什么是文本摘要?为什么要有注意力机制?
深度学习 视觉什么是NLP中的文本摘要
自动文本摘要是在保持关键信息内容和整体含义的同时,生成简洁流畅的摘要的任务。 文本摘要目前大致可以分为两种类型:
Extractive Summarization:重要内容、语句提取。
Abstractive Summarization:文本总结。
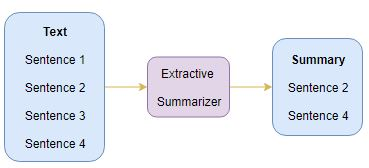
Extractive Summarization
由图可以看出,这种方法提取的内容语句来自于原文。
Abstractive Summarization
由图可以看出,这种方法提取的内容语句可能不存在于原文。

Seq2Seq模型
Seq2Seq模型可以处理一切连续型信息,包括情感分类,机器翻译,命名实体识别等。 机器翻译任务中,输入是连续文本序列,输出也是连续文本序列。 命名实体识别中,输入是连续文本序列,输出是连续的标签信息。 所以,我们可以利用Seq2Seq模型,通过输入一段长文本,输出短的摘要,实现文本摘要功能。 下图是典型的Seq2Seq模型架构:
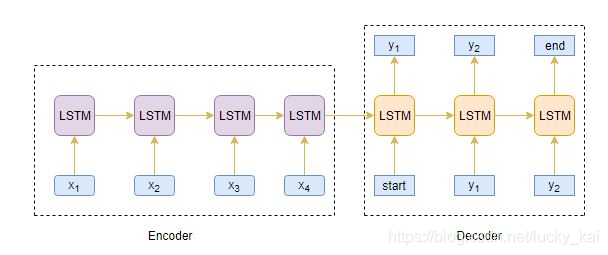
通常我们可以选择RNNs网络的变体GRU或者LSTM,这是因为它们能够通过克服梯度消失的问题来捕获长期依赖性。
Encoder编码器
LSTM中的Encoder读取整个输入序列,其中每个时间step上,都会有一个字输入编码器。然后,他在每个时间step上处理信息,并捕获输入序列中存在的上下文信息。
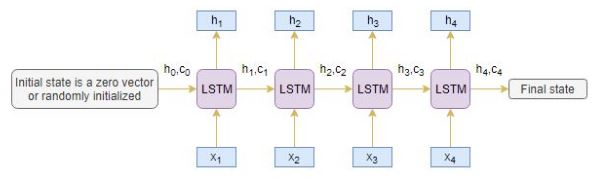
上一个时间step的隐藏层h1与记忆单元层c1将会用来初始化Decoder。
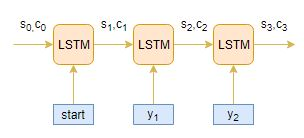
Decoder解码器
Decoder是LSTM结构的另一部分。它逐字读取整个目标序列,并以一个时间步长预测相同的序列偏移量。 解码器可以在给定前一个单词的情况下预测序列中的下一个单词。解码器的初始输入是编码器最后一步的结果。
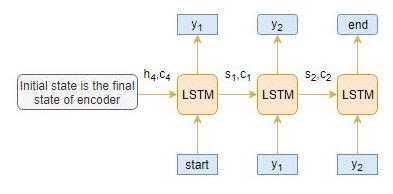
在将整个目标序列放入解码器前,还需将[start] 与 [end]这两个特殊的tokens加入序列中,告知模型的开始与结束。模型通过输入的[start]开始预测第一个词,而[end]则表示整个句子的结束。
Deocder的工作流程
假设输入序列为[x1,x2,x3,x4],将其编码成内部固定长度的向量。 下图显示了每一个time step下Decoder是如何工作的。
1 2 3 下一页>
