一文教你使用python+Keras检测年龄和性别
磐创AI目标
本文的主要目的是通过给定的数据集检测年龄和性别。我们将使用简单的 python 和 Keras 方法来检测年龄和性别。
介绍
将摄像头、卫星、飞机以及日常生活中所拍摄的图像进行升级,称为图像处理。
基于分析的图像处理经历了许多不同的技术和计算。
图片中可获取信息的位置是非常必要的信息。图像包含的信息将被更改和调整以用于发现目的。
在面部识别策略中:面部包含的关节包含大量数据。当一个人与另一个人产生联系时,就会产生大量的想法。
思想的演变有助于确定某些界限。年龄评估是一个多层次的问题。不同年龄的人有不同的面部特征,因此很难将这些图像组合起来。
要确定几个人脸的年龄和性别的程序,后面有几种方法。从神经网络中,特征由卷积网络获取。根据准备好的模型,将图像处理为其中一个年龄段。框架的准备工作将进一步进行。
数据集
UTK 数据集包含 .csv 格式的年龄、性别、图像和像素。根据图像的年龄和性别检测已经研究了很长时间。多年来,人们采用不同的方法来处理这个问题。现在我们开始使用 Python 编程语言识别年龄和性别。
Keras 是 TensorFlow 库的接口。如果你需要一个允许简单快速的原型制作(通过易用性、隐蔽性和可扩展性)的深度学习库,请使用 Keras。Keras支持卷积网络和重复组织,可以在 CPU 和 GPU 上完美运行。
代码
#Import libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df=pd.read_csv("age_gender.csv")
df1= pd.DataFrame(df)
plt.xlabel = 'Gender (1= Female, 0-Male)'
plt.figure(figsize=(10,7))
ax=df1.gender.value_counts().plot.bar(x='Gender (1= Female, 0-Male)', y='Count', title='Gender', legend = (1,0, ('Female', 'Male')))
plt.figure(figsize=(10,7))
labels =['White','Black','Indian','Asian','Hispanic']
ax=df1.ethnicity.value_counts().plot.bar()
ax.set_xticklabels(labels)
ax.set_title('Ethinicity')
## Converting pixels into numpy array
df1['pixels'] = df1['pixels'].apply(lambda x: np.reshape(np.array(x.split(), dtype="float32"), (48,48)))
df1.head()
def plot_data(rows, cols, lower_value, upper_value):
fig = plt.figure(figsize=(cols*3,rows*4))
for i in range(1, cols*rows + 1):
k = np.random.randint(lower_value,upper_value)
fig.add_subplot(rows, cols, i) # adding sub plot
gender = gender_values_to_labels[df.gender[k]]
ethnicity = eth_values_to_labels[df.ethnicity[k]]
age = df.age[k]
im = df.pixels[k]
plt.imshow(im, cmap='gray')
plt.axis('off')
plt.title(f'Gender:{gender}nAge:{age}nEthnicity:{ethnicity}')
plt.tight_layout()
plt.show()

图 1 通过简单的 Python 进行年龄和性别检测
Keras
Keras 是一个开源的神经网络库。它是用 Python 编写的,非常适合在由 Google 工程师 Francois Chollet 开发的 Theano、TensorFlow 或 CNTK 上运行。它易于理解、可扩展,特别适合于对复杂的神经组织进行更快的实验。
首先,我们将上传数据集所需的所有库。我们将使用 np.array 将所有列转换为数组,并转换为 dtype float。然后我们将数据集拆分为 xTrain、yTrain、yTest 和 xtest。最后,我们将依次应用模型并测试预测。
具体来说,首先,我们使用pandas、read_csv函数读取包含年龄、种族、性别、图像名称和像素五列的CSV文件。前五行是通过使用 DataFrame.head() 方法获得的。我们使用 NumPy 库将列名像素转换为数组,并使用 lambda 函数将它们重塑为 48、48 维。我们还通过相同的 lambda 函数转换了浮点数中的值。
我们将这些值进一步除以 255。
我们分配变量名以获取像素列的第一行。我们通过使用 matplotlib 进一步检查图像是否被看到。
导入库
import keras
import json
import sys
import tensorflow as tf
from keras.layers import Input
import numpy as np
import argparse
from keras_applications.resnext import ResNeXt50
from keras.utils.data_utils import get_file
import face_recognition
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import cv2
from PIL import Image
df=pd.read_csv("age_gender.csv")df.head()df1= pd.DataFrame(df)
df1['pixels'] = df1.pixels.apply(lambda x: np.reshape(np.array(x.split(' '),dtype='float32'),(48,48)))
df1['pixels']= df1['pixels']/255
im = df1['pixels'][0]
im
plt.imshow(im, cmap='gray')
plt.axis('off')

图2 重塑后的图像
要将所有值转换为浮点数并对其进行重塑,我们使用了函数 for 和 NumPy。为了将年龄和性别存储在列表中,我们将使用另一个变量 labels_f。
稍后的模型将用于拟合数据并对其进行验证。
#收集所有图像并重塑它们,检查dtype。
X = np.zeros(shape=(23705,48,48))
for i in range(len(df1["pixels"])):
X[i] = df1["pixels"][i]
X.dtype
Output - dtype('float64')
#Age
ag = df1['age']
ag=ag.astype(float)
ag= np.array(ag)
ag.shape
输出 - (23705,)
#性别
g= df1['gender']
g=np.array(g)
g.shape
(23705,)
labels_f =[]
i=0
while i
label.append([a[i]])
label.append([g[i]])
labels_f.append(label)
i+=1
Both age and gender are combined and stored in labels_f, we will further convert the list into array.
labels_f =np.array(labels_f)
labels_f.shape
(23705, 2, 1)
使用最常用的机器学习库 sklearn,将数据拆分为训练和测试。
#Splitting the data taking data set
import tensorflow as tf
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test= train_test_split(X,a,test_size=0.25)
print(X_test.shape)
print(X_train.shape)
print(Y_test.shape)
print(Y_train.shape)
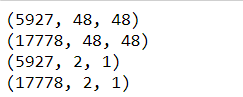
图 3 X_train、X_test、Y_train 和 Y_test 的形状输出
Y_train_2=[Y_train[:,1],Y_train[:,0]]
Y_test_2=[Y_test[:,1],Y_test[:,0]]
#模型
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten,BatchNormalization
from tensorflow.keras.layers import Dense, MaxPooling2D,Conv2D
from tensorflow.keras.layers import Input,Activation,Add
from tensorflow.keras.models import Model
from tensorflow.keras.regularizers import l2
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
def Convolution(input_tensor,filters):
x = Conv2D(filters=filters,kernel_size=(3, 3),padding = 'same',strides=(1, 1),kernel_regularizer=l2(0.001))(input_tensor)
x = Dropout(0.1)(x)
x= Activation('relu')(x)
return x
def model(input_shape):
inputs = Input((input_shape))
conv_1= Convolution(inputs,32)
maxp_1 = MaxPooling2D(pool_size = (2,2)) (conv_1)
conv_2 = Convolution(maxp_1,64)
maxp_2 = MaxPooling2D(pool_size = (2, 2)) (conv_2)
conv_3 = Convolution(maxp_2,128)
maxp_3 = MaxPooling2D(pool_size = (2, 2)) (conv_3)
conv_4 = Convolution(maxp_3,256)
maxp_4 = MaxPooling2D(pool_size = (2, 2)) (conv_4)
flatten= Flatten() (maxp_4)
dense_1= Dense(64,activation='relu')(flatten)
dense_2= Dense(64,activation='relu')(flatten)
drop_1=Dropout(0.2)(dense_1)
drop_2=Dropout(0.2)(dense_2)
output_1= Dense(1,activation="sigmoid",name='sex_out')(drop_1)
output_2= Dense(1,activation="relu",name='age_out')(drop_2)
model = Model(inputs=[inputs], outputs=[output_1,output_2])
model.compile(loss=["binary_crossentropy","mae"], optimizer="Adam",
metrics=["accuracy"])
return model
Model=model((48,48,1))
Model.summary()
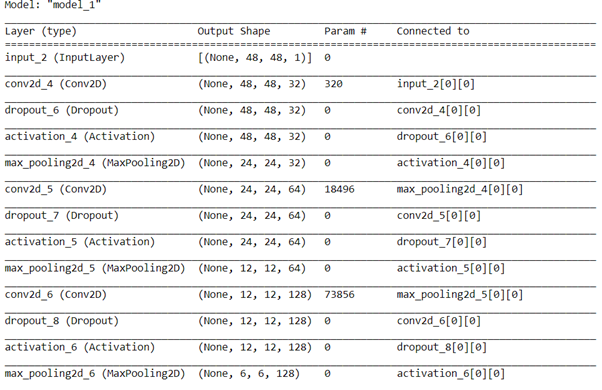
图 4 详细模型汇总
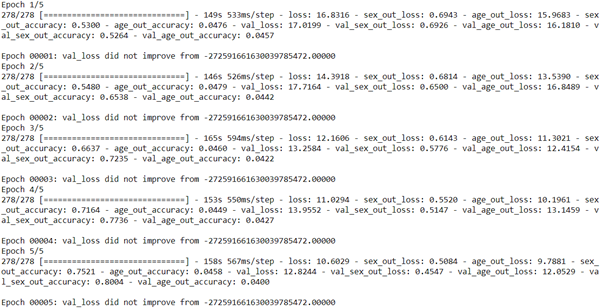
History=Model.fit(X_train,Y_train_2,batch_size=64,validation_data=(X_test,Y_test_2),epochs=5,callbacks=[callback_list])
Model.evaluate(X_test,Y_test_2)

pred=Model.predict(X_test)
pred[1]
#绘制图像
def test_image(ind,X,Model):
plt.imshow(X[ind])
image_test=X[ind]
pred_1=Model.predict(np.array([image_test]))
sex_f=['Female','Male']
age=int(np.round(pred_1[1][0]))
sex=int(np.round(pred_1[0][0]))
print("Predicted Age: "+ str(age))
print("Predicted Sex: "+ sex_f[sex])
test_image(1980,X, Model)
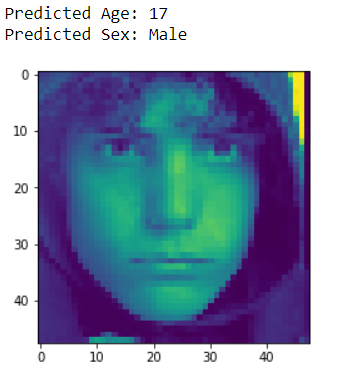
图 5 模型的年龄和性别检测。
结论
识别年龄和性别的任务是一个麻烦问题,比许多其他视觉任务更是如此。
这个问题漏洞的根本在于准备这些类型的框架所需的信息。虽然一般的文章发现通常可以处理数千甚至大量的图片以供准备,但具有年龄和性别名称的数据集要广泛得多,通常在大量或最好的情况下,数千Python获取的图像,模型在准确率上做得并不好,模型算法有待改进。
