苹果详解HomePod远场语音识别,为何机器学习是重点?
日前,苹果的音频软件工程和Siri语音团队在公司名下的《机器学习期刊》栏目中发布了一篇博文,详细介绍了公司研究团队对HomePod智能扬声器上的Siri在远场环境中工作的优化方法。
远场语音识别是指在用户在房间复杂的布局中离HomePod相对较远的不同位置唤醒Siri,而实现该功能需要紧密地集成各种多通道信号处理技术以解决噪声、混响、回声等带来的影响,相比在iPhone上工作,Siri在远场环境中的工作原理更加复杂,技术上也存在更多的难点。
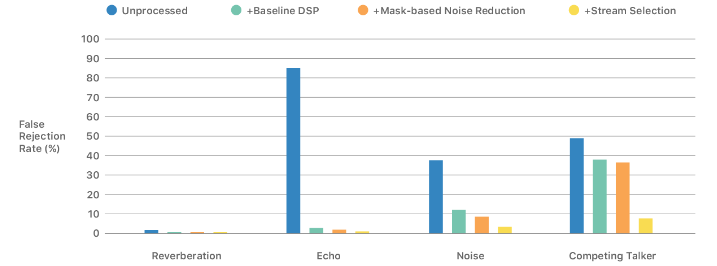
为了解决混响、噪声和语音分离的问题,苹果团队使用了多个麦克风阵列和机器学习的方法:
1)基于掩模的多通道同步采集硬件利用深度学习进行算法研发和调优来消除回声和背景噪声;
2)有语音重叠的情况下,利用无监督学习分离声源和基于音频流选择的语音唤醒消除干扰语音。
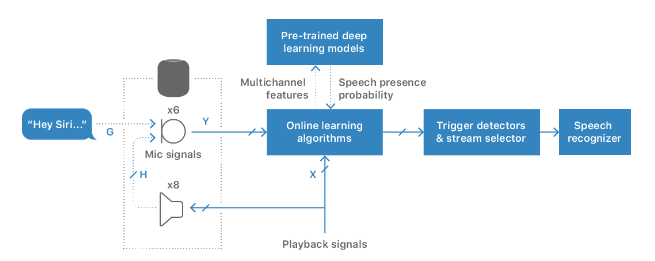
苹果团队搭建了一个系统,集成了监督式深度学习的模型和无监督在线学习的算法,能利用和处理多个麦克风信号,通过使用自上而下的知识为语音识别器从“Hey Siri”语音唤醒探测器中选择最合适的音频流。该团队表示,远场语音识别不断增强的性能得益于深度学习。
苹果在近几年把机器学习作为其研发工作的重点,iPhone A12和iPad Pro A12X上的神经引擎使芯片的性能不仅比此前的苹果设备搭载的芯片强大很多倍,同时也令其他竞争公司的SoC芯片逊色不少。
如今很多科技产品的营销宣传中都带有“机器学习”一词,以至令消费者觉得这是一个似乎没有什么意义的泛用词。相比之下,谷歌在这方面做得很好,经常利用博客让其用户与合作伙伴对机器学习有更深入的理解,显然苹果现在也在做同样的事情。
就目前而言,亚马逊和谷歌在数字助理技术方面处于市场领先地位。苹果尽管也有语音助手Siri,但与这些竞争对手相比其背后使用的方法的是不一样的,因此苹果要追赶上亚马逊和谷歌的步伐也并不容易。与用户最相关的是,苹果专注在本地计算机(用户的、或应用程序、或功能开发人员的)执行机器学习的任务,而不是在云平台。虽然苹果Core ML API也允许开发人员在云外部的网络中使用,安卓设备也可以进行本地处理(如照片),但这两者的重点不同。
苹果今年初推出的HomePod虽然具备出色的音质和Siri的即时响应,但该设备对Spotify支持的缺乏和不低的价格成为影响消费者选择的掣肘,值得一提的是,苹果在此前的季度收益报告中也未明确说明HomePod单独的出货量。
