为什么不能是「她」?AI也要反性别偏见
将门创投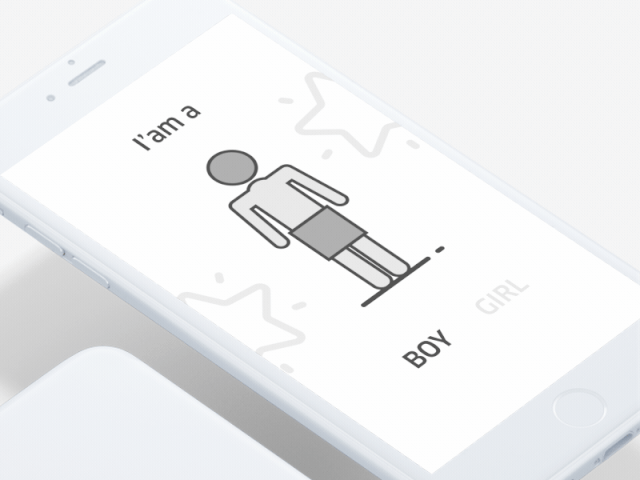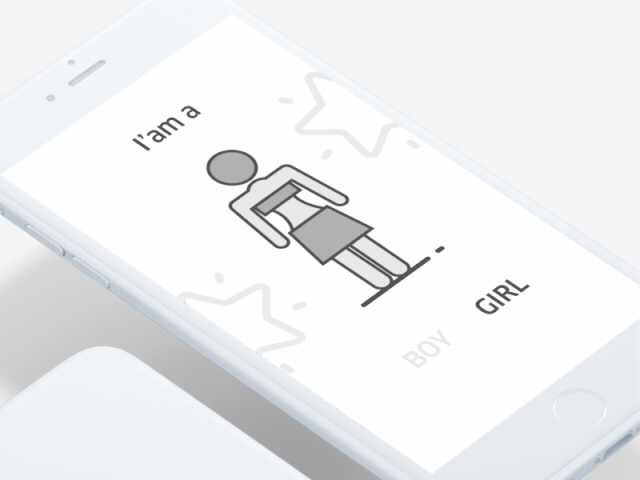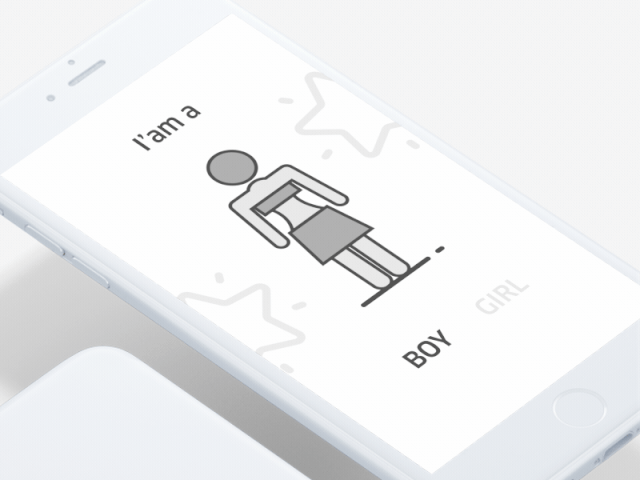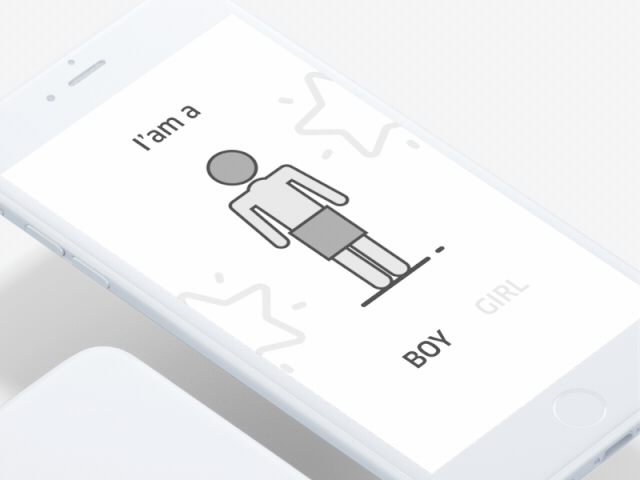
提到性别偏见,别以为只有人才会产生偏见,事实上作为非生命体的AI系统,也可能因为设计者的疏忽,或者社会语料库本身的性别不公因素,而流露出性别偏见倾向。这当然不是设计者的本意,可是这种现象无可避免地会对部分用户造成观感不适。
特伦托大学的研究人员以身力行,借用名为"MuST-SHE"的测试集,来评估AI语音翻译系统的输入文本数据集是否存在具有性别差异的语句,而AI又是否将这种性别差异从翻译加工成果中体现出来。
分门别类!为不同翻译语料类型找准定位
在机器翻译过程中,性别偏见可以归因于语言表达上之于男女性别的差异。那些有专属性别语法系统的语言,如罗曼斯语,依赖于性别词性和句法变化来区分出性别差异。而这对于英语和中文都是不适用的,比如说,中文是一种“自然性别”系的语言,它只通过代词(如:“她”和“他”)、固有性别的词语(如:“男孩”和“女孩”)和性别专用名词(如:“妈妈”和“夫人”)来反映性别差异。
如果AI翻译系统不能捕捉到这些细微差别,可能导致对不同性别群体的不准确描述。为了尽可能抹消这种区别,研究人员专门创建了一个被称为MuST-SHE的多语言测试集,旨在揭露潜藏在语言翻译系统后的性别偏见。

机器人在吸收歧视性数据集后,也会表现出歧视倾向
MuST-SHE是基于TED演讲数据集筛选得出的一个数据子集,其中包括大约1000份音频、文本和翻译素材,这些翻译素材都取自开源MuST-C语料库,有专门的语料注释了与性别相关的定性差异。这些素材被细分为两类:
第1类:当性别差异性仅取决于说话人本身的性别时(即没有相应的语境样本支持),翻译素材的形成需从音频信号中获取消除性别歧义的必要信息样本。
第2类:所得的翻译素材有直接消除歧义信息的样本支持,其中包含比较清晰的语境提示,如性别指定性词组、代词和专有名词都能说明说话者的性别。

每一类的第一框都是正确语料例子
第二框是错误例子作为参照物
基于语料库中的每一条翻译引用,研究人员都特意创建了一个反面语料例子,除了“他/她”不分、“男/女”不分之外,反面的翻译素材与原文的涵义其实完全相同。在将两种语料信息输入AI翻译系统后,研究结果表明,在性别的正式表达预料方面,原语料库中的翻译范例被AI驳回,认为其是“存在部分错误的”,而反面语料例子则被认为是“正确的”。这种结果差异可以用来衡量语音识别系统处理性别现象的能力。
1 2 下一页>
