昨晚,谷歌全球宕机:硬盘满了
物联网智库物联网智库 原创
转载请注明来源和出处
导 读
12月14日,美国科技巨头谷歌(Google)的许多服务在全球范围突然一度宕机,旗下用户大受影响。据悉,谷歌公司的自动系统直到服务中断了30分钟仍在汇报任何服务都没有出现问题,包括消费者服务和面向开发者的云服务。
12月14日,美国科技巨头谷歌(Google)的许多服务在全球范围突然一度宕机,旗下用户大受影响。
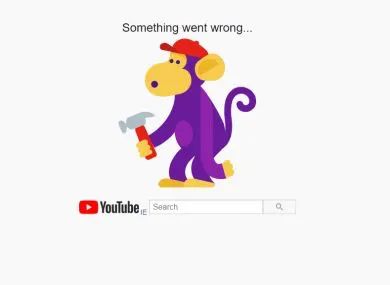
综合多家媒体报导,监察故障的网站“Downdetector”显示了超过9000个报告YouTube出现问题的用户报告。当用户尝试登录YouTube时,会出现一只猴子,并看到“出了点问题”的字句。
除了YouTube,谷歌旗下Gmail邮箱,Google日历、Google Drive、Google Search等服务也都受到影响,但大部分搜索引擎业务仍然完好,影响波及美国、欧洲、印度、加拿大、南非、中南美洲国家、澳大利亚和其他一些国家的用户。
据英国《卫报》当天报道,Google服务的大面积瘫痪大约从格林尼治标准时间(GMT)12月14日上午11时50分开始(北京时间19时50分),影响了公司旗下绝大多数的服务。而谷歌公司的自动系统直到服务中断了30分钟仍在汇报任何服务都没有出现问题,包括消费者服务和面向开发者的云服务。12时25分,谷歌才终于发现了问题。
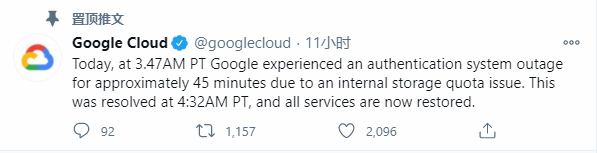
随后,Google Cloud在推特上回应:宕机是由于硬盘满了。
谷歌宕机,由来已久
据谷歌官方声明,本次事故原因是由于服务器上的硬盘空间分配出了问题,导致认证系统出了故障。其实,早前就有消息传出,谷歌云端运算服务容量存在问题。前段时间,谷歌宣布明年停止免费照片上传容量, 并鼓励订阅Google One也能说明这一点。
时至今日,谷歌终于还是栽了。

其实,这已经是谷歌今年第3次宕机事件了。9月25日,谷歌就曾上演过一次全球宕机,当时谷歌系统瘫痪多半集中在美国东岸,Gmail、YouTube、谷歌云端在系统宕机时,不断有用户持续尝试进入,但都无法顺利使用。
再往前,美东时间6月2号,基于谷歌云架构服务的诸多谷歌服务也在全球范围内遭遇大规模中断,宕机近4小时。据悉,不仅是Snapchat、Vimeo、Shopify、Pokemon GO等外部服务,包括如YouTube、Gmail、Google Search等谷歌自家服务的运行也受到了影响。
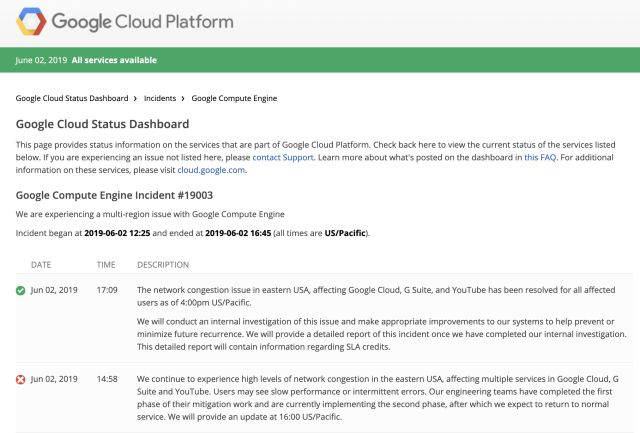
美国东海岸用户率先报告了这个问题,同时,宕机监控器DownDetector的报告表明,北美、英国、欧洲、南美等全球多地也受此影响。对于这个问题,谷歌公司表示是因为网络系统出现了问题,以后一定加强管理。
宕机的代价有多大?或许无人知晓确切的答案,但是可以粗略的估算一下。2013年谷歌曾发生过一次5分钟的宕机,谷歌当年第二季度营收达到141亿美元,相当于每分钟营收10.8万美元,换句话说,谷歌所有服务宕机5分钟,其直接损失就是54.5万美元,还不算由此带来的企业商誉影响和对客户业务的间接影响。
由此算来,谷歌单单今年的几次宕机,所带来的损失就已经难以估量。而这其中,几乎所有问题都围绕其云架构服务展开,而云架构讲究多地多活,防止单点故障。一个服务器出故障应该可以在几分钟内检测到,然后引流到其它服务器,同时启动休眠的服务器。
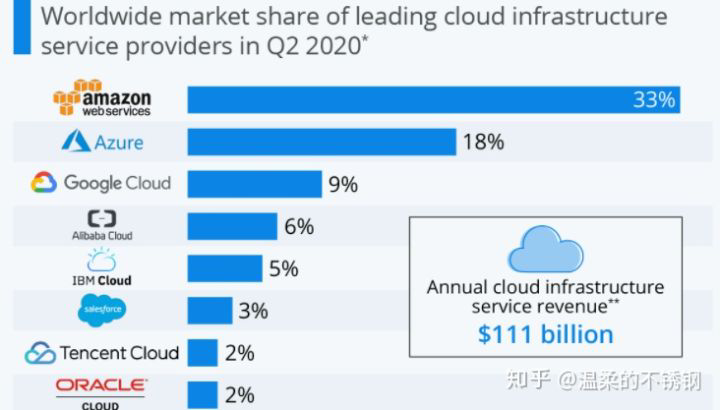
可见,谷歌云的市场占有率始终干不过前面两家大厂,也是有原因的。
主流厂商,竞相争“宕”
其实,不只是谷歌,微软也曾在云和硬盘方面发生过事故。
今年9月初,Windows 10的更新就出现了翻车事故。据了解,微软在更新中修复了Windows 10 2004的一些bug,但同时又引入了几个新的问题,导致用户频繁遇到PC崩溃、循环重启等情况。
而在之后的修复过程中,微软除修复一些常规bug,还特意更新解决了NVME固态硬盘引起的系统崩溃。据了解,Windows和NVMe固态硬盘的兼容问题一直都很差。此前,Windows 7就不支持使用NVMe的固态硬盘,因此装有NVME固态的电脑需要单独集成相关驱动才可使用。而即使此次修复,由于存储设备兼容性问题,也不是每个人的电脑都能够收到此次更新。
在云端,微软云计算服务Azure的主要组件在2014年8月就发生全球大范围宕机。微软表示,Azure服务当时处于中断状态,原因是位于全球多个数据中心的至少6个主要Azure组件无法提供服务。Azure允许企业获取计算资源,通过互联网运行程序。
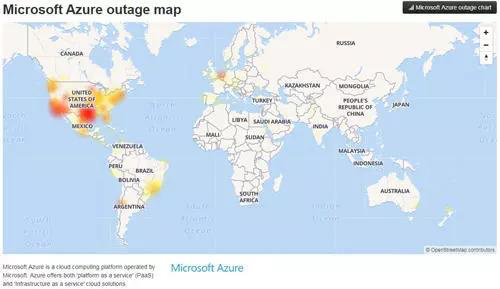
更令人震惊的是,2018年9月4日,微软在美国中南部地区的圣安东尼奥数据中心由于雷电天气影响导致电压激增,数据中心的冷却系统发生故障。为保证数据和硬件完整性,数据中心的自动化措施强制关闭了系统电源以防止机器因过热造成损坏。这一事故引发了 Azure 中断,Office 365 以及 Azure Active Directory 服务都受到影响,并且恢复相关存储服务经历了很长时间。
故障从9月4日上午9点(北京时间9月4日17:00)左右开始出现问题,一直持续到9月5日13点左右(北京时间9月5日21:00左右),整个故障中断时间超过 24 小时。
除了谷歌和微软,即使全球最领先的亚马逊云也曾屡次三番出现故障。
据外媒报道,2020年11月25日,亚马逊云端服务Amazon Web Services(AWS)遭遇了持续数小时的故障,导致部分网站和服务系统崩溃。AWS的服务状态页面上的通知显示,因其处理大量数据流的服务器Kinesis出现问题,导致一些网站的“错误率增加”,亚马逊已经对该问题进行了修复,但完全恢复还需要一段时间,并贴出了当前受到影响的服务。
值得一提的是,正值北美“黑色星期五”前夕,AWS宕机可能影响到亚马逊的电商业务。有卖家称,其亚马逊上的订单数据突然急剧下降,甚至广告费用也出现了异常。

此前,AWS云存储服务S3也曾在2017年出现大宕机,该错误持续了4个小时,彼时AWS解释称该故障是由于一名程序员在调试系统的时候,运行了一条原本打算删除少量服务器的脚本,结果输错了一个字母,导致大量服务器被删。被错误移除的服务其中运行着两套S3的子系统,从而导致S3不能正常工作,S3 API处于不可用状态。
不只是国外巨头,国内包括阿里云、华为云在内的业内巨头也曾出现宕机事故。
2020年4月10日上午,大批网友在微博反馈华为云崩了,出现登录异常、管理后台无法访问等情况。从网友晒图来看,不少使用云服务的后台都出现了“服务器暂时过载或处于维护中,请稍后重试。”“建立数据库连接时出错”等提示。
2019年3月20日下午,阿里系多款产品短时无法正常运作,时长约10分钟,涉及App包括淘宝、天猫、淘宝直播、闲鱼等。新浪科技亲测发现,淘宝和闲鱼均出现“重新加载”提示。
让外界颇感意外的是,阿里对外仅答复“修好了”,并未公布阿里系应用全线“崩溃”的原因。另外,仅仅1天后,3月21日,部署在阿里云上的铁路12306部分服务又一次发生故障。当用户搜索车票时系统显示“很抱歉,查询失败,您可以稍后点击下面按钮重试”。
由此可见,在越来越依赖“云计算”的今天,目前主流的云服务厂商依然不能确保万无一失。然而,在万物上云的今天,云服务一旦出现问题,所将造成的损失也将更加巨大。
如何避免云服务/云平台故障给自身业务带来损失?
毫无疑问,云服务在未来将成为电力一样的新型基础设施。然而,正如人类至今也没做到绝对避免停电一样,云服务在漫长的运行过程中发生故障亦在所难免,我们所要做的就是避免停电损失扩大化。
对于大部分业务来说,云平台的故障造成的损失并不致命。因此,我们可以通过多重保障,以避免云平台故障造成的损失扩大化,从而让损失可控。例如:
核心数据定期异地备份,尤其需要保证备份的可用性。
保留少量自有服务器或其它云平台主机,一旦发生故障,及时发布公告告知用户。
组织运维人员配合云平台恢复服务,核心运维保持随时在线。
及时对损失做出评估。
当然,在消费等服务之外,包括智慧医疗、智能交通等服务也将成为未来的主流应用场景之一。在这些领域,即使细微延迟都可能导致“人命关天”。对此,应该在边缘侧部署相对应的分析与计算能力,通过云边协同,保障场景的连续性、稳定性。
随着科技的不断发展,未来或将有越来越多的故障发生。为此,鸡蛋不能装在一个篮子里,请提前做好Plan B。
