用 Python 从零开始构建 Inception Network
磐创AI介绍
随着越来越多的高效体系结构出现在世界各地的研究论文中,深度学习体系结构正在迅速发展。这些研究论文不仅包含了大量的信息,而且为新的深度学习体系结构的诞生提供了一条新的途径,它们通常难以解析。为了理解这些论文,人们可能需要多次阅读那篇论文,甚至可能需要阅读其他相关论文。Inception 就是其中之一。
Inception 网络是 CNN 图像分类器发展过程中的一个重要里程碑。在此架构之前,大多数流行的 CNN 或分类器只是使用越来越深的堆叠卷积层以获得更好的性能。
另一方面,Inception 网络经过精心设计,非常深入和复杂。它使用了许多不同的技术来推动其性能;无论是速度还是准确性。
什么是Inception?
Inception Network(ResNet)是Christian Szegedy、Wei Liu、Yangqing Jia介绍的著名深度学习模型之一。Pierre Sermanet、Scott Reed、Dragomir Anguelov、Dumitru Erhan、Vincent Vanhoucke 和 Andrew Rabinovich在 2014 年的论文“Going deeper with convolutions” [1]中。
后来演化出了不同版本的 Inception 网络。这是 Sergey Ioffe、Christian Szegedy、Jonathon Shlens、Vincent Vanhouck 和 Zbigniew Wojna在 2015 年题为“Rethinking the Inception Architecture for Computer Vision” [2] 的论文中提出的。Inception模型被归类为最受欢迎和最常用的深度学习模型之一。
设计原则
–少数通用设计原则和优化技术的提议被证明对有效地扩展卷积网络很有用。
–在网络体系结构的早期,避免代表性瓶颈。
–如果网络具有更多不同的过滤器,这些过滤器将具有更多不同的特征图,则网络将学习得更快。
–降维的空间聚合可以在低维嵌入上完成,而不会损失太多表示能力。
–通过宽度和深度之间的平衡,可以实现网络的最佳性能。
初始模块
初始模块(naive)
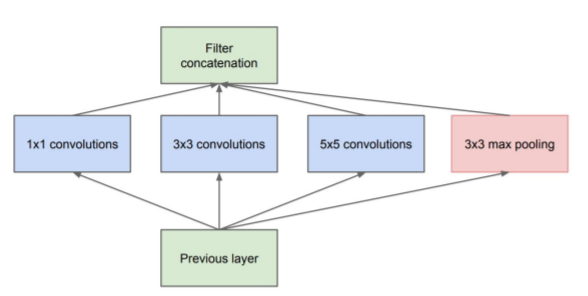
资料来源:'Going Deeper with Convolution ' 论文
最优局部稀疏结构的近似
处理各种尺度的视觉/空间信息,然后聚合
从计算上看,这有点乐观
5×5 卷积非常花费开销
Inception 模块(降维)
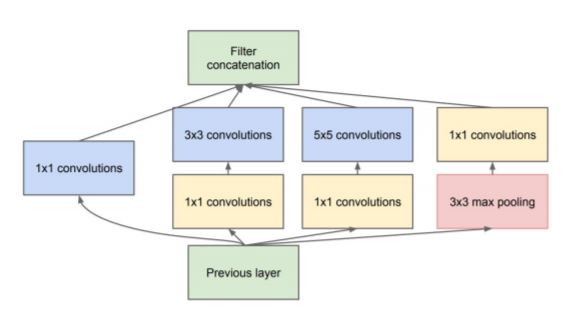
来源:'Going Deeper with Convolution' 论文
降维是必要和有动力的(网络中的网络)
通过 1×1 卷积实现
深入思考学习池化,而不是高度/宽度的最大/平均池化。
初始架构
使用降维的inception模块,构建了深度神经网络架构(Inception v1)。架构如下图所示:
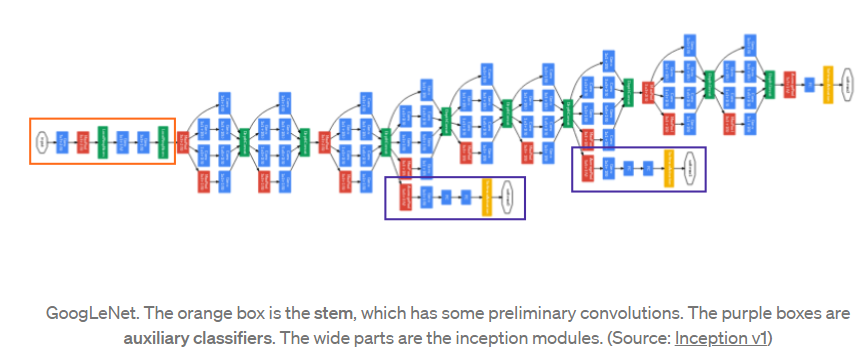
Inception 网络线性堆叠了 9 个这样的 Inception 模块。它有 22 层深(如果包括池化层,则为 27 层)。在最后一个 inception 模块的最后,它使用了全局平均池化。
对于降维和修正线性激活,使用了 128 个滤波器的 1×1 卷积。
具有 1024 个单元的全连接层的修正线性激活。
使用 dropout 层丢弃输出的比例为 70%。
使用线性层作为分类器的 softmax 损失。
Inception 网络的流行版本如下:
Inception v1
Inception v2
Inception v3
Inception v4
Inception-ResNet
让我们从头开始构建 Inception v1(GoogLeNet):
Inception 架构多次使用 CNN 块和 1×1、3×3、5×5 等不同的过滤器,所以让我们为 CNN 块创建一个类,它采用输入通道和输出通道以及 batchnorm2d 和 ReLu 激活.
def __init__(self, in_channels, out_channels, **kwargs):
super(conv_block, self).__init__()
self.relu = nn.ReLU()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
def forward(self, x):
return self.relu(self.batchnorm(self.conv(x)))
然后为inception module创建一个降维的类,参考上图,从1×1 filter输出,reduction 3×3,然后从3×3 filter输出,reduction 5×5,然后从5×5输出 和 1×1 池中输出。
def __init__(
self, in_channels, out_1x1, red_3x3, out_3x3, red_5x5, out_5x5, out_1x1pool
):
super(Inception_block, self).__init__()
self.branch1 = conv_block(in_channels, out_1x1, kernel_size=(1, 1))
self.branch2 = nn.Sequential(
conv_block(in_channels, red_3x3, kernel_size=(1, 1)),
conv_block(red_3x3, out_3x3, kernel_size=(3, 3), padding=(1, 1)),
)
self.branch3 = nn.Sequential(
conv_block(in_channels, red_5x5, kernel_size=(1, 1)),
conv_block(red_5x5, out_5x5, kernel_size=(5, 5), padding=(2, 2)),
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
conv_block(in_channels, out_1x1pool, kernel_size=(1, 1)),
)
def forward(self, x):
return torch.cat(
[self.branch1(x), self.branch2(x), self.branch3(x), self.branch4(x)], 1
)
让我们保留下图作为参考并开始构建网络。

来源:'Going Deeper with Convolution' 论文
创建一个类作为 GoogLeNet
def __init__(self, aux_logits=True, num_classes=1000):
super(GoogLeNet, self).__init__()
assert aux_logits == True or aux_logits == False
self.aux_logits = aux_logits
# Write in_channels, etc, all explicit in self.conv1, rest will write to
# make everything as compact as possible, kernel_size=3 instead of (3,3)
self.conv1 = conv_block(
in_channels=3,
out_channels=64,
kernel_size=(7, 7),
stride=(2, 2),
padding=(3, 3),
)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv2 = conv_block(64, 192, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# In this order: in_channels, out_1x1, red_3x3, out_3x3, red_5x5, out_5x5, out_1x1pool
self.inception3a = Inception_block(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception_block(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=(3, 3), stride=2, padding=1)
self.inception4a = Inception_block(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception_block(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception_block(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception_block(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception_block(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.inception5a = Inception_block(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception_block(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AvgPool2d(kernel_size=7, stride=1)
self.dropout = nn.Dropout(p=0.4)
self.fc1 = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
else:
self.aux1 = self.aux2 = None
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
# x = self.conv3(x)
x = self.maxpool2(x)
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
x = self.inception4a(x)
# Auxiliary Softmax classifier 1
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
# Auxiliary Softmax classifier 2
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.inception4e(x)
x = self.maxpool4(x)
x = self.inception5a(x)
x = self.inception5b(x)
x = self.avgpool(x)
x = x.reshape(x.shape[0], -1)
x = self.dropout(x)
x = self.fc1(x)
if self.aux_logits and self.training:
return aux1, aux2, x
else:
return x
然后为输出层定义一个类,如论文中提到的 dropout=0.7 和一个带有 softmax 的线性层来输出 n_classes。
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=0.7)
self.pool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = conv_block(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
x = self.pool(x)
x = self.conv(x)
x = x.reshape(x.shape[0], -1)
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
然后程序应该如下所示对齐。
– Class GoogLeNet
– Class Inception_block
– Class InceptionAux
– Class conv_block
然后最后让我们写一小段测试代码来检查我们的模型是否工作正常。
# N = 3 (Mini batch size)
x = torch.randn(3, 3, 224, 224)
model = GoogLeNet(aux_logits=True, num_classes=1000)
print(model(x)[2].shape)
输出应如下所示

