一文详解不带Anchors和NMS的目标检测
CV技术指南前言:
目标检测是计算机视觉中的一项传统任务。自2015年以来,人们倾向于使用现代深度学习技术来提高目标检测的性能。虽然模型的准确性越来越高,但模型的复杂性也增加了,主要是由于在训练和NMS后处理过程中的各种动态标记。这种复杂性不仅使目标检测模型的实现更加困难,而且也阻碍了它从端到端风格的模型设计。
本文来源于公众号CV技术指南的技术总结系列。
更多内容请关注公众号CV技术指南,专注于计算机视觉的技术总结,最新技术跟踪。
早期方法 (2015-2019)
自2015年以来,人们提出了各种深度学习中的目标检测方法,给该领域带来了巨大的影响。这些方法主要分为一阶段方法和两阶段方法两类。其一般处理过程包括:
1.使用CNN主干提取深度特征图
2.为特征映射的每个像素生成各种锚点
3.计算锚点和ground truth之间的IoU,选择其中的一部分进行训练
4.使用回归(IoU和L1)和分类(框内的对象类)的loss对模型进行训练
5.使用非极大值抑制(NMS)对推理结果进行过程后处理,以删除重复的预测框
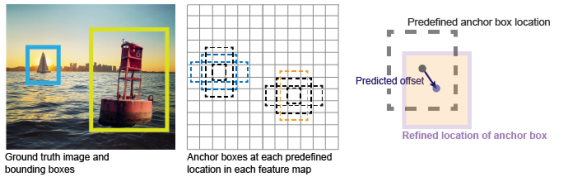
在上述一般过程中,one-stage和two-stages方法的唯一区别是在训练过程中是否为region proposal动态标记anchors。例如,在Faster-RCNN中,根据锚和ground truth之间的IoU给anchors作正或负的标记。如果IoU足够大,比如0.7,锚给正标签,否则如果IoU足够小,比如0.3,给出负标签。因此,在推理期间,只将正锚定用于目标检测处理。这种技术在原论文中被称为区域建议网络(RPN)。
在像SSD、YOLO和RetinaNet这样的one-stage方法中,不存在RPN,以便在推理过程中处理所有的锚点。分类置信度的阈值用于过滤大多数锚,而只有具有高分类可能性的锚被保留用于最终的后处理。
在训练过程中,锚的数量非常巨大。在two-stages的方法中,RPN帮助集中关注正锚点,这节省了计算时间和资源。然而,RPN是复杂的,训练它也需要时间和资源。在one-stage的方法中,尽管必须处理所有的锚点,但总的计算时间仍然更小。
由于two-stages方法的复杂性和速度较低,人们倾向于开发出更容易实现、更有效的新的one-stage方法。
什么是NMS以及为什么需要它
在上述早期的方法中,锚被用来与ground truth相匹配。因此,可能会发生多对一的匹配:几个锚与一个ground truth相匹配。如上所述,在一阶段和两阶段的方法中,几种不同的锚可能与同一个ground truth有较大的IoU。在推理过程中,它们也可以回归到具有高分类置信度的同一对象。因此,删除重复anchor,NMS后处理是必要的。
NMS处理过程:
1.预测的anchors根据分类置信度进行排序
2.选择最大置信度的anchor
3.删除所有与所选anchor的IoU大于预定义阈值的其它anchor
4.从1开始重复,直到不存在anchors
在推理结果中,许多与许多目标对应的anchor被混合在一起。一旦以置信度进行排序,可能会发生以下情况:
其中为两个对象A和B预测三个anchor。三个anchor的编号为1、2、3,分类置信度分别为0.8、0.75、0.7。在这里,为同一对象A预测两个anchor,因此应该移除一个具有较低可信度的anchor。在这种情况下,去除anchor 2,anchor 1和3用于最终预测。

为什么会发生这种情况?回想一下训练过程中的多对一匹配:anchor 1和2同时与对象A匹配,计算损失并反向传播梯度,告诉模型anchor 1和2都是对象A的有效候选对象。然后这个模型只是预测它被训练成什么。
因此,如果我们将多对一修改为一对一,并且在训练过程中只使用一个anchor来匹配一个ground truth,推理结果会有所不同吗?回想一下,在多对一范式中,对于一个对象,会选择具有大IoU的anchor来与它进行匹配。想想一对一的范式,其中只选择IoU最高的anchor进行匹配,而所有其他anchors都是负的,并与背景匹配。我们是否可以得到一个模型,它能够以一对一的匹配风格直接预测所有对象的所有anchor,而不需要NMS后处理?
最近的新方法(2019-2020)
幸运的是,上述问题的答案是肯定的。最近,人们一直在开发新的one-stage方法,使目标检测比以前更容易。主要思想有两方面:
1.不要使用anchor,而使用每像素预测
2.不要使用NMS后处理,改为使用一对一的训练
人们不会使用根据空间比例和对象大小而变化的anchors,而是倾向于通过使用语义分割等每像素的预测来降低复杂性。一种典型的方法是FCOS,其中最终特征图中的每个像素都用一个对象框进行预测,使其成为一个完全卷积网络(FCN)。用于目标检测的FCN不仅简化了任务本身,而且还将其与语义分割、关键点检测等其他FCN任务结合起来,用于多任务的应用。

我们可以看到,对于ground truth框内的每个像素,都可以分配一个标签:(l、r、t、b),表示ground truth框向左、右、上、下边界的像素之间的距离。因此,训练仍然是多对一的,NMS后处理仍然需要得到最终的预测结果。虽然FCOS简化了目标检测并性能良好,但它仍然不是端到端的。
为了使目标检测任务端到端,人们必须有不同的思考。自2020年以来,随着transformer的普及,人们倾向于用Vision Transformer进行目标检测,结果也很好。一个典型的方法是DETR,本文将不会讨论它。我将在这里讨论的是另一个并行的工作:OneNet,它将FCOS扩展为用于目标检测的端到端FCN。
如上所述,为什么NMS是必要的主要原因是在训练中使用了多对一范式。为了使它端到端没有NMS,应该使用一对一的训练范式来代替。
回想一下,在早期的方法中,预测和ground truth是匹配的,它们之间只有几何损失(IoU和L1)用于反向传播。因此,为了增加训练数据的方差,需要多对一匹配,因为可以找到许多几何损失相似的候选对象,并匹配相应的ground truth。这个候选框并不是唯一的。另一方面,如果我们坚持使用几何损失最低的候选模型进行一对一匹配,该模型可能会过拟合,并且根本不具备很好的泛化能力。
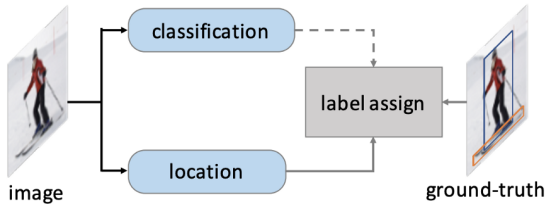
OneNet的作者认识到了这个问题,并使用了两种损失:几何损失和分类损失,以将候选框与ground truth相匹配。
与几何损失不同,分类损失对相应的ground truth是唯一的。例如,在目标的高级深度特征图中,我们可以找到一个最能表示目标类的唯一像素。虽然许多像素的几何损失与相应的ground truth相似的几何损失,但最佳分类损失的像素是唯一的。因此,我们可以将这两种损失结合起来,得到训练中唯一一个综合损失最低的候选框。
如原论文所述,只有具有最小损失的候选框才能匹配相应的目标,其他目标都是负的,并与背景匹配。
预测结果比较

多对一的结果

一对一的结果
第一行是早期多对一模型的预测结果,而第二行是一对一模型(OneNet)的预测结果。我们可以清楚地看到,许多冗余的预测框存在于多个一对一的结果中,而它们则在一对一的结果中消失。
讨论
利用一对一的训练范式,OneNet首先实现了端到端的目标检测。这一进展被认为是对损失和模型优化的深刻理解,这也有助于提高深度学习的可解释性。

