深兰科技多条推理任务解决方案分享
AI世界2021年6月6日-11日,自然语言处理(NLP)领域的顶级会议NAACL在线上举办。深兰科技DeepBlueAI团队参加了Multi-Hop Inference Explanation Regeneration (TextGraphs-15) 共享任务比赛,并获得了第一,该方案多用于科学知识问答等领域。同赛道竞技的还有腾讯、哈尔滨工业大学组成的团队以及新加坡科技设计大学团队等。
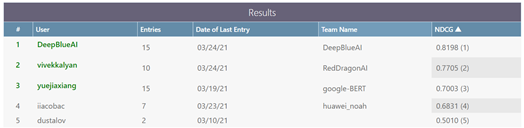
图1 成绩排名
NAACL全称为 Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,与ACL、EMNLP并称NLP领域的三大顶会。
冠军方案分享
任务介绍
多条推理(Multi-Hop Inference)任务是结合多条信息去解决推理任务,如可以从书中或者网络上选择有用的句子,或者集合一些知识库的知识去回答他人提出的问题。如下图所示,如需回答当前问题,要结合图中所示三种信息才能完成推理,得到正确的答案。而解释再生(Explanation Regeneration)任务是多条推理任务的基础,其目的是构建科学问题的解释,每个解释都表示为一个“解释图”,一组原子事实(每个解释包含1-16个,从9000个事实的知识库中提取),它们一起构成了对回答和解释问题进行推理解析的详细解释。
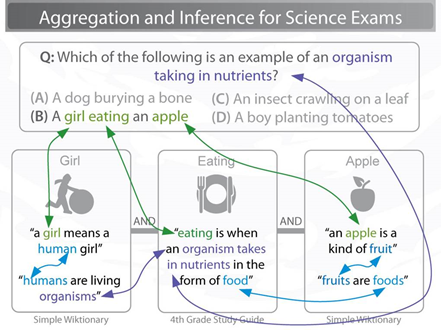
图2 任务示例
对于当前任务,举办方将其定义为一个排序任务,输入的是问题及其对应的正确答案,要求系统能够对提供的半结构化知识库中的原子事实解释进行排序,以便排名靠前的原子事实解释能够为答案提供更加详细和确切的说明。

数 据
此共享任务中使用的数据包含从 AI2 推理挑战 (ARC) 数据集中提取的大约 5,100 道科学考试题,以及从 WorldTree V2.1[2] 解释中提取的正确答案的事实解释语料库,并在此基础上增加了专家生成的相关性评级。支持这些问题及其解释的知识库包含大约 9,000 个事实,知识库既可以作为纯文本句子(非结构化)也可以作为半结构化表格使用。

方 案
该任务为一个排序任务,具体表现为给定问题和答案,将知识库中的9,000个原子事实解释进行排序,评价方式为NDCG。方案主要由召回和排序两部分组成,第一步先召回Top-K(k> 100)个解释,第二步对召回的Top-K个解释进行排序。针对召回和排序任务,如果直接采用 Interaction-Based(交互型,即问题文本和事实解释在模型中存在信息交互) 类型的网络,计算量将巨大,因此交互型网络在当前的任务中无法使用,团队最终采用了向量化检索的方式进行排序。
为了提取更深的语义信息生成比较好的特征向量,团队没有采用TF-IDF、BM25、DSSM[3]等常用的排序模型,而是采用了当前比较流行的预训练模型作为特征提取器,结合Triplet loss[4]训练了一个Triplet Network来完成向量化排序,其中在召回部分和排序部分均采用Triplet Network。
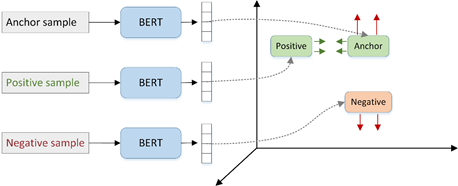
图3 Triplet loss
Triplet loss如图3所示,输入样本对是一个三元组,这个三元组
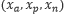
由一个锚点样本
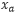
,一个正样本
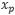
,一个负样本组成
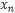
。其目标是锚点样本与负样本之间的距离
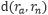
与锚点样本和正样本之间的距离
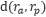
之差大于一个阈值m ,可以表示为:
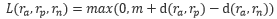
。
对于简单容易学习的样本
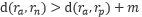
,对比于正样本来说,负样本和锚点样本已经有足够的距离了(即是大于m ),此时loss为0,网络参数将不会继续更新,对于其他样本loss>0 网络参数可以正常更新。

模 型
针对当前任务,如下图所示,锚点(Anchor)样本为问题和答案连接的文本,正样本(Positive)为问题对应的解释文本,负样本(Negative)为其他随机选择与正样本不同的解释文本,其中他们三个输入共享一套预训练语言模型(Pre-trained language model :PLM)参数。训练时将上述三个文本输入到PLM模型中,选取PLM模型的所有Token 向量平均作为输出,将三个输入向量经过Triplet Loss 得到损失值完成模型的训练。
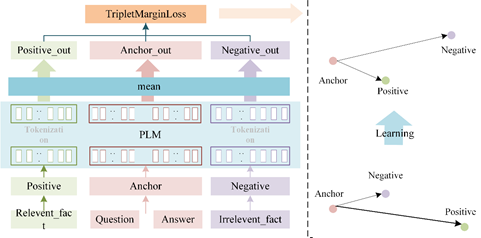
图4 模型图

负 采 样
为了更好地训练模型,团队在召回阶段采用了三种不同的负采样方式:
全局随机负采样,即在9,000个解释文本中随机选取一个不是正样本的样本作为负样本;
Batch内负采样,即在当前Batch内选取其他问题的对应的解释正样本,作为当前问题的负样本;
相近样本负采样,在同一个表中随机选取一个样本作为负样本,因为同一个表中的样本比较相近。
在排序阶段同样采取了三种不同的负采样方式:
Top-K 随机负采样,即在在召回的Top-K个样本中随机选取一个负样本;
Batch内负采样,和召回阶段相同;
Top-N 随机负采样,为了强化前面一些样本的排序效果,增大了前面N个样本的采样概率(N远远小于K)。
实 验
团队采用了两种预训练模型RoBERTa[5] 和ERNIE 2.0[6],并将两个模型的预测结果进行了融合。在召回和排序阶段,采用了同样的参数,主要参数如采用三种负采样方式,每种负采样方式选取16个样本,最终的batch size为48,epoch为15。同时,使用了Adam优化器并采用了学习率衰减策略,从1e-5衰减到0。
团队分别评测了NDCG @100、NDCG @500、NDCG @1000、NDCG @2000的结果,最终效果如下表所示,其中Baseline为TFIDF模型、Recall为召回阶段、Re-ranker为针对召回的结果重新排序的结果。从表中可以看出基于预训练模型的方法对比Baseline有着很大的提升,同时重排也有着显著的提升,同时从排行榜中可以看出DeepBlueAI团队的模型对比他人也有着较大的领先。
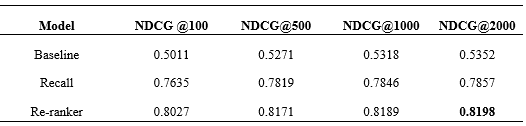
Table 1 The final results compared with different models
参考文献
[1] Clark P, Cowhey I, Etzioni O, et al. Think you have solved question answering? try arc, the ai2 reasoning challenge[J]. arXiv preprint arXiv:1803.05457, 2018.
[2] Xie Z, Thiem S, Martin J, et al. Worldtree v2: A corpus of science-domain structured explanations and inference patterns supporting multi-hop inference[C]//Proceedings of The 12th Language Resources and Evaluation Conference. 2020: 5456-5473.
[3] Huang, Po-Sen, et al. "Learning deep structured semantic models for web search using clickthrough data." *Proceedings of the 22nd ACM international conference on Information & Knowledge Management*. 2013.
[4] Schroff, Florian, Dmitry Kalenichenko, and James Philbin. "Facenet: A unified embedding for face recognition and clustering." *Proceedings of the IEEE conference on computer vision and pattern recognition*. 2015.
[5] Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bert pretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019.
[6] Sun Y, Wang S, Li Y, et al. Ernie 2.0: A continual pre-training framework for language understanding[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(05): 8968-8975.
