ECCV 2020 | 基于对抗路径采样的反事实视觉语言导航
将门创投
本文将分享加州大学助理教授王鑫和王威廉等人在ECCV spotlight的工作。为了实现VLN智能体,不仅需要学习理解语言语义和视觉环境,同时还要适应视觉语言交互情况下的动态变化,研究人员提出了一种对抗驱动的反事实思考方法。模型通过学习评价有效的反事实条件来代替采样充分但信息不足的数据,最终形成了一种比随机采样路径方法更为有有效的对抗策略。

视觉语言导航(Vision-and-language navigation, VLN)是机器人基于自然语言指令在3D环境中进行移动以到达目标的任务。它不仅需要理解自然语言信息,同时还需要将周围环境的视觉信息进行编码,在语言指令的引导下利用场景的关键特征来向目标位置移动。
为了实现VLN智能体,不仅需要学习理解语言语义和视觉环境,同时还要适应视觉语言交互情况下的动态变化。这一复杂的任务所面临的最大困难在于训练数据的稀缺性。例如在Room-to-Room(R2R)数据集中包含了超过二十万条可能的路径,但数据集中却只有大约一万四千条采样路径。如此稀缺的数据使得智能体在交换环境中学习语言和视觉任务的优化匹配问题变得十分困难。
而对于人类来说,通常缺乏结合视觉感知和语言指令来对不熟悉的环境进行探索的能力,然而人类的思维还是可以利用反事实推理来完善缺失的信息。例如,如果人类按照“右转”的指令但看到了门挡在前面,人们就会自然而然的思考要是左转会遇到什么情况;如果我们停在餐桌前而不是径直走过,那么指令应该是什么样的呢?我们可以看到反事实推理可以通过探索并考量可能的行为方式(并没有实际发生,类似于设想)来改进VLN任务的表现。这可以使得主体在数据缺乏的场景下通过环境的引导熟悉(bootstrapping familiarity)和指令与多个行为策略选项中的联系来进行有效操作。
反事实思考已经被用于多种任务来增强模型的鲁棒性,但还没有显式的反事实模型被针对性地用于VLN任务中。虽然有像Speaker-Follower这样的方法对训练样本进行了增强,但随机采样方法太任意了。下图展示了基于随机采样增强数据训练的模型性能随增强比例的变化,可以看到在60%以后性能几乎就不再增加。这是由于这些路径都是随机采样的,限制了反事实思考对于数据增强的所带来的提升。
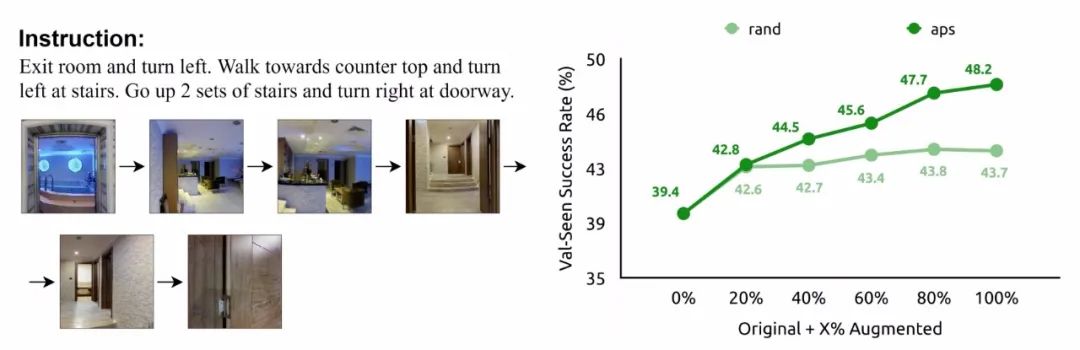
随机采样和APS采样的对比,可以看到随机手段对性能的提升会遇到瓶颈。
在这篇论文中,研究人员提出了一种对抗驱动的反事实思考方法,模型通过学习评价有效的反事实条件来代替采样充分但信息不足的数据。研究人员首先引入了模型未知的对抗路径采样器(adversarial path sampler, APS)来生成富有挑战并有效的增强路径,作为目标导航模型的训练样本。在对抗训练过程中,导航器尝试着去完成APS生成的路径并更好地优化导航策略,而APS的目标则在于不断生成更具挑战性的路径。这种对抗策略比随机采样路径方法更为有有效。
此外在APS的增强下,模型对于陌生场景和未知场景具有更好地适应性,实现基于环境的预探索机制。这样在进入新环境后,机器人可以首先对其进行预探索并熟悉环境,随后在自然语言的引导下完成任务。在R2R数据集上的结果表明APS可以被集成到多种VLN模型中,大幅提升已知和未知环境中的性能。
1 2 3 下一页>
