探索如何通过向AI提供大量药丸图像来训练AI检测定制药丸
磐创AI你有没有听说过有人用人工智能来解决他们的行业问题,比如医生用人工智能来识别癌细胞,闭路电视识别货架上的产品,甚至是猫检测器?这些“AI”背后的基本逻辑是自定义对象检测。
在这个故事中,我们将探索如何通过向AI提供大量药丸图像来训练AI检测定制药丸。(不到30分钟!)
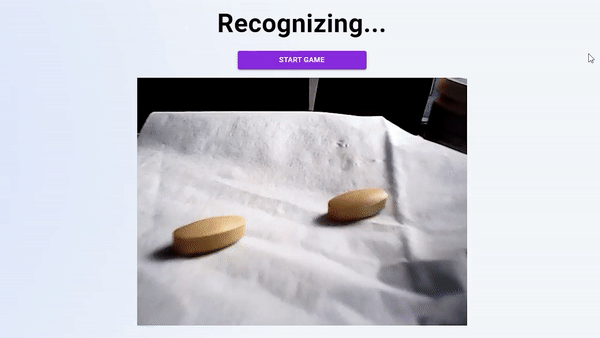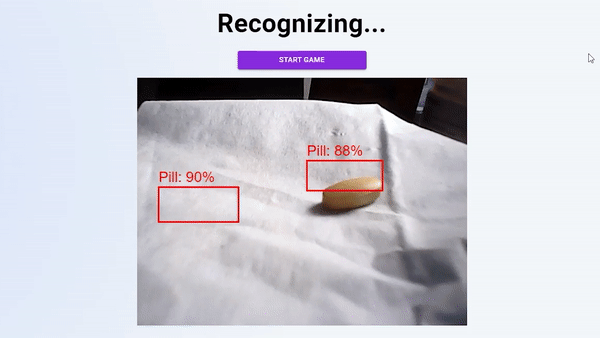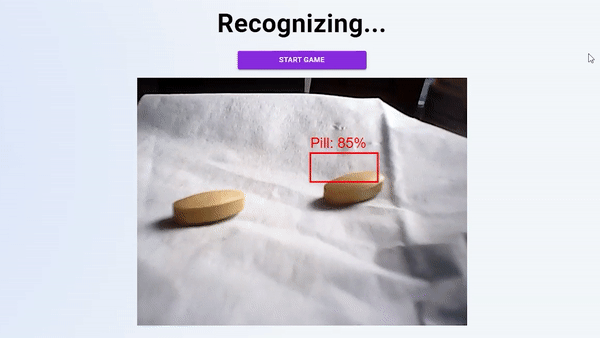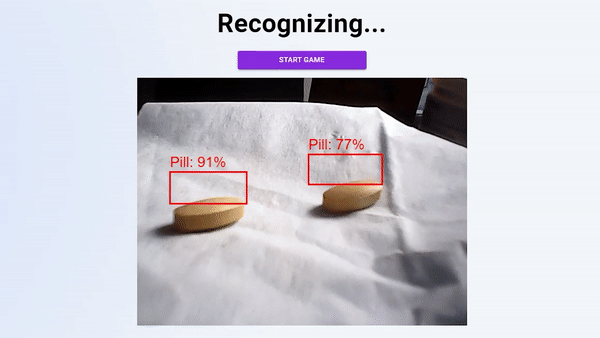
你可以在家里用一颗简单的黄色药丸在这里玩,或者访问这里的代码:https://github.com/manfye/react-tfjs-azure-objDetect。目标检测目标检测是一项计算机视觉任务,涉及两项主要任务:在图像中定位一个或多个对象,以及对图像中的每个对象进行分类图像分类与目标检测(分类和定位)。

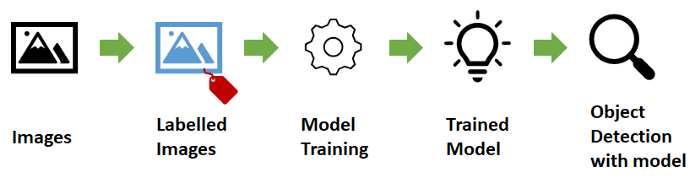
与图像分类(图2)相反,对象检测的目标是通过边界框和定位对象的类别来预测对象在图像中的位置,输出可以超过1个类别。自定义对象检测目前,在线提供各种预训练的模型,如COCO-SSD,它能够检测80多种常用对象,如检测人、铅笔和智能手机。但是,这个模型不能满足检测定制对象的需要,例如,我是一名药剂师,我想制作一个能够在网络摄像机中检测和计数药丸的web应用程序。传统上,要训练自定义对象,你需要将标签图像尽可能多地输入训练框架,如tensorflow和pytorch。然后运行该框架,以获得能够检测对象的最终训练模型。训练自定义对象检测模型的流程:
目前,最先进的方法是使用Pytorch和tensorflow等训练框架来训练模型,但这种方法存在许多缺点,如计算密集、设置时间长、图形卡要求高,不适合初学者。因此,出现了商业(可用的免费层)方法来训练模型。在本文中,我将展示如何使用Microsoft Azure Custom Vision方法来训练tensorflow.js对象检测模型,只需单击几下。目标检测模型训练Custom Vision是一项人工智能服务,是Microsoft Azure应用计算机视觉的端到端平台。它为Azure用户提供了一个免费的层来训练他们的对象检测或图像分类器模型,并将其作为API。对于免费层,它允许每个项目有多达5000张训练图像,足够大,可以检测少数几类对象。Azure自定义Vision的定价:

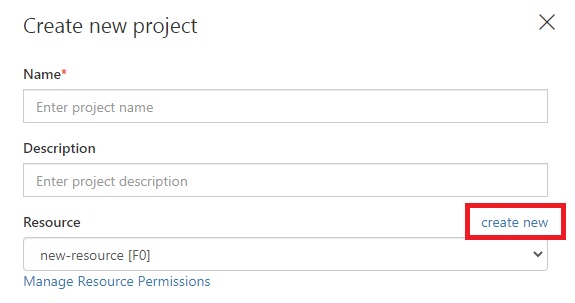
注册完成后,单击“新建项目”,单击“新建”以创建新产品。创建新项目:
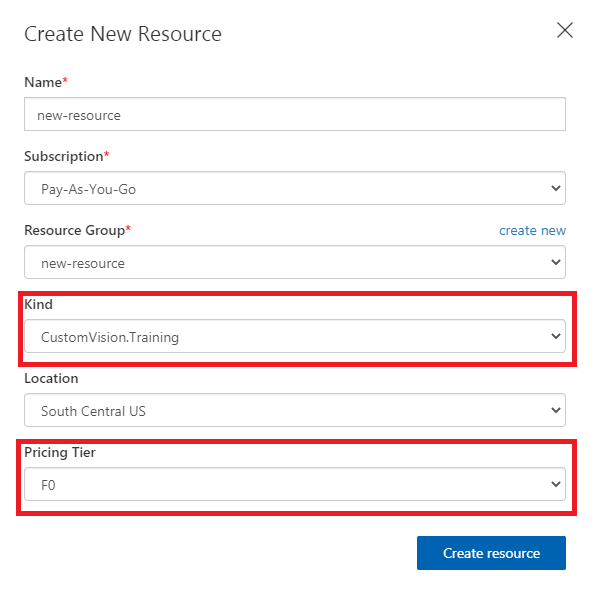
然后,创建一个新的资源组并选择种类:“CustomVision,Training”和“F0”,以使用CustomVision Training的免费层创建新资源:
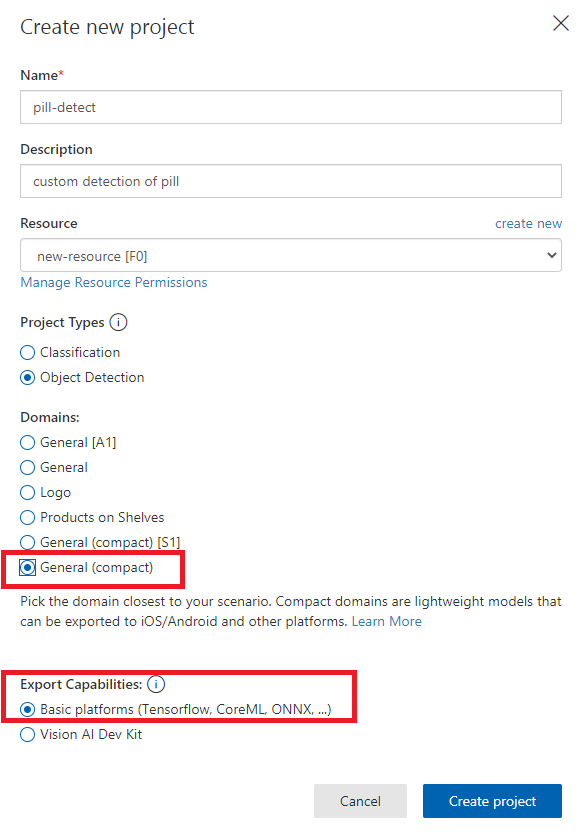
回到“创建新项目”页面,你会注意到,一旦你选择了资源,你就可以选择项目类型和域,选择“Object Detections”和 General (compact)。通过选择压缩,Microsoft Azure允许你以各种格式下载经过训练的模型。
你将到达如下图所示的训练平台,单击图像上传。自定义视觉训练平台:
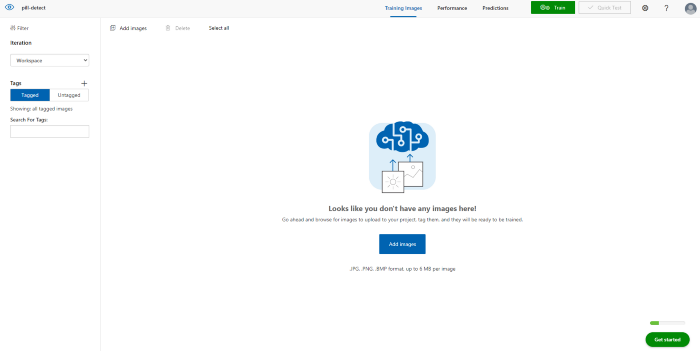
上传未标记的图像以进行标记。对于本文,我的药丸图像资源就在这里。[2]就我的案例而言,我上传了大约50-100张用于训练的图像。
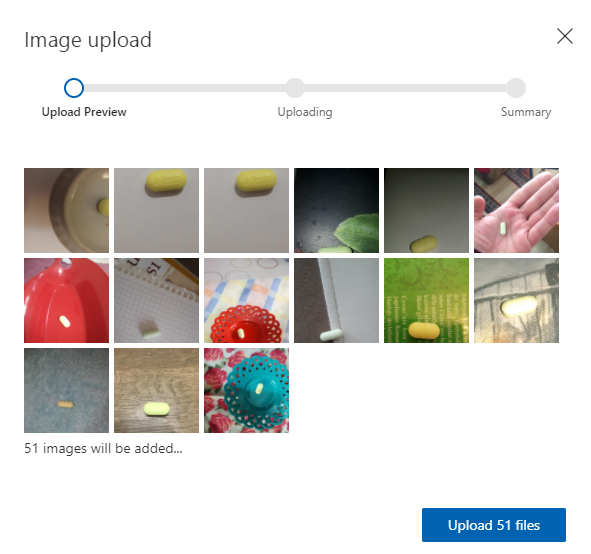
接下来,逐个标记图像(这是一个乏味的部分),幸运的是,Custom Vision确实为你提供了一个非常用户友好的标记工具,可以简化标记过程。

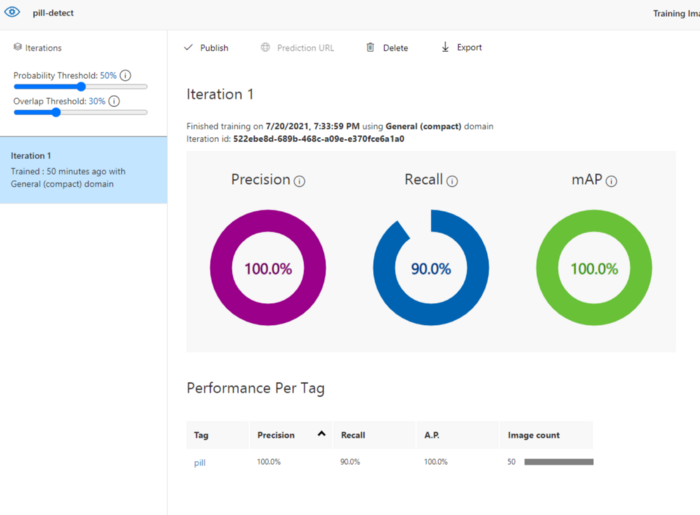
完成标记后,单击“Train”按钮并等待几分钟,你将得到以下结果:训练结果:
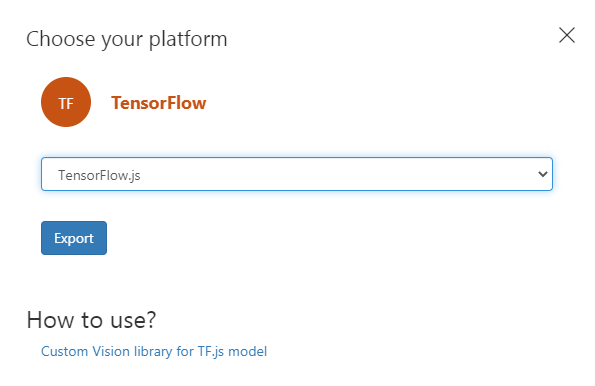
单击导出并选择Tensorflow,然后选择Tensorflow.js导出。恭喜,你在Tf.js中拥有了第一个自定义对象检测模型输出经过训练的模型:
使用React with Tensorflow.js检测自定义对象
1.设置你的CreateReact应用程序
通过终端中的以下命令创建Create React应用程序:
npx create-react-app tfjs-azureObject
cd tfjs-azureObject
安装tensorflow.js和Microsoft Customvision,如下所示:
npm install @tensorflow/tfjs
npm install @microsoft/customvision-tfjs
安装react-webcam,如下所示:
npm install react-webcam
然后启动应用程序npm start
所有的代码只会出现在App.js中,我只会显示重要的代码,完整的代码可以参考我的GitHub存储库
2.导入所需的包
import React, { useEffect, useState, useRef } from "react";
import Webcam from "react-webcam";
import * as cvstfjs from "@microsoft/customvision-tfjs";
3.构建用户界面
此项目的UI包括:
按钮-用于启动检测画
布-用于绘制边界框,以及
网络摄像头-用于输入图像/视频//
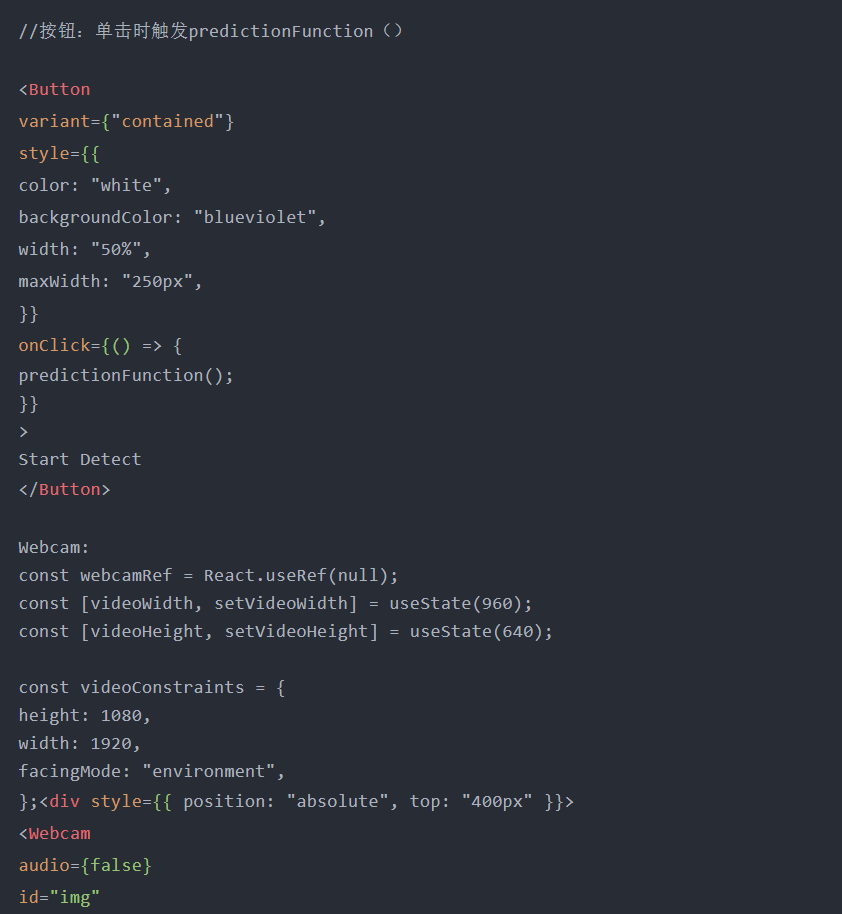
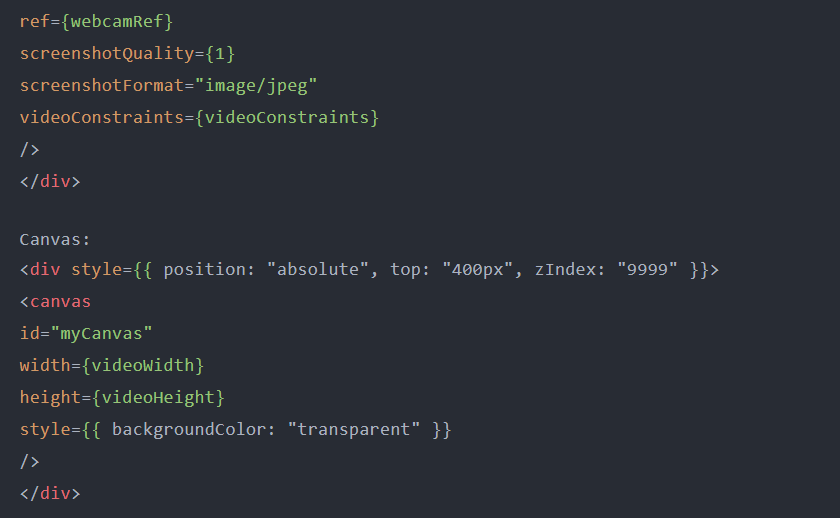
注意:画布和网络摄像头必须具有相同的大小和位置,才能在HTML画布中进行绘制。
4.加载模型
将下载的模型提取到“Public”文件夹中,确保model.json与weights.bin一起正确放置在/model.json路径中。要使用模型进行预测,代码为:
async function predictionFunction() {
setVideoHeight(webcamRef.current.video.videoHeight);
setVideoWidth(webcamRef.current.video.videoWidth);
// 测试azure vision api
let model = new cvstfjs.ObjectDetectionModel();
await model.loadModelAsync("model.json");
const predictions = await model.executeAsync(
document.getElementById("img")
);
但是,当预测的类必须显示在照片中时,事情会变得复杂,这就是使用HTML画布的原因。整个预测功能如下所示:
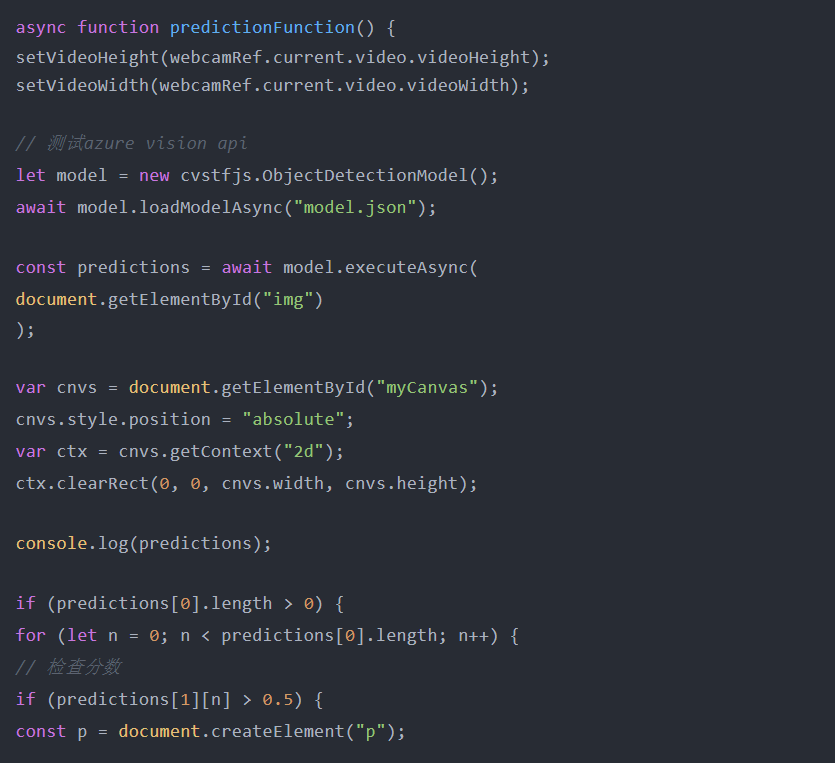
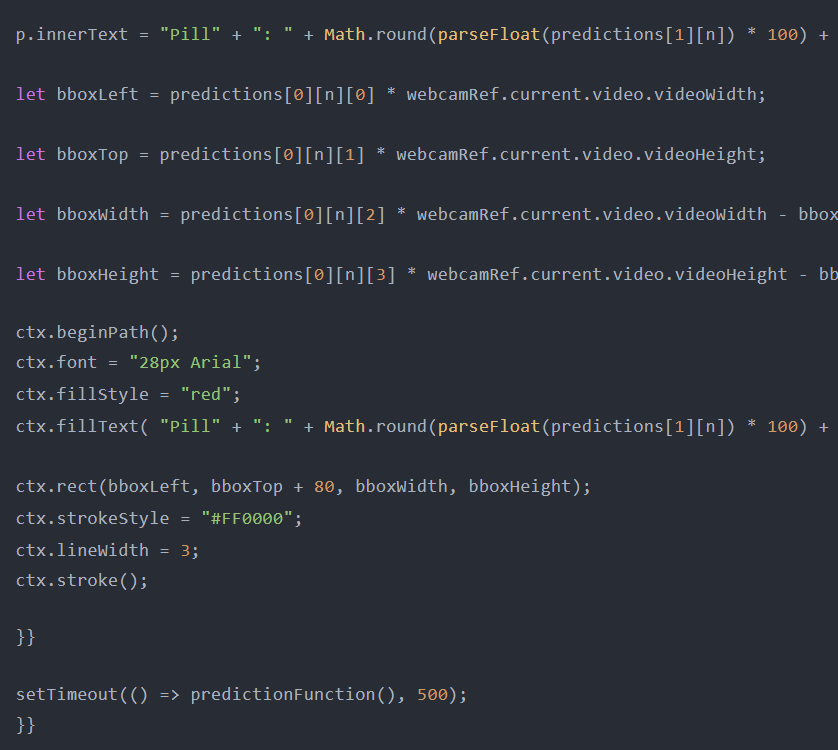
此函数将创建一个边界框,在该框上方显示检测到的对象类。它包括4个部分,其中第一部分是清除绘制的HTML画布,然后启动对象的模型检测。
如果模型检测到对象,模型将返回预测数据。通过使用边界框数据,我们可以使用HTML画布绘制边界框。然后,500毫秒后重新运行整个功能。
最后
在本文中,我们将介绍如何使用Microsoft custom Vision层创建自定义对象检测模型,这将大大减少创建自定义对象检测模型的工作量和障碍(我认为减少了80%)。然后,我们使用react将该模型合并到Tensorflow.js中,并用不到100行代码对整个web应用程序进行编码。
每个行业对自定义对象检测的需求都很高,在本文中,我用创建了一个药丸计数器,希望在了解自定义检测技术后,它可以启发你为你的行业创建更多的工具。
