机器人能否“说人话”?
IT创事记往往在放下手机之后你才会意识到,电话那头的客服其实是个机器人;或者准确地说,是“一位”智能客服。
没错,今天越来越多的工作正在被交给人工智能技术去完成,文本转语音(TTS,Text To Speech)就是其中非常成熟的一部分。它的发展,决定了今天我们听到的许多“人声”,是如此地逼真,以至于和真人发声无异。
除了我们接触最多的智能客服,智能家居中的语音助手、可以服务听障人士的无障碍播报,甚至是新闻播报和有声朗读等服务,事实上都基于TTS这项技术。它是人机对话的一部分——简单地说,就是让机器说人话。
它被称为同时运用语言学和心理学的杰出之作。不过在今天,当我们称赞它的杰出时,更多的是因为它在在线语音生成中表现出的高效。
要提升语音合成效率当然不是一件容易的事。这里的关键是如何让神经声码器高效地用于序列到序列声学模型,来提高TTS质量。
科学家已经开发出了很多这样的神经网络声码器,例如WaveNet、Parallel WaveNet、WaveRNN、LPCNet 和 Multiband WaveRNN等,它们各有千秋。
WaveNet声码器可以生成高保真音频,但在计算上它那巨大的复杂性,限制了它在实时服务中的部署;
LPCNet声码器利用WaveRNN架构中语音信号处理的线性预测特性,可在单个处理器内核上生成超实时的高质量语音;但可惜,这对在线语音生成任务而言仍不够高效。
科学家们希望TTS能够在和人的“交流”中,达到让人无感的顺畅——不仅是语调上的热情、亲切,或冷静;更要“毫无”延迟。
新的突破出现在腾讯。腾讯 AI Lab(人工智能实验室)和云小微目前已经率先开发出了一款基于WaveRNN多频带线性预测的全新神经声码器FeatherWave。经过测试,这款高效高保真神经声码器可以帮助用户显著提高语音合成效率。
英特尔的工程团队也参与到了这项开发工作中。他们把面向第三代英特尔至强可扩展处理器所做的优化进行了全面整合,并采用了英特尔深度学习加速技术(英特尔 DL Boost)中全新集成的 16 位 Brain Floating Point (bfloat16) 功能。
bfloat16是一个精简的数据格式,与如今的32位浮点数(FP32)相比,bfloat16只通过一半的比特数且仅需对软件做出很小程度的修改,就可达到与FP32同等水平的模型精度;与半浮点精度 (FP16) 相比,它可为深度学习工作负载提供更大的动态范围;与此同时,它无需使用校准数据进行量化/去量化操作,因此比 INT8 更方便。这些优势不仅让它进一步提升了模型推理能力,还让它能为模型训练提供支持。
事实上,英特尔至强可扩展处理器本就是专为运行复杂的人工智能工作负载而设计的。借助英特尔深度学习加速技术,英特尔志强可扩展处理器将嵌入式 AI 性能提升至新的高度。目前,此种处理器现已支持英特尔高级矢量扩展 512 技术(英特尔AVX-512 技术)和矢量神经网络指令 (VNNI)。
在腾讯推出的全新神经声码器FeatherWave 声码器中,就应用了这些优化技术。
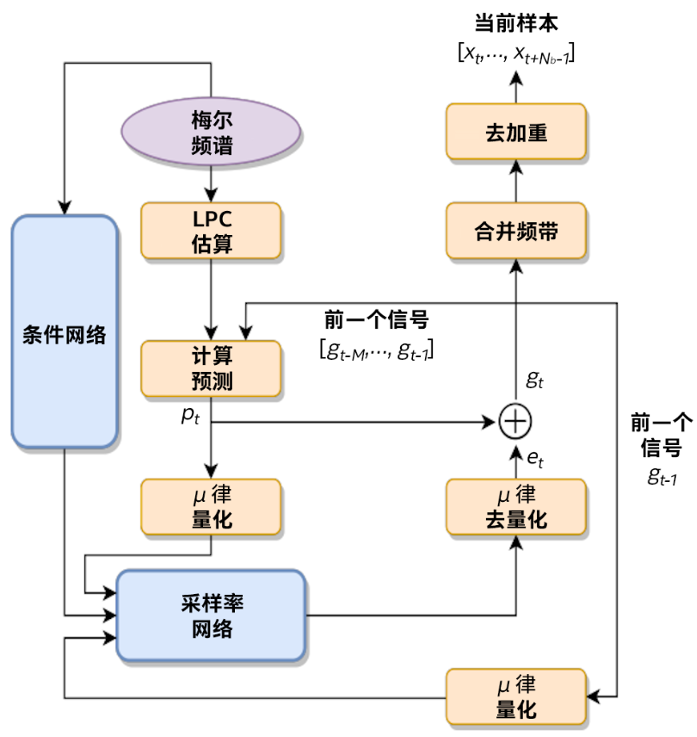
FeatherWave 声码器框图
1 2 下一页>
