三个模型对CNN结构演变进行总结
CV技术指南导言:
自2012年AlexNet在ImageNet比赛上获得冠军,卷积神经网络逐渐取代传统算法成为了处理计算机视觉任务的核心。
在这几年,研究人员从提升特征提取能力,改进回传梯度更新效果,缩短训练时间,可视化内部结构,减少网络参数量,模型轻量化, 自动设计网络结构等这些方面,对卷积神经网络的结构有了较大的改进,逐渐研究出了AlexNet、ZFNet、VGG、NIN、GoogLeNet和Inception系列、ResNet、WRN和DenseNet等一系列经典模型,MobileNet系列、ShuffleNet系列、SqueezeNet和Xception等轻量化模型。
在本文将对这些经典模型的结构设计演变做一个总结,旨在让读者了解一些结构的设计原理,产生效果的原因。在面对一个具体任务时能够准确地选择一个合理的特征提取网络,而不是随便选择一个。在自主设计网络时,也能根据总结的原则和经验设计出合理的结构,避免随心设计。
本文来源于公众号CV技术指南的技术总结系列。
更多内容请关注公众号CV技术指南,专注于计算机视觉的技术总结,最新技术跟踪。
CNN结构演变总结
在这个系列将按照以下三个部分对CNN结构演变进行总结。
一、经典模型,对AlexNet、VGG、NIN、GoogLeNet和Inception系列、ResNet、WRN和DenseNet这些模型的结构设计部分进行总结。
二、轻量化模型,对MobileNet系列、ShuffleNet系列、SqueezeNet和Xception等轻量化模型总结介绍轻量化的原理,设计原则。
三、对前面经典模型、轻量化模型中一些经典设计进行总结。如1x1卷积的作用、两种池化的应用场合、降低过拟合的方法、归一化方法、卷积层大小尺寸的设计原则和卷积核的作用等。
注:本系列没有对自动化结构网络设计的模型进行总结,主要原因是模型是由算法根据具体任务自主设计而来,并非人工设计,因此并不知道其设计原理,对其总结的意义不大。
这些模型的详细解读,包括实验,实际效果,完整结构,大部分都可在公众号CV技术指南的模型解读部分看到,少数模型的解读将在后续更新。相关模型的原论文以及所有模型解读的总结pdf,可关注公众号 CV技术指南 回复“CNN模型”获取。
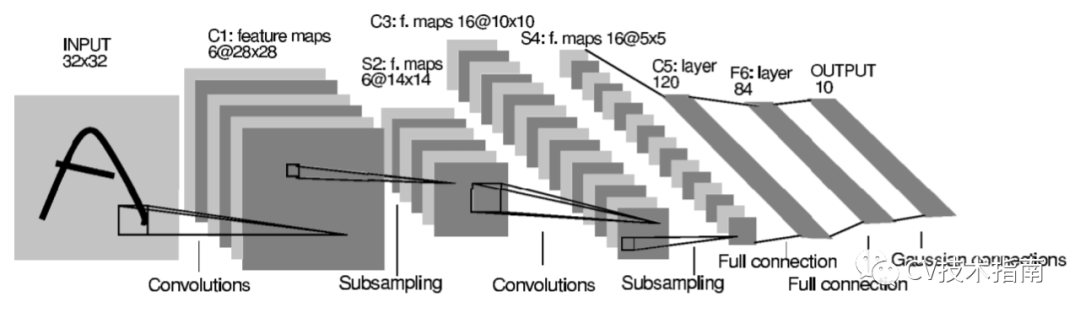
LeNet
第一个卷积神经网络出现在1989年,这个网络没有名字,对读者来说这个结构没什么新颖的,但其作为第一个卷积神经网络,值得致敬。其结构由卷积层和全连接层组成,激活函数使用tanh函数,损失函数使用的是均方误差MSE,使用了反向传播算法和随机梯度下降。值得一提的是,在这篇论文中还出现了权重共享和特征图像的概念。
LeNet是同作者LeCun在另一篇论文中提出的,用于手写数字识别。其结构图如下:
AlexNet(2012)
AlexNet是第一个深度神经网络,结构图如下:
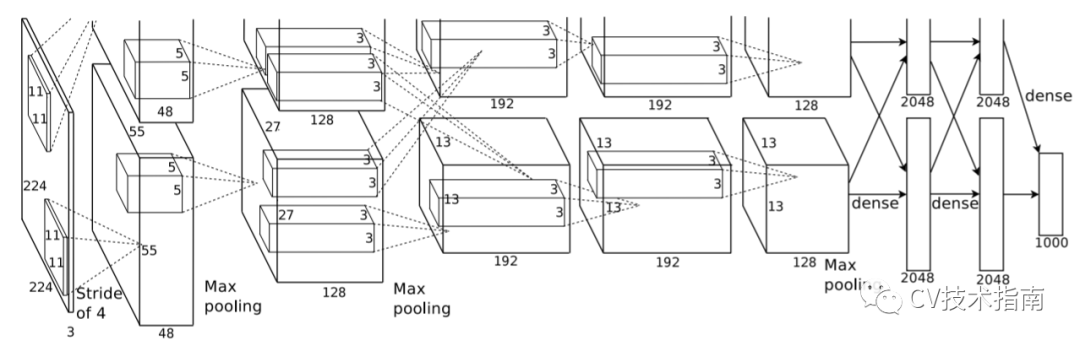
其创新之处有五处:
1. 使用ReLU作为激活函数。
2. 提出在全连接层使用Dropout避免过拟合。注:当BN提出后,Dropout就被BN替代了。
3. 由于GPU显存太小,使用了两个GPU,做法是在通道上分组。这算不上创新,之所以在这里写上这一点,是因为它是ShuffleNet_v1使用分组卷积想法的来源。关于ShuffleNet_v1在公众号CV技术指南的模型解读中有详细解读。
4. 使用局部响应归一化(Local Response Normalization --LRN),在生物中存在侧抑制现象,即被激活的神经元会抑制周围的神经元。在这里的目的是让局部响应值大的变得相对更大,并抑制其它响应值相对比较小的卷积核。例如,某特征在这一个卷积核中响应值比较大,则在其它相邻卷积核中响应值会被抑制,这样一来卷积核之间的相关性会变小。LRN结合ReLU,使得模型提高了一点多个百分点。
注:LRN后自Batch-Normalization出现后就再也没用过了,我印象中只有FstCN 2015年(使用分解时空卷积的行为识别)中用了一次,因此读者对这个可以不用去了解。
5. 使用重叠池化。作者认为使用重叠池化会提升特征的丰富性,且相对来说会更难过拟合。注:使用重叠池化会出现棋盘格效应。
NiN(2014)
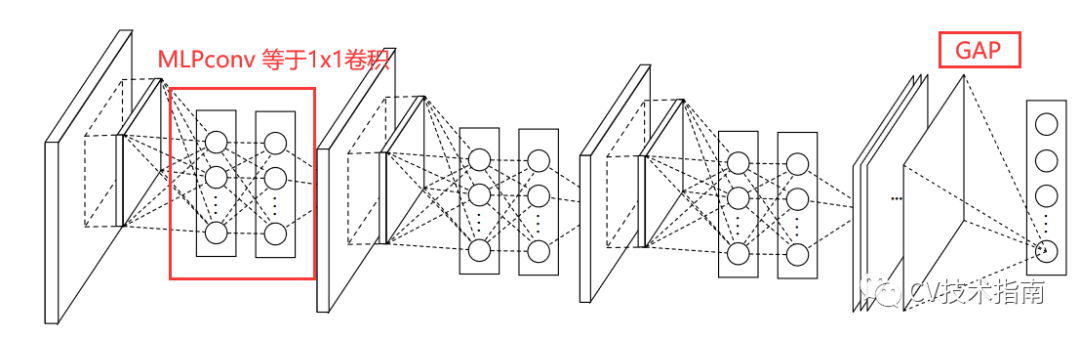
创新之处有二:
1. 使用MLPconv,后来在其它模型中就演变成了1x1卷积。
2. 提出全局平均池化代替全连接层。
这样做的好处有以下几点:
1. 相比于使用全连接层,参数量极大地减少,相对来说没那么容易过拟合。
2. 使得feature map直接映射到类别信息,这样更符合卷积网络的结构。
3. 全局平均池化综合了空间所有的信息,使得对输入的空间转换更鲁棒。
也有一个缺点:必须固定输入大小。
VGG(2014)
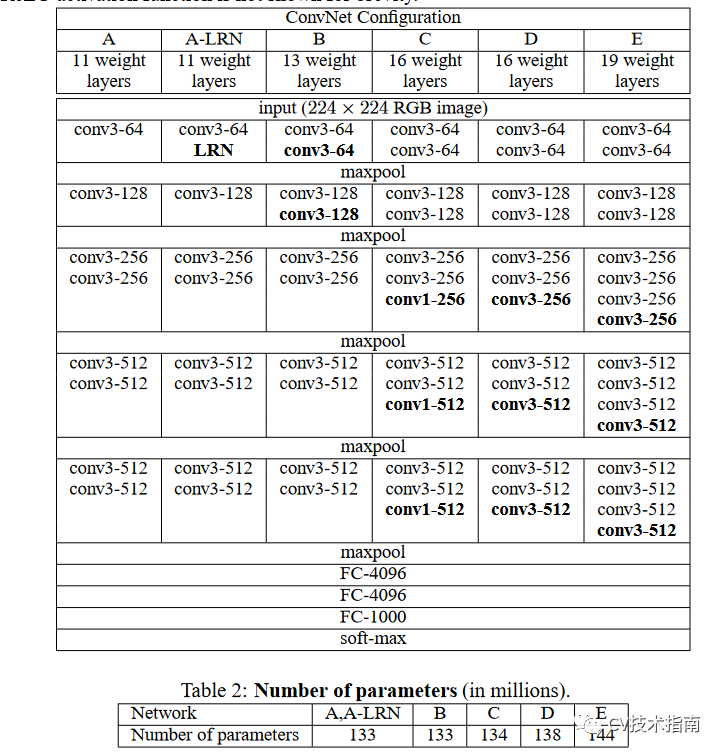
创新之处有二:
1. 使用了多个小尺寸的卷积核堆叠来代替一个大的卷积核,这样参数更少,而感受野却是一样的。全部使用了3X3的尺寸,池化都是2x2,步长都为2。
2. 去掉了LRN。作者发现它效果不明显。
GoogLeNet(2014)
GoogLeNet也称为Inception_V1, 其后续还有三个改进版,合称Inception系列,对这个系列的解读在模型解读部分有详细解读,这里只介绍新颖之处。
创新之处有二:
1. 提出Inception Module。大家发现网络越深越宽的效果越好,然而这样会带来以下几个问题:
1) 参数量,计算量越来越大,在有限内存和算力的设备上,其应用也就越难以落地。
2) 对于一些数据集较少的场景,太大的模型反而容易过拟合,但模型太小则泛化能力不够。
3) 容易出现梯度消失的问题。
解决这些问题比较直观的方法就是采用稀疏连接来代替全连接层,但很明显,由于底层是通过矩阵计算的,稀疏连接在参数量上减少了,但并没有减少计算量。因此设计了如下左图的结构。
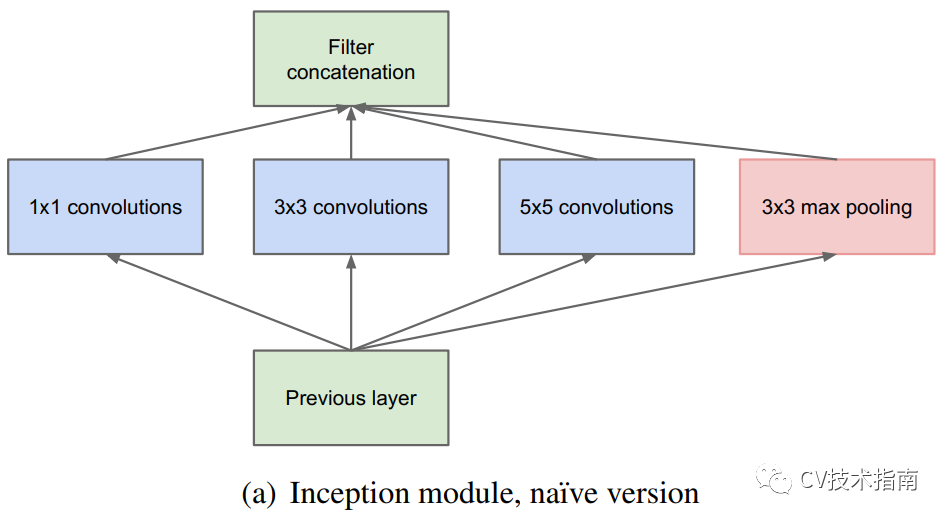
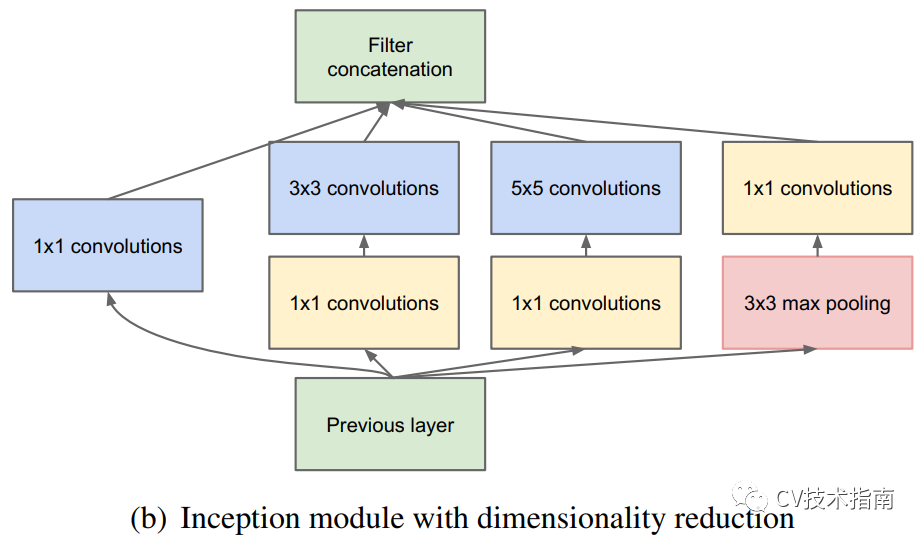
使用上面这个结构又会出现一个问题,由于使用了在通道上拼接的方式,导致通道数很大,因此使用NiN中1x1卷积的方式降低通道数。最终决定使用如右图所示的结构
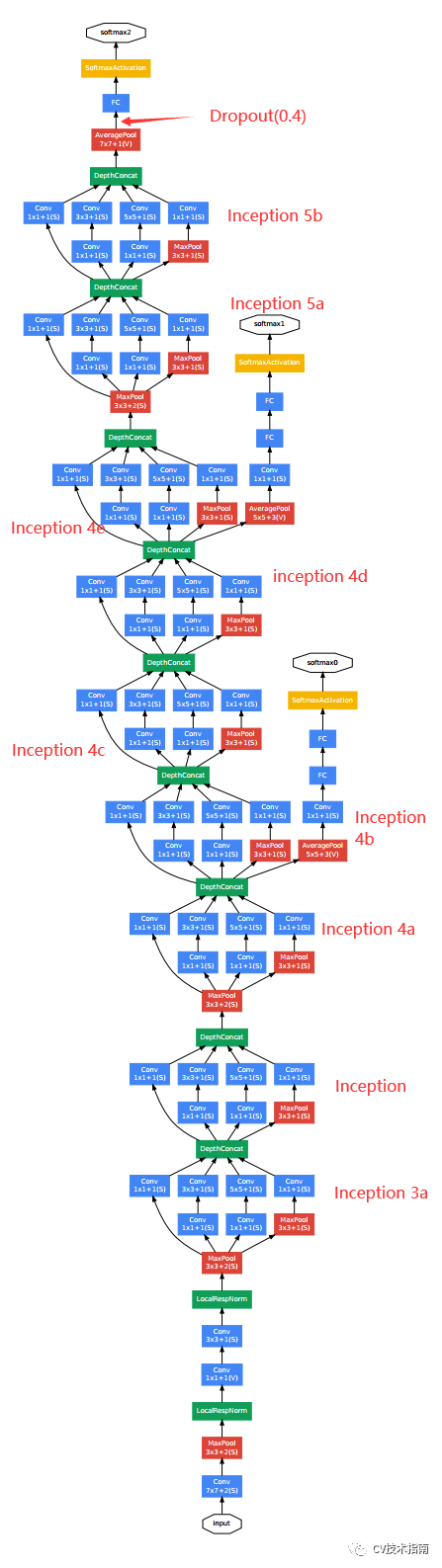
2. 使用了辅助分类函数,如下图所示,有3个softmax输出位置,有两个是在中间位置,这样方便在中间层输出分类,同时通过加权(中间0.3)的方式加到最终的分类结果中。作者认为这样能给模型增加反向传播的梯度信号,缓解了梯度消失问题,在一定程度上也有正则化的效果。在推理阶段,这两个softmax将会去除。
注:后面的InceptionV2-V3论文中会发现这玩意没用,但读者可以在自己的方向上尝试一下,也许会有用呢。
完整的结构图如下:
Inception_v2和Inception_v3
这两者是出现在同一篇论文中,作者提出了很多改进技术,使用了其中一部分的称为V2, 全部都使用的是V3。
创新之处有四:
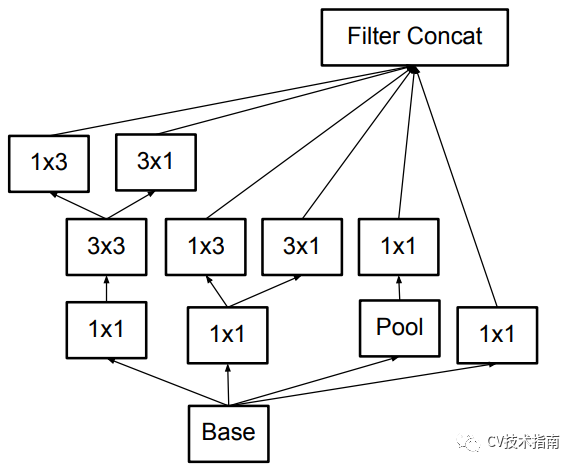
1. 提出分解卷积。如将5x5卷积核分解为1x5和5x1的非对称卷积堆叠。
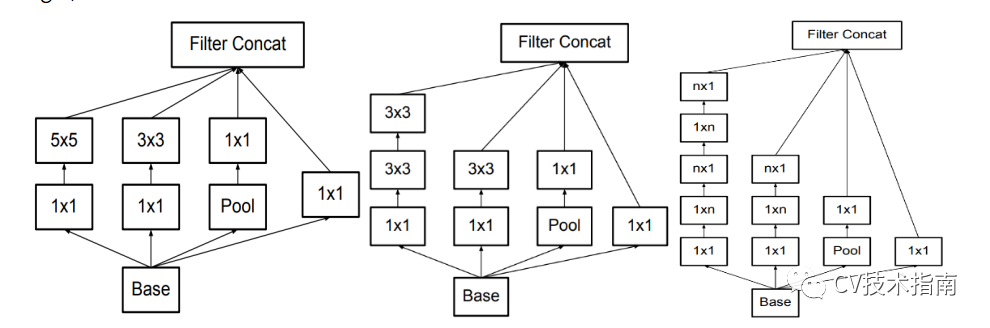
最终还衍生出了下面这种混合式的模块。(个人感觉没必要这么干,意义不大)
2. 使用了批归一化Batch-Normalization (BN), 关于BN,完整的介绍出现在另一篇论文中,公众号CV技术指南中也有对其完整的解读,感兴趣的读者可在模型解读中的《Inception系列之Inception_v2》中看到。注:当BN提出后,Dropout就被BN替代了。
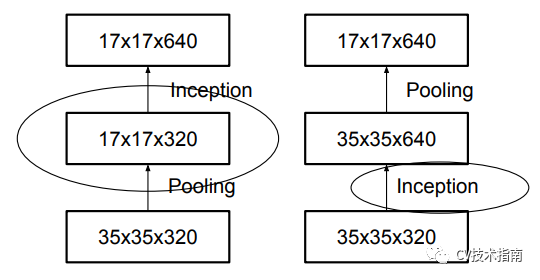
3. 提出一种高效降低特征图大小的方法。
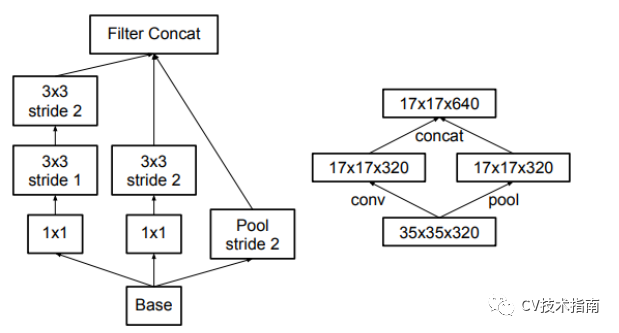
在降低特征图尺寸时,若按下图这两种方式设计,第一种会出现瓶颈,违背模型设计原则。(关于这些设计原则将会总结在《CNN结构演变总结》的第三篇中),第二种方式则参数量巨大。
因此就出现了下面这种
4. 提出标签平滑化。如果模型在训练过程中学习使得全部概率值给ground truth标签,或者使得最大的Logit输出值与其他的值差别尽可能地大,直观来说就是模型预测的时候更自信,这样将会出现过拟合,不能保证泛化能力。因此标签平滑化很有必要。
平滑化的方式是使得标签值小于1,而其它值大于0,如5个类,使得标签值为{0.05,0.05,0.8,0.05,0.05}。具体是由狄拉克函数函数实现的。感兴趣的可看该论文的解读。
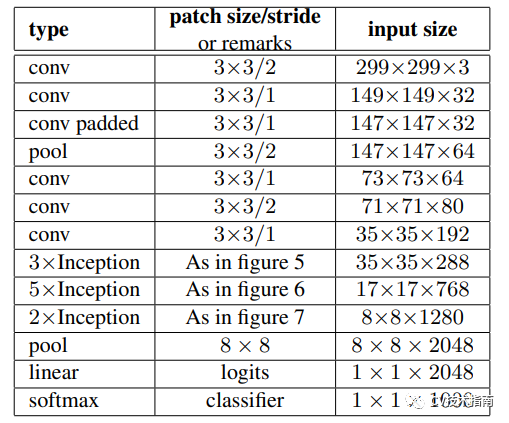
完整的结构如下:
Inception_v4, Inception_ResNet_v1和v2
在Inception系列的第四篇论文里,提出了三种结构,这三种结构没什么创新点,作者在论文中也没有介绍为什么这么设计。
如果一定要说有创新点的话,主要就是在上面Inception_v2-v3的基础上,第一种Inception_v4在Inception模块上改了一些参数,提出了几个不同参数的Inception block,与v2和v3没有本质上的改变。第二第三种结构在Inception模块中加入了残差连接,同样是没有本质上的改变,且比较少见有用这三种作为特征提取网络的,因此这里不多介绍。感兴趣的看该论文的解读,里面有完整的结构。
ResNet(2015)
一般而言,网络越深越宽会有更好的特征提取能力,但当网络达到一定层数后,随着层数的增加反而导致准确率下降,网络收敛速度更慢。
针对这个问题,ResNet的创新之处有二:
1. 提出shortcut connection, 右边直接连接的部分称为identity mapping。该方法灵感来源于Highway Networks。

注:刚开始认为残差连接可以缓解梯度消失问题,但在后续的论文中经过实验证明它似乎并不能。
2. 提出瓶颈模块( bottleneck block )。这个瓶颈模块在MobileNet v2中有所应用并调整。
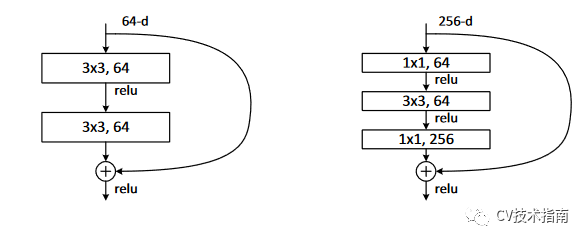
使用瓶颈模块构建出了ResNet34, ResNet50, ResNet101, ResNet152等深层
神经网络。
WRN(2017)
使用identity mapping的残差块使我们可以训练一个非常深的网络,但与此同时,残差块也是残差网络的一个缺点。当梯度流通过整个网络时,网络不会强迫梯度流过权重层(这会导致训练中学习不到什么)。所以很有可能少量的块能够学习有用的表达,或者很多的块分享非常少的信息,对最终结果影响很小。
创新之处有二:
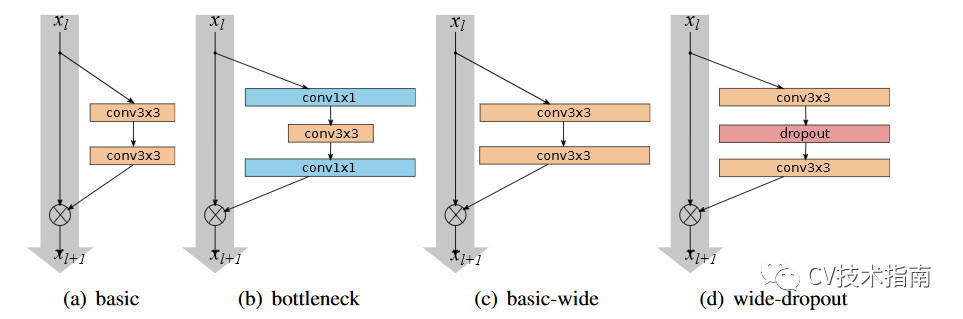
1. 提出加宽残差块的方式,这种方式可以更加高效地提高残差网络性能,而不是增加网络深度,使用这种方式构建了wider residual networks (WRN)。
2. 提出在残差块中使用Dropout。前人的研究中,dropout被插入到了残差网络中的identity连接上,这导致性能下降。而WRN提出dropout插入到卷积层之间的方式使性能有所提升。
DenseNet(2018)
传统的卷积网络在一个前向过程中每层只有一个连接,ResNet增加了残差连接从而增加了信息从一层到下一层的流动。FractalNets重复组合几个有不同卷积块数量的并行层序列,增加名义上的深度,却保持着网络前向传播短的路径。相类似的操作还有Stochastic depth和Highway Networks等。
这些模型都显示一个共有的特征,缩短前面层与后面层的路径,其主要的目的都是为了增加不同层之间的信息流动。
基于信息流动的方式,DenseNet创新之处有一:
1. 传统L层的网络仅有L个连接,在DenseNet中使用了L(L+1)/2个连接。这样做有几个明显的优点:避免了梯度消失问题,加强了特征传播,实现特征复用(feature reuse),以及实质上减少了参数量。
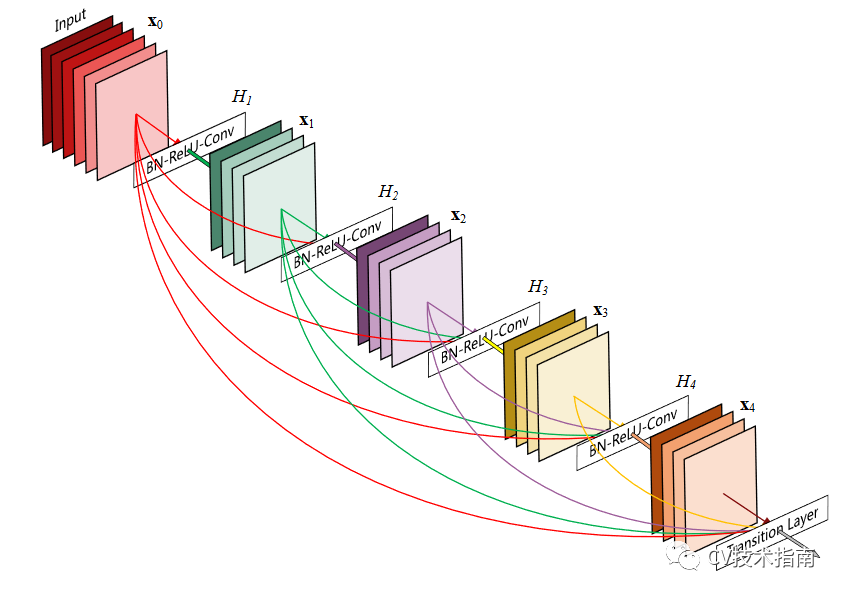
使用这个密集连接构建了Dense Block

总结:本文对比较经典的一些模型在结构上的创新之处进行了总结,让读者对目前特征提取网络有一个比较全面的了解,通过对创新之处的总结概括,相信读者对于CNN这种特征提取网络的作用机制有了清晰的认识。
本文来源于公众号CV技术指南的技术总结系列。
更多内容请关注公众号CV技术指南,专注于计算机视觉的技术总结,最新技术跟踪。
在公众号CV技术指南 中回复“CNN模型”可获得以上模型的详细解读pdf以及论文原文,注:少部分模型没有解读。
在下一篇将对目前的轻量化网络进行总结,在下篇中读者将了解到,目前降低神经网络计算量的方式有哪些,设计这样的方式的原理何在。
在第三篇中我们将对经典模型和轻量化模型中涉及到的一些方法进行总结,介绍原理作用,总结在这些模型论文中提到的网络设计原则,让读者可以根据具体任务自主设计网络或选择合适的网络,避免设计时胡乱选择参数或随意选择网络。
