教程:基于python的MongoDB
磐创AI总览
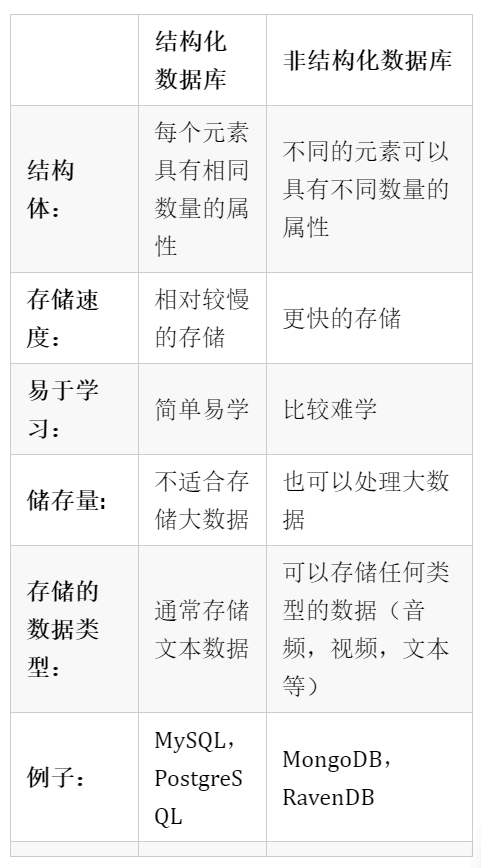
MongoDB是数据科学家常用的一种非结构化数据库
本文我们讨论如何使用Python(和PyMongo库)来使用MongoDB数据库。
本文我们使用Python实现对MongoDB数据库的所有基本操作
结构化数据库面临的挑战
如今我们正在正以前所未有的速度产生数据,这些数据的规模和大小令人难以置信!如下:
Facebook在一天之内就生成了4PB的数据
Google每天产生20PB的数据
此外,大型强子对撞机(27公里长,是世界上功能最强大的粒子加速器)每秒可生成1PB的数据。最重要的是,这些数据是非结构化的
如果使用SQL来处理这些大量数据会让自己陷入噩梦中!
SQL是作为数据科学家学习的一种很棒的语言,当我们处理结构化数据时,它确实能很好地工作,但是,如果你使用非结构化数据,则SQL数据库是无法满足需求的。
结构化数据库有两个主要缺点:可扩展性:随着数据库的扩大,很难扩展
弹性:结构化数据库需要预定义数据的格式,如果数据未遵循预定义的格式,则关系数据库不会存储该数据
那么我们如何解决这个问题呢?如果不用SQL,那又怎么解决这些问题?
这就是我们用到非结构化数据库的地方了。在广泛的数据库中,MongoDB因其丰富的查询语言和对索引等概念的快速访问而被广泛使用。简而言之,MongoDB最适合管理大数据。让我们看看结构化和非结构化数据库之间的区别:
目录
什么是MongoDB?
MongoDB数据库的架构
了解问题陈述
什么是PyMongo?
MongoDB安装指南
MongoDB数据库的基本操作
连接到数据库
检索/获取数据
插入
过滤条件
删除
创建数据库和集合
将获取的数据转换为结构化形式
存储到DataFrame
写入文件。
其他有用的功能
1.什么是MongoDB?

MongoDB是一个非结构化数据库,它以文档形式存储数据。MongoDB能够非常高效地处理大量数据。因为它提供了丰富的查询语言以及对数据的灵活而快速的访问,所以MongoDB是使用最广泛的NoSQL数据库。
在进入本教程的重点之前,让我们花一点时间来了解MongoDB数据库的体系结构。
MongoDB数据库的架构
MongoDB中的信息存储在文档中,这里文档类似于结构化数据库中的行。
每个文档都是键值对的集合
每个键值对称为一个字段
每个文档都有一个_id 字段,用于唯一标识文档
文档也可以包含嵌套文档
文档可以具有不同数量的字段(它们也可以为空白)
这些文档存储在一个集合中。集合实际上是MongoDB中文档的集合,这类似于传统数据库中的表。

与传统数据库不同,MongoDB的数据通常存储在MongoDB中的单个集合中,因此没有连接的概念($lookup运算符除外,该运算符执行左外联接之类的操作)。MongoDB拥有嵌套文档。
2.了解问题陈述让我们了解会在本教程中解决的问题,这会使你对可以对MongoDB实践有一个更好的了解,以进一步磨练MongoDB的Python技能。
假设你正在为一个向客户提供一个银行系统的应用程序,该应用程序将数据发送到你的MongoDB数据库中。此数据存储在三个集合中:
accounts集合-包含有关所有帐户的信息
customers集合-包含有关客户的信息
transactions集合-包含客户事务数据
我已从全球云数据库服务MongoDB Atlas取得了本教程的示例数据库。
我们将使用“ sample_analytics”数据库来处理上述的问题,该数据库包含与金融服务有关的数据。
3.什么是PyMongo?
PyMongo是一个Python库,使我们能够与MongoDB连接,以及使我们能够对MongoDB数据库执行基本操作。
那么,为什么要使用Python?
我们选择Python与MongoDB进行交互是因为它是数据科学中最常用且功能最强大的语言之一。PyMongo允许我们使用类似于字典的语法来检索数据。
同时我们还可以使用点表示法来访问MongoDB数据,它简单的语法使我们的工作变得容易得多,此外PyMongo有丰富的帮助文档。我们使用该库来访问MongoDB。
4. MongoDB安装指南
MongoDB可用于Linux,Windows和Mac OS X操作系统。
安装数据库后,需要启动mongod 服务。如果你在安装过程中遇到任何问题,可以随时在本文下面的评论部分与我联系。
5. MongoDB数据库的基本操作现在我们对MongoDB已经有了一个很好的概念——让我们把这些知识付诸行动吧。
我们将使用PyMongo库对Python中的MongoDB数据库执行一些关键的基本操作。
5.1连接到数据库
要从MongoDB数据库检索数据,我们将首先需要连接到它。在Jupyter单元中编写并执行以下代码,以连接到MongoDB:import pymongo
import pprint
mongo_uri = "mongodb://localhost:27017/"
client = pymongo.MongoClient(mongo_uri)
让我们看看可用的数据库:client.list_database_names()
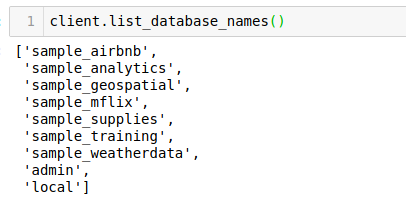
我们将使用sample_analytics数据库来实现我们的目的,让我们将游标设置为相同的数据库:db = client.sample_analytics
该list_collection_names命令显示所有可用的集合名称:db.list_collection_names()

让我们看看我们有多少客户。我们将连接到客户集合,然后打印该集合中可用的文档数量:table=db.customers
table.count_documents({}) #gives the number of documents in the table
输出:500在这里,我们可以看到有500个客户的数据。接下来,我们将从该表中获取MongoDB文档,并查看那里提供了哪些信息。5.2 检索/获取数据我们可以使用类似字典符号或PyMongo中的点运算符来查询MongoDB。在上一节中,我们使用了点运算符来访问MongoDB数据库,在这里,我们使用类似字典的语法进行演示。首先,让我们从MongoDB集合中获取一个文档,我们为此使用find_one函数:table.find_one()
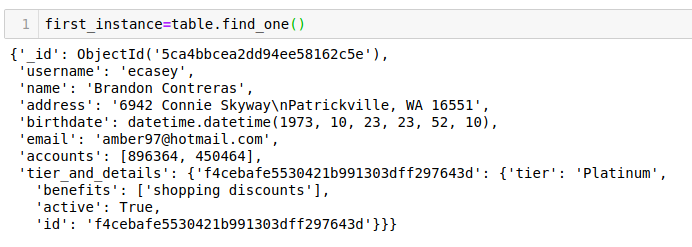
我们可以看到该函数返回了一个字典。让我们看一下该字典的键。first_instance.keys()

我们可以看到一些键是不言自明的,让我解释一下每个密钥存储的内容:_id:MongoDB为每个文档分配一个唯一的IDusername :包含用户的用户名name:用户名address:用户的地址存储在此字段中birthdate:此参数存储用户的出生日期email:这是给定用户的电子邮件IDactive:此字段告诉用户是否活跃address:它存储给定用户拥有的所有帐户列表,一个用户可以有多个帐户teir_and_details:类别(银,金等)存储在此参数中,该字段还存储他们有权获得的利益现在,让我们看一下MongoDB的字典式访问示例。让我们从MongoDB文档中获取客户的名称:first_instance['name']

我们还可以使用find函数来获取文档,find_one一次仅获取一个文档,另一方面,find可以从MongoDB集合中获取多个文档:table.find().sort("_id",pymongo.DESCENDING)
在此,sort函数以_id的降序对文档进行排序。5.3插入功能insert_one函数可用于一次在MongoDB中插入一个文档。我们首先创建一个字典,然后将其插入MongoDB数据库中:post = {"_id": 'qwertyui123456',
'username': 'someone',
'name':'Gyan',
'address':'Somewhere in India'}
post_id = table.insert_one(post).inserted_id
post_id
输出:qwertyui123456MongoDB是一个非结构化数据库,因此集合中的所有文档都不必遵循相同的结构。例如,在上述情况下插入的字典不包含我们在先前获取的MongoDB文档中看到的一些字段。.inserted_id提供了默认分配的 _id字段(如果字典中未提供它)。就我们而言,我们已明确提供了该字段,最后,该操作返回插入的MongoDB文档的 _id。在上述情况下,它存储在 post_id变量中。到目前为止,我们实现了在MongoDB集合中插入一个文档。如果必须一次插入数千个文档,该怎么办?为解决这个问题,我们引入insert_many函数:import datetime
new_posts = [{"name": "Mike",
"username": "latestpost!",
"date": datetime.datetime(2009, 11, 12, 11, 14)},
{"name": "Eliot",
"title": "onceAgain",
"text": "and pretty easy too!",
"date": datetime.datetime(2009, 11, 10, 10, 45)}]
final = table.insert_many(new_posts)
final.inserted_ids

我们导入了datetime库,因为Python中没有内置的日期和时间数据类型,该库可以帮助我们分配datetime类型的值。在上述情况下,我们在MongoDB数据库中插入了词典列表,每个元素都作为独立文档插入MongoDB集合中。5.4过滤条件我们已经看到了如何使用find和find_one函数从MongoDB中获取数据,但是,在某些场景下,我们不需要获取所有的文档信息,所以我们需要用到过滤条件来过滤文档。之前,我们在MongoDB集合中插入了一个名为Gyan的文档,现在让我们看看如何使用筛选条件获取MongoDB文档:table.find_one({"name":'Gyan'})

在这里,我们使用一个字符串参数name来获取文档。另一方面,我们在前面的例子中看到了final,nserted_id包含插入文档的id。如果我们对 _id字段应用筛选条件,它将不返回任何内容,因为它们的数据类型是ObjectId,这不是内置数据类型。我们需要将字符串值转换为ObjectId类型,以便对 _id 应用筛选条件。首先,我们将定义一个函数来转换字符串值,然后获取MongoDB文档:from bson.objectid import ObjectId
post_id=final.inserted_ids[0]
def parser(post_id):
document = table.find_one({'_id': ObjectId(post_id)})
return document
parser(post_id)

5.5 删除delete_one函数从MongoDB集合中删除单个文件。上文我们是为名为Mike的用户插入文档的。让我们看一下插入的MongoDB文档:table.find_one({'name':'Mike'})
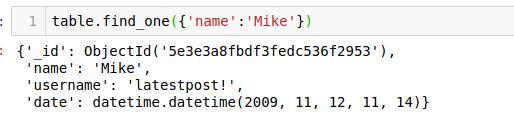
现在,我们将删除此MongoDB文档:table.delete_one({'name':'Mike'})

让我们尝试在删除后获取此文档,如果我们的MongoDB集合中没有此文档,则find_one函数将不返回任何内容。table.find_one({'name':'Mike'})
输出:不返回任何内容。由于我们没有得到任何回复信息,这意味着MongoDB文档不再存在。正如我们看到的,insert_many函数用于在MongoDB集合中插入多个文档,delete_many用于一次删除多个文档。让我们尝试通过名称字段删除两个MongoDB文档:myquery = ({ "name":{"$in": ["Gyan","Eliot"]}})
x = table.delete_many(myquery)
print(x.deleted_count, " documents deleted.")
在此,deleted count存储操作期间删除的MongoDB文档的数量。'$in'是MongoDB中的一个运算符。5.6 创建数据库和集合在MongoDB中,创建任何数据库和集合都是一个非常简单的过程,你可以使用检索语法来做到这一点,如果你尝试访问一个不存在的数据库,MongoDB将为你创建它。让我们创建一个数据库和一个集合:mydb=client.testDB
mycoll=mydb.testColl
已经在此处创建了MongoDB数据库,但是如果我们运行list_database_names,则不会列出该数据库,因为MongoDB不显示空数据库,因此,我们将不得不在其中插入一些内容。让我们在MongoDB集合中插入一个文档:testInsert=mycoll.insert_one({"country":'India'}).inserted_id
client.list_database_names()
现在我们可以看到我们的数据库在MongoDB数据库列表中是可用的。6.将非结构化数据转换为结构化形式作为数据科学家,你不仅需要获取数据,还需要对其进行分析。以结构化形式存储数据可简化此任务。在本节中,我们将学习如何将从MongoDB中获取的数据转换为结构化格式。6.1存储到DataFrame中find函数从MongoDB集合返回字典,你可以将其直接插入DataFrame。首先,让我们获取100个MongoDB文档,然后将这些文档存储到一个DataFrame中:import pandas as pd
samples=table.find().sort("_id",pymongo.DESCENDING)[:100]
df=pd.DataFrame(samples)
df.head()

该DataFrame的可读性远远优于该函数返回的默认格式。
6.2写入文件Pandas DataFrame可以直接导出为CSV,Excel或SQL。
让我们尝试将这些数据存储到CSV文件中:Pandas
同样,你可以使用to_sql函数将数据导出到SQL数据库。
7.其他一些有用的MongoDB函数你已经积累了足够的知识来开始使用MongoDB了,到目前为止,我们已经通过示例讨论了所有基本操作,同时我们还了解了MongoDB的几个理论概念。在完成本文之前,让我分享一些PyMongo的有用功能:sort:我们已经看到了此功能的示例,此功能的目的是对文档进行排序limit:此函数限制由find函数获取的MongoDB文档的数量
8. 接下来是什么?掌握了本教程中介绍的概念之后,你应该学习与MongoDB相关的更高级的主题,如下:索引:索引是在MongoDB中对集合的某些属性(字段)创建索引的过程,它使检索过程更快。在没有索引的集合中,当你尝试根据字段的给定条件筛选出特定文档时,它将扫描整个数据库。如果有数以亿计的文档,这个过程需要时间。
索引之后,MongoDB使用大量内存来存储索引信息,此索引允许你根据筛选条件跳转到特定文档,而无需扫描整个数据库分片:跨多台机器存储数据的过程称为分片,分片有助于数据库的水平扩展运算符:我们已经在MongoDB中看到了$in操作符,还有一些其他有用的运算符可以执行某些特定的功能结尾在本文中,我们学习了MongoDB的所有基本概念,这足以让你在非结构化数据库的学习上有一个坚实的开端。

