ECCV 2020 | Post-Training Quantization
学术头条ECCV 2020 已经拉开帷幕!今天,小编要给大家分享的是来自三星团队的 Oral Presentation:
标题: Post-Training Piecewise Linear Quantization for Deep Neural Network
作者:Jun Fang, Ali Shafiee, Hamzah Abdel-Aziz, David Thorsley, Georgios Georgiadis, Joseph Hassoun

近年来深度神经网络在很多的问题中,通过加大模型的深度、宽度或分辨度,取得了越来越高的精度。但与此同时也增加了模型的计算复杂度和内存需求,从而导致在资源有限的嵌入式设备上来部署这些模型应用变得更加困难。
量化 (Quantization)是一种非常实际有用的压缩和加速模型的方法。它通过转换模型的 32 位浮点(FP32)weights和activations到低精度的整数(比如 INT8),从而通过整数运算来近似原始的浮点运算模型达到压缩和加速的效果。
然而在具体的实际应用中,Post-Training Quantization 是非常重要的。因为它不需要重新训练模型的参数,所以节省了非常耗费资源的调参过程;同时它也不需要访问训练数据,从而保护了数据的隐私性。在 Post-Training Quantization 的研究工作中,Uniform Quantization 是最受欢迎的方法。众多研究表明,8-bit Uniform Quantization 就可以保持大部分的模型精度,但是如果降到 4-bit,精度会有非常显著的损失。
此篇文章就是分析了 4-bit 精度损失的具体原因,并提出了他们的 Piecewise Linear Quantization(PWLQ)的方法来显著的提高量化后模型的精度。如下图所示,训练完的模型的 weights 的分布并不是平均分布,而是近似于高斯分布:绝大多数的 weights 都集中于中心地带,而少数的 weights 分散在稀疏的连边上。可想而知,Uniform Quantization 对于这种分布的近似残差不是最优的。而 PWLQ 把分布区间分为没有重叠的 center 和 tail 两部分,每部分分配相同的量化格点数。这样一来会导致中间部分的近似精度提高,而两边的近似精度下降,但因为绝大部分的 weights 都分布在中间部分,所以整体的近似精度还是会得到提高。
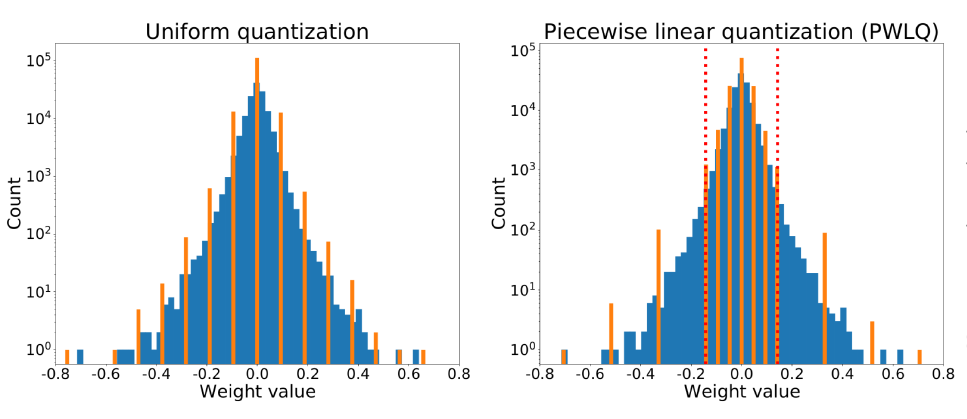
接下来,问题的关键在于怎么找到最优的区分点(breakpoint),PWLQ 是通过最小化这种分布的近似残差来得以选取。文章提供了具体的理论证明和下图的数值模拟:近似的残差是关于区分点的凹函数(Convex Function),所以这个最优区分点是唯一存在的。
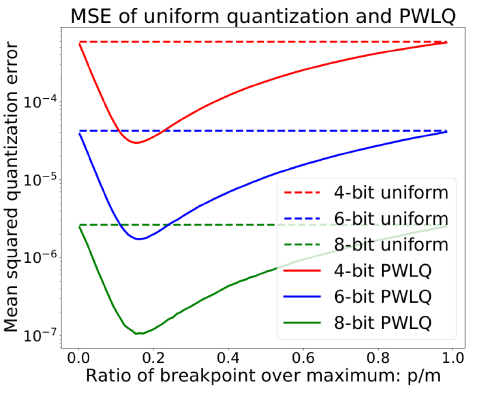
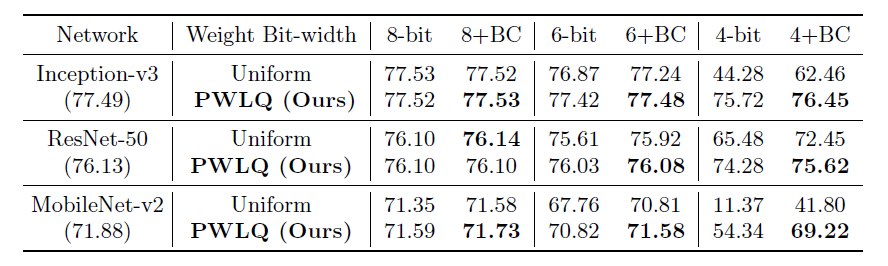
为了加快 Inference,文中提供了找到区分点的 one-shot 的公式。在数值实验中,如下图的三种模型 Inception-v3,ResNet-50 和 MobileNet-v2 在 ImageNet 的结果上,PWLQ 比 Uniform Quantization 有着明显的更高精度。尤其在 4-bit MobileNet-v2 的对比上,PWLQ 有高出 27.42% 的精度,由此可见 PWLQ 有着更强大的 representational power。
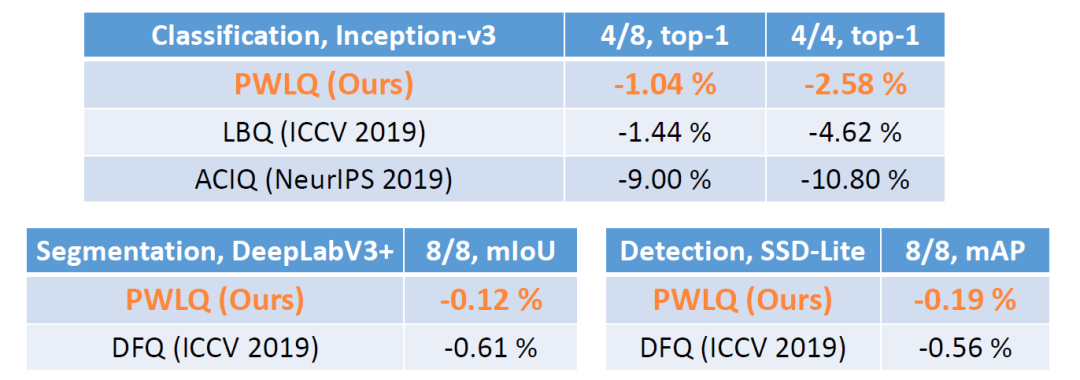
同时文中也做出了 PWLQ 和其他 state-of-the-art 的方法对比。如下图所示,在 4/8 的情况下,PWLQ 比 LBQ(ICCV 2019)和 ACIQ(NeurIPS 2019)分别取得 0.40% 和 7.96% 的更高精度;在 4/4 的情况下,PWLQ 获得更高精度的优势更加显著。与此同时,PWLQ 不仅在 classification 的任务中取得好结果,在 segmentation 和 detection 任务上也得到了相似的好结果。
最后让笔者感到欣喜的是文中不仅仅有展示 PWLQ 取得更好精度的优势所在,同时也有真诚讨论 PWLQ 的不足之处。比如,PWLQ 的具体硬件实现中会带来一定的额外消耗,下图是作者给出的关于硬件 Latency 和 Energy 的具体模拟参数来说明这些额外消耗是可以接受的。


