一步实现商用目的。本文在此基础上,带大家简单了解一下强化学习的基础知识。
强化学习小课堂
一、什么是强化学习?
1.强化学习
强化学习(Reinforcement Learning RL)也有很多其他名字,例如再励学习、增强学习、评价学习,是机器学习的范式和方法论之一,用于描述和解决智能体在与环境的交互过程中,通过学习策略以达成回报最大化或实现特定目标的问题。
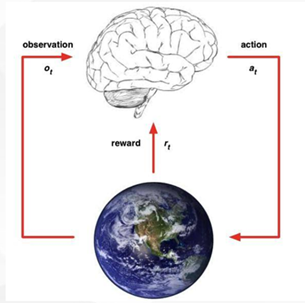
上图为经典的强化学习结构图,从图片中可以看出,强化学习过程主要由4部分构成:智能体(agent)、观测到的状态(observation/state)、奖励(reward)和行为(action)。
一个强化学习的过程中,智能体获得从当前环境中观测到的状态,然后根据这一状态采取一定的行为或策略,同时,有一个评价系统来评价这个行为的好坏,并返回正/负奖励给到智能体。循环往复,直到完成整个任务,此为一次强化学习的交互。整个强化学习训练过程就是,智能体与环境不断的交互,最终会学习到合理的策略,让奖励最大或者达到某个任务(指定的状态)。
强化学习受行为主义心理学的启发,例如巴甫洛夫条件反射实验,训练摇铃小狗流口水。小狗看到吃的流口水、摇铃不流口水,实验中就采取摇铃并给狗喂狗粮的方法不停训练,最终即使在没有狗粮,只摇铃的情况下,小狗也会流口水。
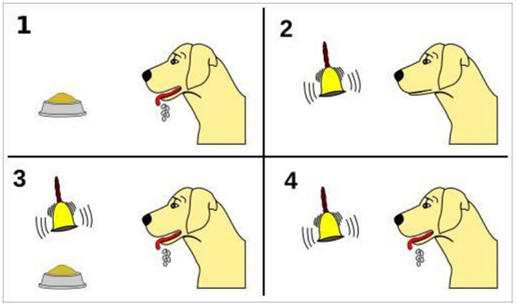
强化学习与此类似,是让智能体在与环境交互的过程中,一旦选择对的行为则给予正奖励加强这种行为,在不断的训练过程中使得智能体选择最合适的行为,最终使得智能体的每一步都能选择合理的行为,从而达到整体任务奖励最大化,并完成任务。
2.深度强化学习
我们一般所说的强化学习其实是深度强化学习(Deep Reinforcement Learning DRL),深度强化学习是强化学习与深度学习结合的结果。顾名思义,就是将传统强化学习中的某一部分用深度学习来完成。
传统强化学习中的行为以及价值都是需要人为定义的,这也就是为什么传统强化学习起源较早,但是应用并不广泛的原因之一。而深度学习恰好将这一问题解决了,强化学习中的行为以及价值都用一个深度学习的网络来学习得到,这样不需要人为设定,使得强化学习可以广泛应用于很多领域。而传统强化学习无法解决的连续性动作的问题,深度强化学习也可以解决,使用对应的Actor-critic网络即可。
深度强化学习的分类,有很多种分类标准:
(1)从智能体的个数上,可分为单智能体算法和多智能体算法;
(2)从是否基于模型的角度,可分为model-based和model-free;
(3)从训练时策略的选择,可分为on-policy和off-policy等等。
这里不一一展开,但在实际运用强化学习的时候,根据具体的任务或者项目,需要选择合适的深度强化学习算法。
二、强化学习可以解决什么问题?
这张图是2016年引起热议人工智能的AlphaGo事件,AlphaGo打败了围棋世界冠军李世石。AlphaGo作为一个智能体,就使用了深度强化学习技术进行了训练。在这一场景中,状态就是每一时刻的棋盘,行为就是下棋的动作,而评价系统会根据每一步棋的价值返回奖励。完成训练的AlphaGo在与李世石的比赛中,根据当前的棋盘选择最优的行为“下一步棋”,最终击败了李世石,这就是强化学习的一个具体应用。
智能体在不断与环境交互的过程中,会保留上次学习过的经验,下一轮与环境交互时,会选择奖励更大的行为,一般用来解决“智能体与环境交互时通过决策选择最好的行为”的这一类问题。
具体到现在的应用场景很广泛:
(1)工业应用:机器人作业;
(2)金融贸易应用:预测未来销售额、预测股价等;
(3)自然语言处理(NLP)应用:文本摘要、自动问答、机器翻译等;
(4)医疗保健应用:提供治疗策略;
(5)工程中的应用:数据处理、模型训练;
(6)推荐系统中的应用:新闻推荐、时尚推荐等;
(7)游戏中的应用:AlphaGo、AlphaZero等;
(8)广告营销中的应用:实时竞价策略;
(9)机器人控制中的应用:机械臂抓取物体等。
三、强化学习在无人机项目中的应用
1.简单轨迹规划

本项目研究的是无人机圆周轨迹运动规划。在这一简单任务中,需要让无人机飞到指定位置悬停,然后一直做圆周运动。简单分析这一任务,智能体就是无人机,行为就是对无人机的旋翼发出操作指令,状态就是当前无人机所处的位置以及无人机的性能,奖励则是根据无人机是否沿着圆周运动的轨迹判断。
具体到深度强化学习的框架,采用的是on-policy的PPO框架,之后也会用off-policy的DDPG、SAC框架进行比对效果。
2.复杂轨迹规划
在许多机器人任务中,如无人机比赛,其目标是尽可能快地穿越一组路径点。这项任务的一个关键挑战是规划最小时间轨迹,这通常通过假设路径点的完美知识来解决。这样所得到的解决方案要么高度专用于单轨道布局,要么由于简化平台动力学假设而次优,方案不具有可扩展性。
视频是使用深度强化学习和相对门观察的方法,自适应地进行随机轨道布局的效果展示,与传统的假设路径点轨道方法相比,基于轨迹优化的方法显示出了显著的优势。在仿真环境和现实世界中的一组轨道上进行了评估,使用真实四旋翼无人机实现了高达17米/秒的飞行速度。
3.悬挂运输
第二个主流方向是悬挂运输,运输悬挂的有效载荷对自动驾驶飞行器来说是一个挑战,因为有效载荷会对机器人的动力学造成重大和不可预测的变化。这些变化可能会导致飞行性能不理想,甚至会导致灾难性故障。视频是运用自适应控制与深度强化学习在这一问题上的效果展示,可以看出这种方法在此任务表现良好。
如果对强化学习或者无人机有兴趣的朋友可以与我们联系,一起讨论学习。
