基于OneData的数据仓库建设过程
园陌本文目录:
一、指导思想
二、数据调研
三、架构设计
四、指标体系搭建
五、模型设计
六、维度设计
七、事实表设计
八、其他规范
OneData是阿里巴巴内部进行数据整合和管理方法体系和工具。
一、指导思想
首先,要进行充分的业务调研和需求分析。
其次,进行数据总体架构设计,主要是根据数据域对数据进行划分;按照维度建模理论,构建总线矩阵,抽象出业务过程和维度。
再次,对报表需求进行抽象整理出相关指标体系,使用OneData工具完成指标规范定义和模型设计。最后,是代码研发和运维。
其实施流程主要分为:数据调研、架构设计、规范定义和模型设计。
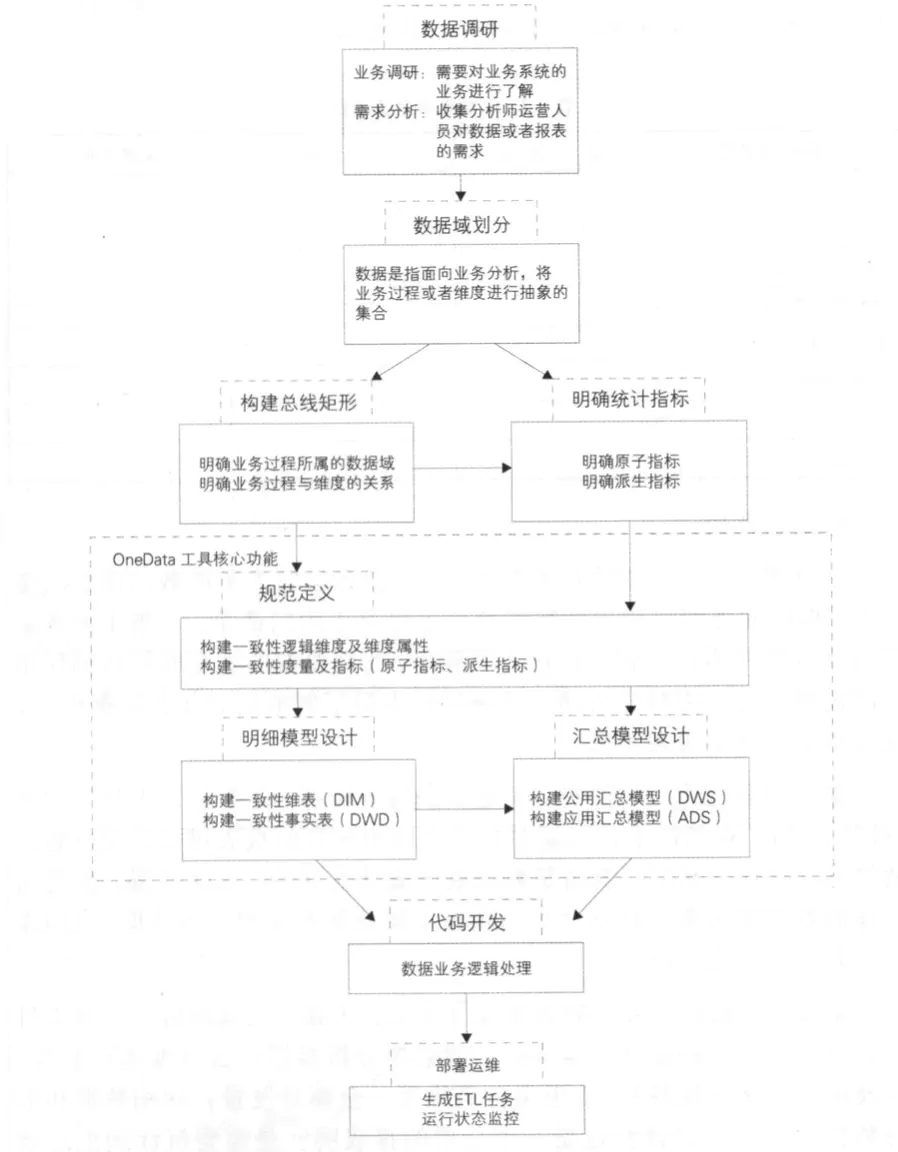
二、数据调研
1. 业务调研
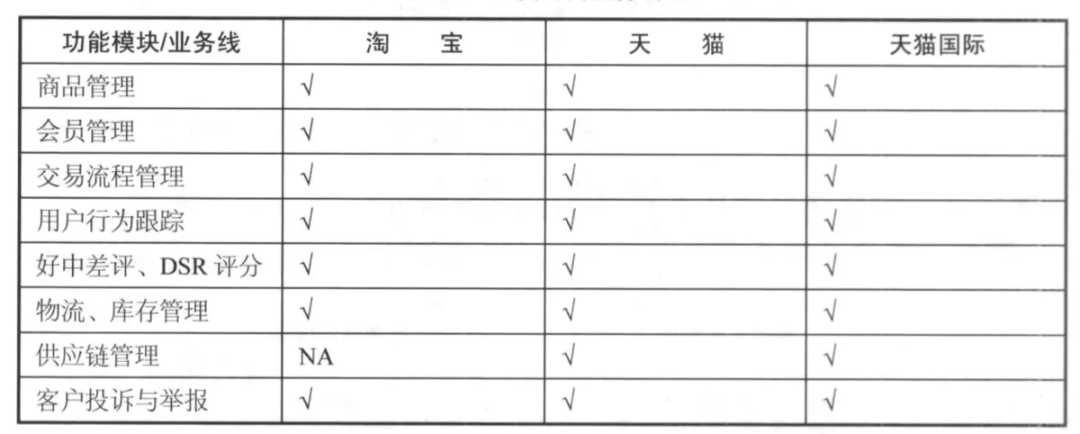
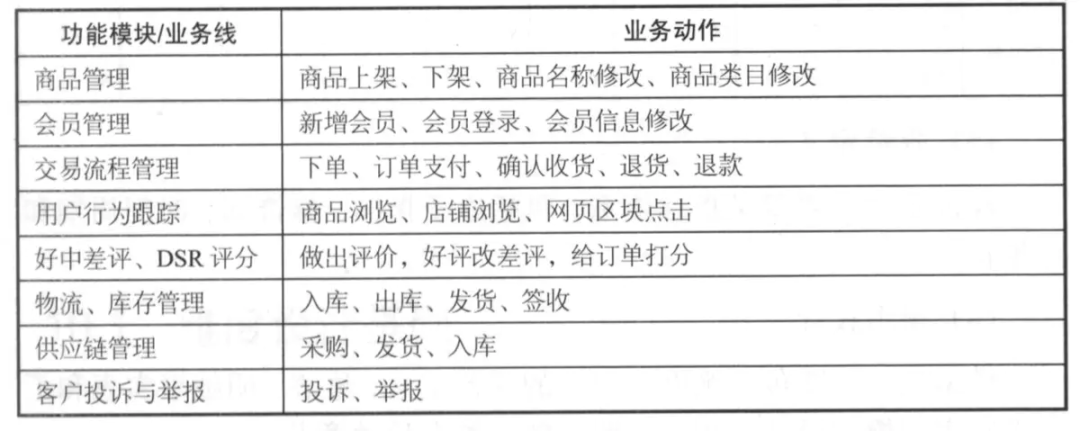
需要确认要规划进数仓的业务领域,以及各业务领域包含的功能模块,以阿里的业务为例,可规划如下矩阵:
2. 需求调研
了解需求方关系哪些指标?需要哪些维度、度量?数据是否沉淀到汇总层等到。

三、架构设计
1. 数据域的划分
数据域是将业务过程或者维度进行抽象的集合,一般数据域和应用系统(功能模块)有联系,可以考虑将同一个功能模块系统的业务过程划分到一个数据域:
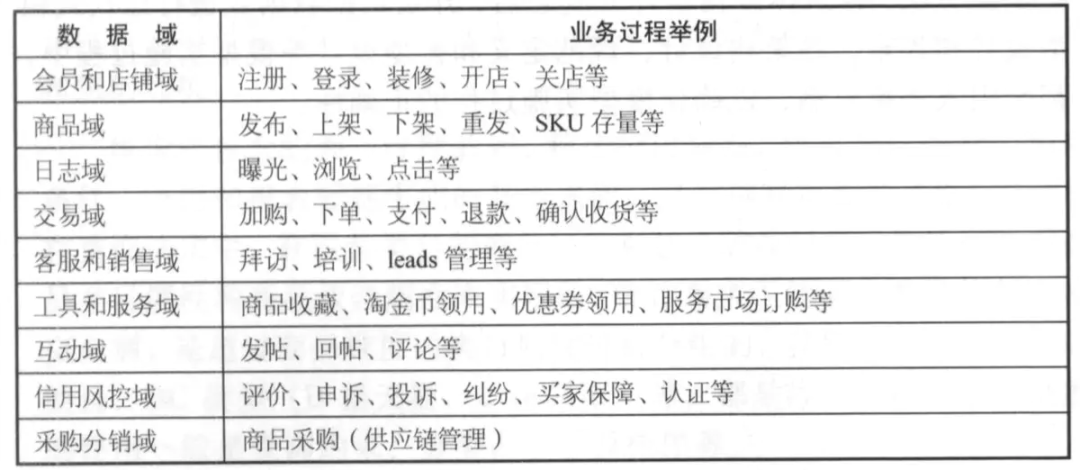
2. 构建总线矩阵
在进行充分的业务调研和需求调研后,就要构建总线矩阵了,需要做两件事情:
明确每个数据域下有哪些业务过程。业务过程与哪些维度相关,并通过总线矩阵定义每个数据域下的业务过程和维度:

四、指标体系搭建
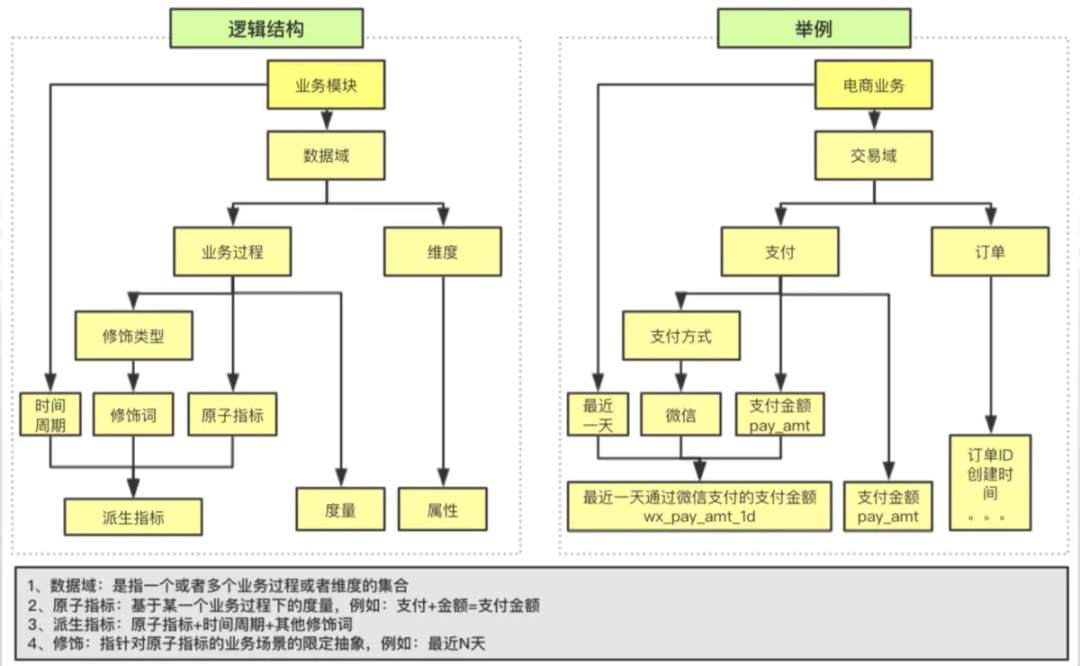
1. 基本概念
数据域:指面向业务分析,将业务过程或者维度进行抽象的集合。
业务过程:指企业的业务活动中的事件。
时间周期:用来明确数据统计的事件范围或者时间点,如近30天、截至当前。
修饰类型:对修饰词的一种抽象划分。
修饰词:指除统计维度外指标的业务场景限定抽象。抽象词隶属于一种抽象类型,如访问终端类型下的pc、安卓、苹果。
度量/原子指标:具有明确含义的业务名词。如:支付金额。
维度:维度是度量的环境,用来反应业务的一类属性,这类属性的集合称为一个维度,也可以称为实体对象,如地理维度、时间维度。
维度属性:对维度的描述,隶属于一个维度。如:地理维度下的国家、省份。
派生指标:原子指标+多个修饰词(可选)+时间周期。
明确原子指标、修饰词、时间周期和派生指标的定义。
2. 操作细则
派生指标来源于三类指标:事务型指标、存量型指标和复合型指标。
事务型指标:指对业务活动进行衡量的指标。
存量型指标:指对实体对象某些状态的统计。
复合型指标,在上述两种指标基础上复合而成的。

五、模型设计
1. 数据分层
业界对数仓分层的看法大同小异,大体上认为分为接入层、中间层和应用层三层,不过对中间层的理解有些差异。

2. 接入层(ods)
业务数据一般是采用dataX或者sqoop等以固定频率同步到数仓中构建ODS层;
如果是日志数据则通过flume或者Kafka等同步到数仓中。
接入层一般不会对源数据做任何处理、清洗,便于之后回溯。
3. 明细层(dwd)
理论上明细层数据是对ods层数据进行清洗加工,提高ods层数据的可用性,对于dwd层数据是否同层引用的观点需要权衡:
一般情况下dwd层不建议同层引用,这样做可以减少明细层任务之间的依赖,减少节点深度。但是在某些场景下,ods层到dwd层数据加工逻辑复杂,计算开销大,这时可以权衡考虑适当复用dwd表来构建新的dwd表。4. 汇总层(dws)
这一层依赖我们的指标体系,将dwd层的数据按照各个维度进行聚合计算。
5. 数据集市层(dwm)
当我们有一些跨业务域的聚合统计需求时,放到这一层。
6. 应用层(app)
这一层主要针对汇总层,进行相关指标的组合,生成报表。
六、维度设计
维度建模中,将度量称为事实,维度用于分析事实所需要的多样环境。维度的作用一般是查询、分类汇总以及排序。
通过报表的约束条件,以及之前数据调研和业务方的沟通,我们可以获得维度。
维度通过主键与事实表进行关联,维度表的主键分为代理键和自然键两种;代理键不具有业务含义,一般用于处理缓慢变化维度,自然键则具有业务含义。
1. 维度设计基本方法选择或者新建一个维度,通过之前总线矩阵的构建掌握了目前数仓架构中的维度。确定主维表。此处主维表一般是ODS表,直接与业务系统同步。确定相关维表。数仓是业务源系统的数据整合,不同业务系统或者同一业务系统中的表之间存在关联性。跟据对业务的梳理,我们可以确认哪些表和主维表存在关联关系,并选择其中的某些表用于生成维度属性。确定维度属性。本步骤分为两阶段,第一阶段是从主维表中选择维度属性或生成新的维度属性;第二阶段是从相关维表中选择维度属性或生成新的维度属性。2. 规范化和反规范化
当具有多层次的维度属性,按照第三范式进行规范化后形成一系列维度表,而非单一维度表,这种建模称为雪花模式。
将维度的属性层次合并到单个维度中的操作称为反规范化。
3. 一致性维度和交叉探查
我们存在很多需求是对于不同数据域的业务过程或同一数据域的不同业务过程合并在一起观察。例如:对于日志数据域统计商品维度的近一天PV和UV;对于交易数据域统计商品维度近一天的GMV。
这种将不同数据域的商品事实合并在一起进行数据探查,称为交叉探查。
数仓能进行交叉探查的前提是,不同数据域要具有一致性维度。
4. 维度整合
由于数仓的数据源来源于不同的应用系统,应用系统之间相互独立,因此对同一信息的描述、存储都可能具有差异。
而这些具有差异的数据进入数仓后需要整合在一起:
命名规范的统一。表名、字段名等统一。字段类型的统一。相同和相似字段的字段类型统一。公共代码以及代码值的统一。业务含义相同的表的统一。主要依据高内聚、低耦合的理念,将业务关系大,源系统影响差异小的表进行整合。
表级别的整合主要有两种形式:
垂直整合,即不同来源表包含相同的数据集,只是存储的信息不同,可以整合到同一个维度模型中。
水平整合,即不同来源表包含不同的数据集,这些子集之间无交叉或存在部分交叉,如果有交叉则去重;如果无交叉,考虑不同子集的自然键是否冲突,不冲突则可以将各子集自然键作为整合后的自然键,或者将各自然键加工成一个超自然键。
5. 拉链表
拉链表,又称为极限存储技术。假设某一张表是用来存储全量用户信息的,一般我们的处理方式是,用每个分区去存储每天全量数据的快照,这种方式的问题是,如果我希望保存用户的所有历史状态,我可能需要永久保存每一个历史分区。
如果使用拉链表,每个分区可以保存每个用户在当天的历史状态,同时历史分区也可以进行清理。
这样,虽然单个分区中存储的数据变多了,但是某些历史分区的数据被清理后,整个表存储的数据会变少了,因为很多没有变化的用户信息快照被清理了。
6. 微型维度
微型维度的创建是通过将一部分不稳定的属性从相对稳定的主维度中移除,放置到拥有自己代理键的新表来实现。
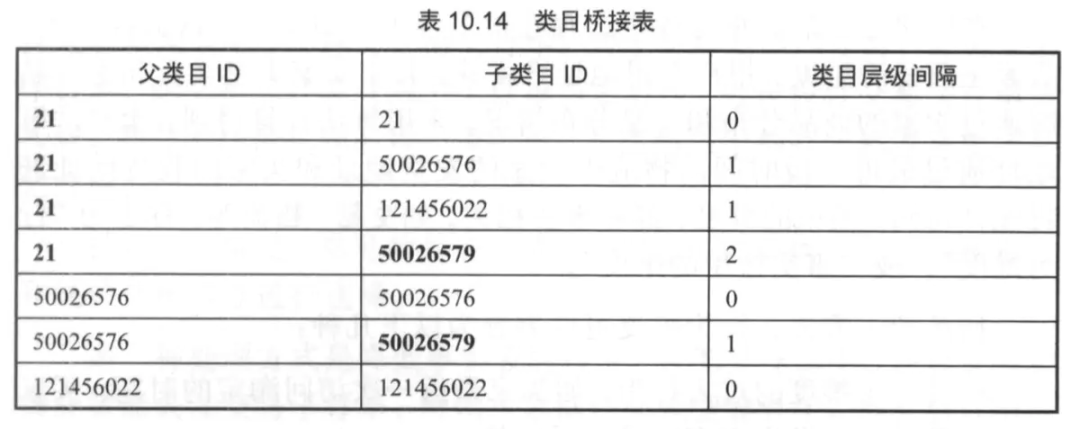
7. 递归层次
递归层次指的是某维表的实例值的层次关系,维度的递归层次分为有固定数量级别的均衡层次结构和无固定数量级别的非均衡层次结构。
由于数仓中一般不支持递归SQL的功能来处理这种层次结构,所以需要用到其他方式。
层次结构扁平化,适合均衡层次结构维度。层次桥接表,适合非均衡层次结构维度。
8. 多值维度
多值维度指事实表的一条记录在某维度表中有多条记录与之对应。
针对多值维度,常见的处理方式有三种:
降低事实表的粒度。列扩展。较为通用的方式,采用桥接表。9. 杂项维度
杂项维度是由操作型系统中的指示符或者标志字段组合而成,一般不在一致性维度之列。
这些维度如果作为事实存在事实表中,则会导致事实表占用空间变大;如果单独建立维表,则会出现许多零碎的小维表。
这时,通常的解决方案是建立杂项维度,将这些字段建立到一个维表中,在事实表中只需保存一个外键即可,杂项维度可以理解为将许多小维表通过行转列的方式存储到一张大维表中的处理方案。
10. 退化维度
指维度属性直接存储到事实表中的维度。
七、事实表设计
事实表中一条记录所表达的业务细节程度称为粒度。
1. 事实类型
作为度量业务过程的事实,有可加性、半可加性和不可加性三种类型:
可加性事实指可以按照与事实表关联的任意维度进行汇总。
半可加事实只能按照特定维度汇总,不能对所有维度汇总。
不可加性事实完全不具备可加性,比如比例事实。对于不可加性事实可考虑分解为可加的组件来实现聚合。
2. 事实表类型
最常见的事实表有三种类型:事务事实表、周期快照事实表和累积快照事实表。
事务事实表用来描述业务过程,表示对应时空上某点的度量事件,保存的是最原子的数据,也称为原子事实表。在实际使用中,一般作为明细层使用,例如下单明细、支付明细等。
周期快照事实表的一行,以具有规律性的时间间隔记录事实。如每日库存快照表、每日用户余额快照表。
累积快照事实表用来表述过程开始和结束之间的关键步骤事件,覆盖过程的整个生命周期,通常具有多个日期字段来记录关键时间点,当过程随着生命周期不断变化时,记录也会随着过程的变化而被修改。以事务事实表中提到的订单例子为例,可以做一个和订单相关的,涉及订单下单、推单、抢单、支付等各个环节的一张订单全生命周期快照表。
此外,还有一种无事实的事实表,单纯只记录某一动作发生,其事件的量化是非数字的,比较典型的例子是访问点击日志。
3. 事实表设计原则尽可能包含所有与业务过程相关的事实。只选择与业务过程相关的事实。分解不可加性事实为可加的组件。在选择维度和事实之前必须先声明粒度。在同一个事实表中不能有多种不同粒度的事实。事实的单位要保持一致。对事实的null值要处理,建议用0填充。使用退化维度提高事实表的易用性。4. 事实表设计方法选择业务过程及确认事实表类型。声明粒度。确定维度。确定事实。冗余维度。5. 事实表
单事务事实表,针对每个业务过程设计一个事实表。这样方便对每个业务过程进行独立的分析研究。
多事务事实表,将不同的事实放到同一个事实表中,即同一个事实表包含不同的业务过程。
多事务事实表有两种方法进行事实处理:
不同业务过程的事实使用不同的事实字段进行存放;如果不是不是当前业务过程的度量,可以考虑用0值填充。不同业务过程的事实使用同一个事实字段进行存放,但增加一列作为业务过程标签,记录该事务是否在当天完成。
关于多事务事实表具体采用哪种方式进行事实处理:
在实际应用中,当业务过程度量比较相似、差异不打时,可以采取第二种多事务事实表的设计方式,使用同一个字段来表示度量数据。但这种方式存在一个问题,在同一个周期内会存在多条记录。
当不同业务过程的度量差异较大时,可以选择第一种多事务事实表的设计方式,将不同业务过程的度量使用不同字段冗余到表中,非当前业务过程则置为0,这种方式存在的问题是度量字段0值会比较多。
具体使用单事务事实表还是多事务事实表,需要从以下几点分析:
业务过程
多个业务过程是否放到同一个事实表中,首先需要分析不同业务过程之间的相似性和业务源系统。
比如淘宝交易的下单、支付和成功完结三个业务过程存在相似性,并且都来自于一个应用系统-交易系统,适合放到同一个事务事实表。
粒度和维度
在考虑是采用单事务表还是多事务表时,一个关键点是粒度和维度。
在确定好业务过程后,需要基于不同的业务过程确定粒度和维度,当不同业务过程的粒度相同,同时拥有相似维度时,可以考虑采用多事务事实表。如果粒度不同,必定是存存储在不同事务表中的。
事实
如果单一业务过程的事实较多,同时不同业务过程的事实又不相同,则考虑使用单事务事实表,处理更加清晰;
若使用多事务事实表,则会导致事实表零值或空值字段较多。
下游业务使用
单事务事实表对于下游用户而言更容易理解,关注哪个业务过程就使用相应的事务事实表;而多事务事实表包含多个业务过程,用户使用时往往较为困惑。
6. 周期快照事实表
事务事实表可以很好的跟踪一个事件,并进行度量分析。
然后,当需要一些状态度量时,比如账户余额、商品库存、卖家累积交易额等,则需要聚集与之相关的事务才能进行识别计算,也就是周期快照事实表。
周期快照事实表在确定的间隔内对实体的度量进行抽样,以研究实体的度量值,而不需要聚集长期的事务历史。
7. 累积快照事实表
对于类似于研究事件之间时间间隔的需求,事务事实表处理逻辑复杂且性能差,采用累积快照事实表可以很好解决。
快照事实表中收集到到状态度量都是半可加到,不能根据时间维度获得有意义到汇总结果。
数仓在进行维度建模时,对于事务事实表和快照事实表往往都是成对设计,互相补充,以满足更多下游统计分析需求,特别是在事务事实表基础上可以加工快照事实表。
八、其他规范
1. 层次调研约定应用层优先调用公共层数据。已经存在的中间层数据,不允许应用层跨中间层从ODS层重复加工数据。中间层团队应该积极了解应用层数据的建设需求,将公用的数据沉淀到公共层,为其他团队提供数据服务。应用层团队也需要积极配合中间层团队进行数据公共层建设的改造和迁移。必须避免过度使用ODS层引用和不合理的数据复制和子集合冗余。2. 命名规范
表命名规范:<层次><业务域名称><数据域名称><业务过程名称|自定义表名><刷新周期+存储策略>
字段命名规范:

3. 开发规范总原则原则上不能依赖非数据团队节点。未获得节点owner许可的情况下,不能擅自修改别人的节点。不能随意变更节点owner,必须知会接收人并得到同意。
