如何创建一个能够区分或识别图像的系统?
磐创AI介绍你是否曾经偶然发现一个数据集或图像,并想知道是否可以创建一个能够区分或识别图像的系统?图像分类的概念将帮助我们解决这个问题。图像分类是计算机视觉最热门的应用之一,是任何想在这个领域工作的人都必须知道的概念。

在本文中,我们将看到一个非常简单但使用频率很高的应用程序,那就是图像分类。我们不仅将看到如何使一个简单和有效的模型分类数据,而且还将学习如何实现一个预先训练的模型,并比较两者的性能。在本文结束时,你将能够找到自己的数据集并轻松实现图像分类。先决条件:Python编程Keras及其模块基本了解图像分类卷积神经网络及其实现迁移学习的基本认识听起来有趣吗?准备创建你自己的图像分类器吧!目录图像分类理解问题陈述设置图像数据让我们构建我们的图像分类模型数据预处理数据扩充模型定义和训练评估结果迁移学习的艺术导入基础MobileNetV2模型微调训练评估结果下一步是什么?什么是图像分类?图像分类是分配输入图像(一组固定类别中的一个标签)的任务。这是计算机视觉的核心问题之一,尽管它很简单,却有各种各样的实际应用。让我们举个例子来更好地理解。当我们进行图像分类时,我们的系统将接收图像作为输入,例如,一只猫。现在,系统将已知一组类别,它的目标是为图像分配一个类别。这个问题似乎很简单,但对于计算机来说却是一个很难解决的问题。你可能知道,电脑看到的是一组数字,而不是我们看到的猫的图像。图像是由0到255的整数组成的三维数组,大小为宽x高x 3。3代表红色、绿色、蓝色三个颜色通道。那么我们的系统如何学习识别这幅图像呢?通过卷积神经网络。卷积神经网络(CNN)是深度学习神经网络的一种,是图像识别领域的巨大突破。到目前为止,你可能已经对CNN有了一个基本的了解,我们知道CNN由卷积层、Relu层、池化层和全连接层组成。
要阅读关于图像分类和CNN的详细信息,你可以查看以下资源:https://www.analyticsvidhya.com/blog/2020/02/learn-image-classification-cnn-convolutional-neural-networks-3-datasets/
https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/
现在我们已经理解了这些概念,让我们深入了解如何构建和实现图像分类模型。理解问题陈述考虑下面的图像:

一个精通体育运动的人可以认出橄榄球的形象。图像的不同方面可以帮助你识别它是橄榄球,它可以是球的形状或球员的服装。但你有没有注意到,这张照片很可能是一个足球形象?让我们考虑另一张图片:

你认为这个图像代表什么?很难猜对吧?对于没有受过训练的人来说,这幅图像很容易被误认为是足球,但实际上,这是橄榄球的图像,因为我们可以看到后面的球门柱不是网,而且尺寸更大。现在的问题是,我们能否建立一个能够正确分类图像的系统。这就是我们项目背后的想法,我们想要建立一个系统能够识别图像中所代表的运动。这里分为橄榄球和足球两大类。问题陈述可能有点棘手,因为体育运动有很多共同的方面,尽管如此,我们将学习如何解决问题,并创建一个良好的表现系统。设置我们的图像数据由于我们正在处理一个图像分类问题,我使用了两个最大的图像数据源,即ImageNet和谷歌OpenImages。我实现了两个python脚本,我们可以轻松地下载图像。一共下载了3058张图片,分为train和test两部分。我用训练文件夹有2448张图片,测试文件夹有610张图片,进行了80-20的分割。橄榄球和足球两个类别各有1224张图片。我们的数据结构如下:输入 3058橄榄球 - 310足球 - 310橄榄球 - 1224足球 - 1224训练 - 2048测试 - 610我们来建立我们的图像分类模型!步骤1: 导入所需的库这里,我们将使用Keras库来创建模型并对其进行训练。我们还使用Matplotlib和Seaborn来可视化我们的数据集,以便更好地理解我们将要处理的图像。另一个处理图像数据的重要库是Opencv。import matplotlib.pyplot as plt
import seaborn as sns
import keras
from keras.models import Sequential
from keras.layers import Dense, Conv2D , MaxPool2D , Flatten , Dropout
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from sklearn.metrics import classification_report,confusion_matrix
import tensorflow as tf
import cv2
import os
import numpy as np
步骤2: 加载数据接下来,让我们定义数据的路径。让我们定义一个名为get_data()的函数,它使我们更容易创建我们的训练和验证数据集。我们定义了我们将要使用的两个标签“Rugby”和“Soccer”。我们使用Opencv imread函数读取RGB格式的图像,并将图像大小调整到我们想要的宽度和高度(在本例中都是224)。labels = ['rugby', 'soccer']
img_size = 224
def get_data(data_dir):
data = []
for label in labels:
path = os.path.join(data_dir, label)
class_num = labels.index(label)
for img in os.listdir(path):
try:
img_arr = cv2.imread(os.path.join(path, img))[...,::-1] #convert BGR to RGB format
resized_arr = cv2.resize(img_arr, (img_size, img_size)) # Reshaping images to preferred size
data.append([resized_arr, class_num])
except Exception as e:
print(e)
return np.array(data)
Now we can easily fetch our train and validation data.
train = get_data('../input/traintestsports/Main/train')
val = get_data('../input/traintestsports/Main/test')
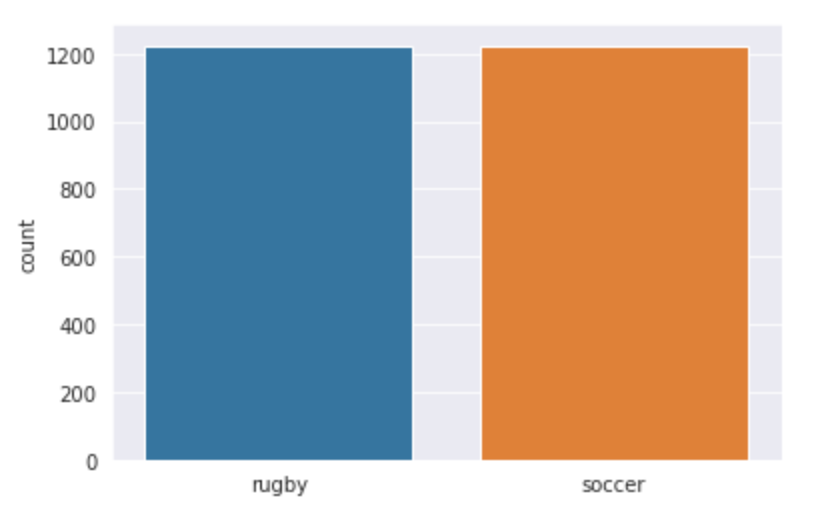
步骤3: 可视化数据让我们可视化我们的数据,看看我们到底在使用什么。我们使用seaborn来绘制这两个类中的图像数量,你可以看到输出是什么样的。l = []
for i in train:
if(i[1] == 0):
l.append("rugby")
else
l.append("soccer")
sns.set_style('darkgrid')
sns.countplot(l)
输出:
1 2 下一页>
