谷歌全新离线语音识别模型更小,功耗更低!
AI锐见语音识别是Siri、Alexa和Google等智能手机的重要组成部分,但这些语音识别系统有一个很大的缺点,那就是会有相应的延迟,用户必须等待Siri或其他虚拟助手来响应查询,而且如果语速过快就有极大可能造成误解。
有延迟出现是因为用户的语音以及从中获取的数据必须从要手机传输到服务器,在那里进行分析后再发回。这可能需要从几毫秒到几秒的时间,如果数据包在过程中不小心失,则需要更长时间。

为什么不能直接在设备上进行语音识别呢?因为将语音转换成毫秒级的文本需要相当大的计算能力,这不仅仅是听一段声音和写一个单词,而是逐字逐句地理解一个人在说什么以及涉及到意图和整个语境。
当然,手机其实是可以做到这一点的,但这并不会比把手机上的内容发送到云端快多少,而且会大量耗电。但随着该领域的稳步发展,这一目标似乎已成为可能,谷歌就使得这一功能在Pixel上得到实现。
为实现这一转变,Google团队花了五年时间研究问题并简化用于语音识别的AI系统。例如,旧版Gboard的听写软件由三个独立的组件来模拟音频波形,将声音与音素匹配,然后将这些音素组合成文字输出,更新后的版本将所有这些工作集合到一个步骤中。
新模型还缩小了系统中被称为“解码器图形”的部分,这个组件的功能类似于书中的索引,将音频波形与书面文字相匹配。在Gboard的听写模型的旧版本中,这个解码器图形大小为2GB,对于设备上处理来说太大了。相比之下,新版本仅为80兆字节,缩小了25倍。
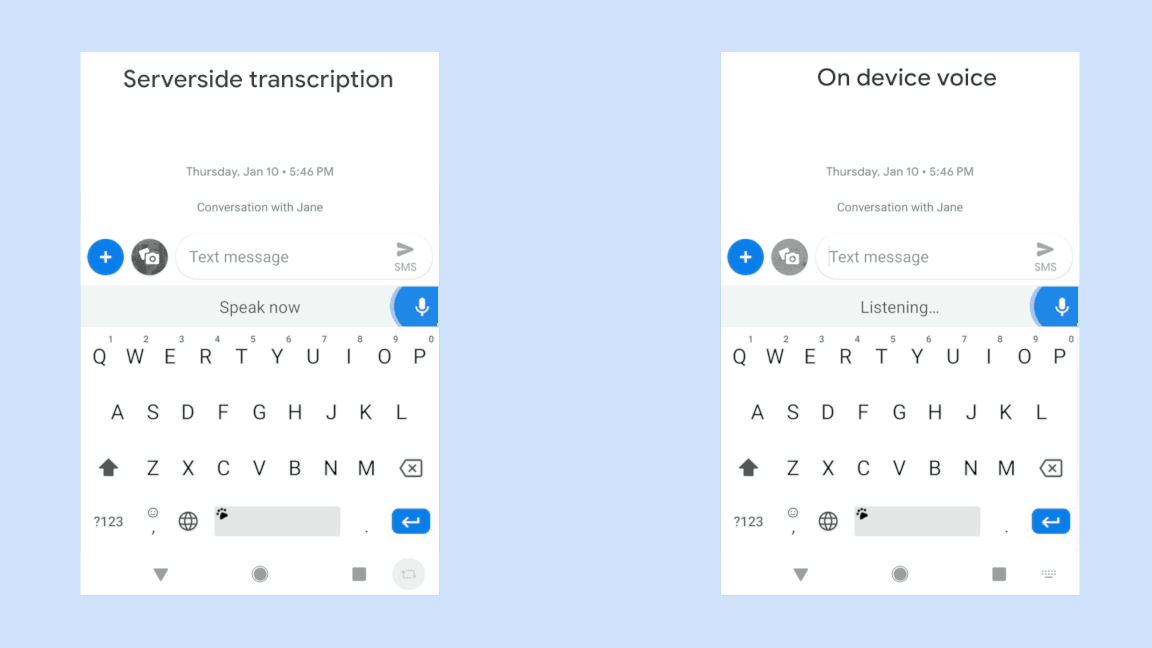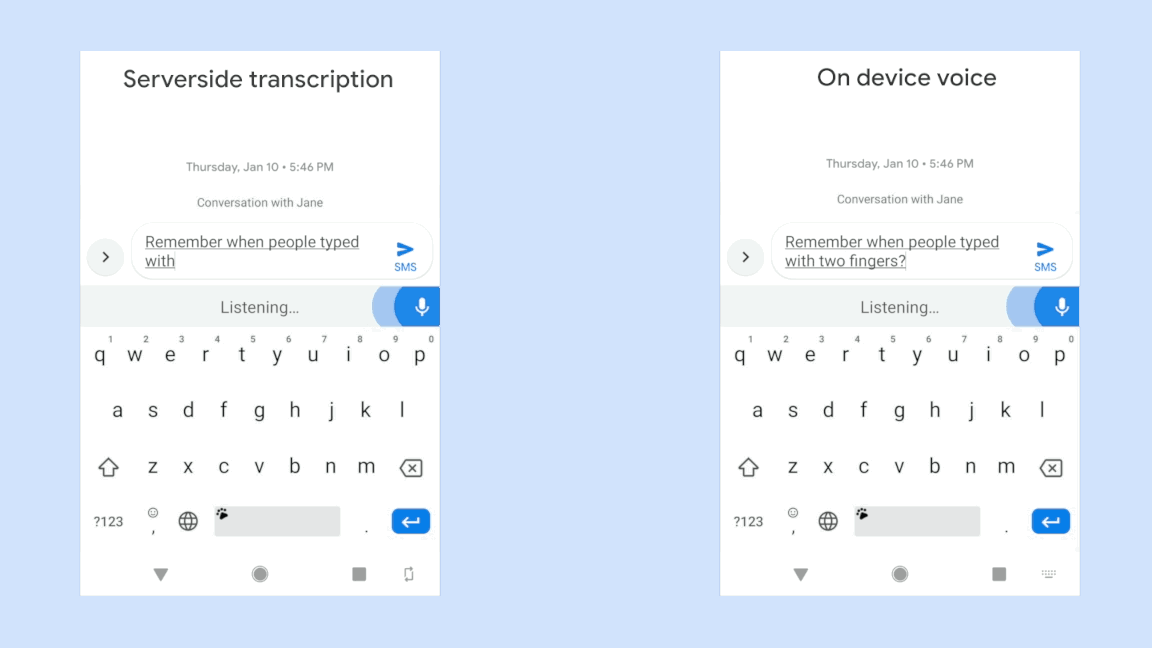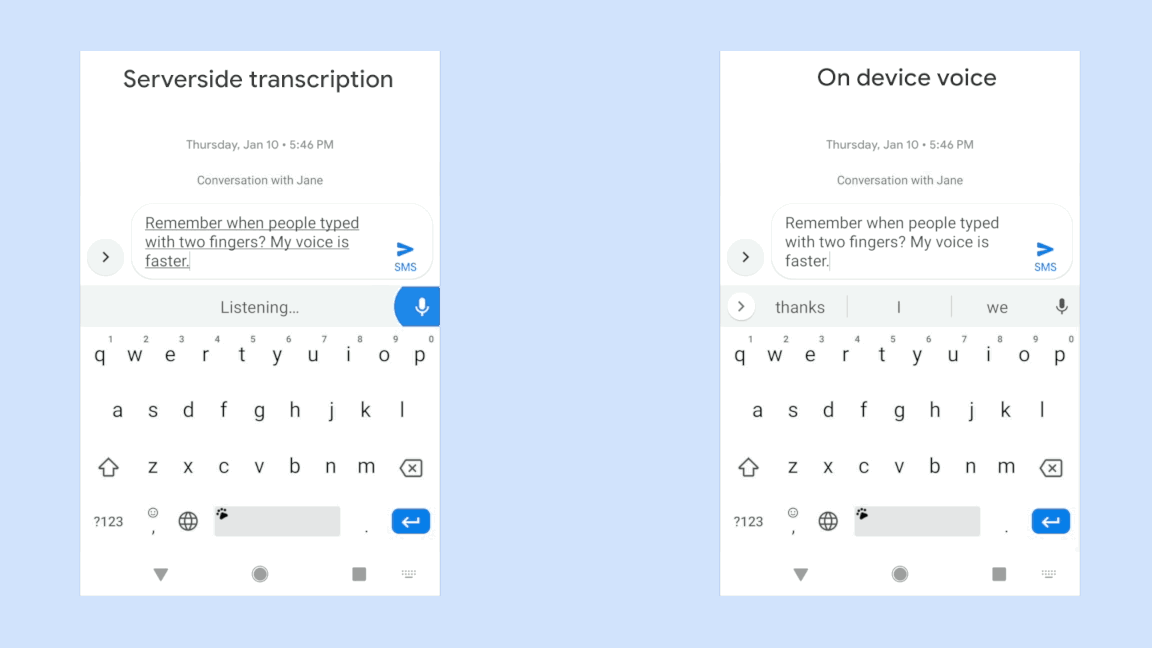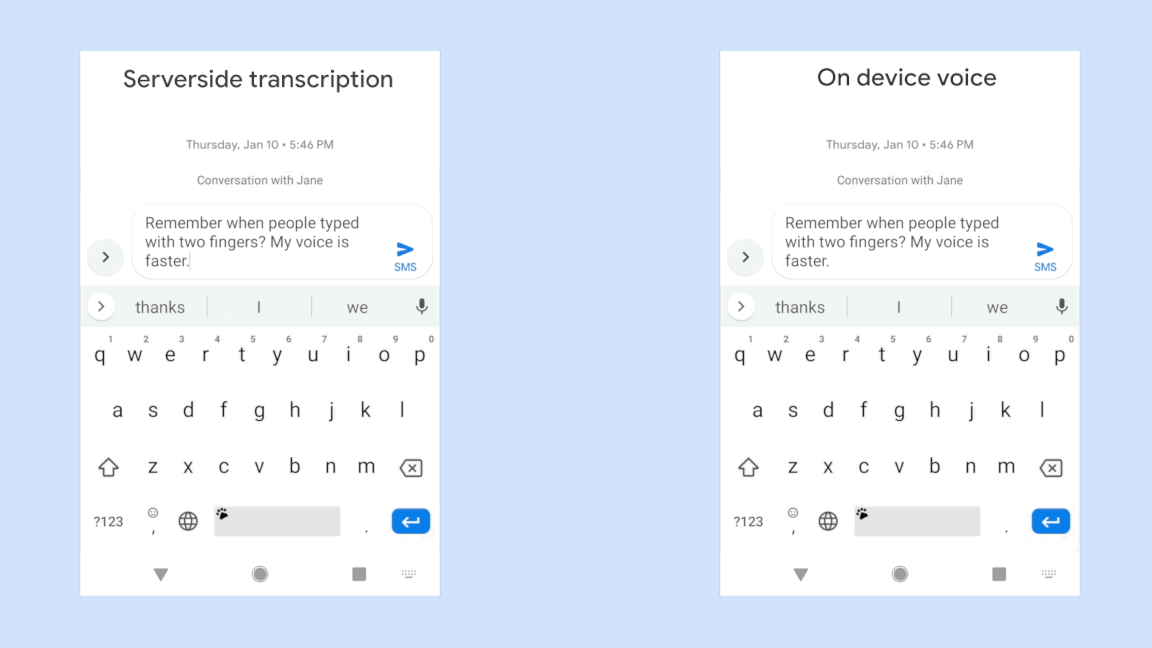
你只需要说出你的查询,它会立刻被转录下来,并直接显示。它听到了你的声音后会立刻响应,而不用等到你完成整个句子再去揣测你的意思。
但目前它只在谷歌键盘应用程序Gboard中工作,只在Pixel上工作,而且它只适用于美式英语。
“考虑到行业趋势,随着专业硬件和算法改进的融合,我们希望这里介绍的技术可以很快用于更多语言和更广泛的应用领域。”谷歌写道。
