一文了解Hive SQL语句的正确执行顺序
园陌关于 sql 语句的执行顺序网上有很多资料,但是大多都没进行验证,并且很多都有点小错误,尤其是对于 select 和 group by 执行的先后顺序,有说 select 先执行,有说 group by 先执行,到底它俩谁先执行呢?
今天我们通过 explain 来验证下 sql 的执行顺序。
在验证之前,先说结论,Hive 中 sql 语句的执行顺序如下:
from .. where .. join .. on .. select .. group by .. select .. having .. distinct .. order by .. limit .. union/union all
可以看到 group by 是在两个 select 之间,我们知道 Hive 是默认开启 map 端的 group by 分组的,所以在 map 端是 select 先执行,在 reduce 端是 group by先执行。
下面我们通过一个 sql 语句分析下:
select
sum(b.order_amount) sum_amount,
count(a.userkey) count_user
from user_info a
left join user_order b
on a.idno=b.idno
where a.idno > '112233'
group by a.idno
having count_user>1
limit 10;
上面这条 sql 语句是可以成功执行的,我们看下它在 MR 中的执行顺序:
Map 阶段:
执行 from,进行表的查找与加载;
执行 where,注意:sql 语句中 left join 写在 where 之前的,但是实际执行先执行 where 操作,因为 Hive 会对语句进行优化,如果符合谓词下推规则,将进行谓词下推;
执行 left join 操作,按照 key 进行表的关联;
执行输出列的操作,注意: select 后面只有两个字段(order_amount,userkey),此时 Hive 是否只输出这两个字段呢,当然不是,因为 group by 的是 idno,如果只输出 select 的两个字段,后面 group by 将没有办法对 idno 进行分组,所以此时输出的字段有三个:idno,order_amount,userkey;
执行 map 端的 group by,此时的分组方式采用的是哈希分组,按照 idno 分组,进行order_amount 的 sum 操作和 userkey 的 count 操作,最后按照 idno 进行排序(group by 默认会附带排序操作);
Reduce 阶段:
执行 reduce 端的 group by,此时的分组方式采用的是合并分组,对 map 端发来的数据按照 idno 进行分组合并,同时进行聚合操作 sum(order_amount)和 count(userkey);
执行 select,此时输出的就只有 select 的两个字段:sum(order_amount) as sum_amount,count(userkey) as count_user;
执行 having,此时才开始执行 group by 后的 having 操作,对 count_user 进行过滤,注意:因为上一步输出的只有 select 的两个字段了,所以 having 的过滤字段只能是这两个字段;
执行 limit,限制输出的行数为 10。
上面这个执行顺序到底对不对呢,我们可以通过 explain 执行计划来看下,内容过多,我们分阶段来看。
首先看下 sql 语句的执行依赖:

我们看到 Stage-5 是根,也就是最先执行 Stage-5,Stage-2 依赖 Stage-5,Stage-0 依赖 Stage-2。
首先执行 Stage-5:
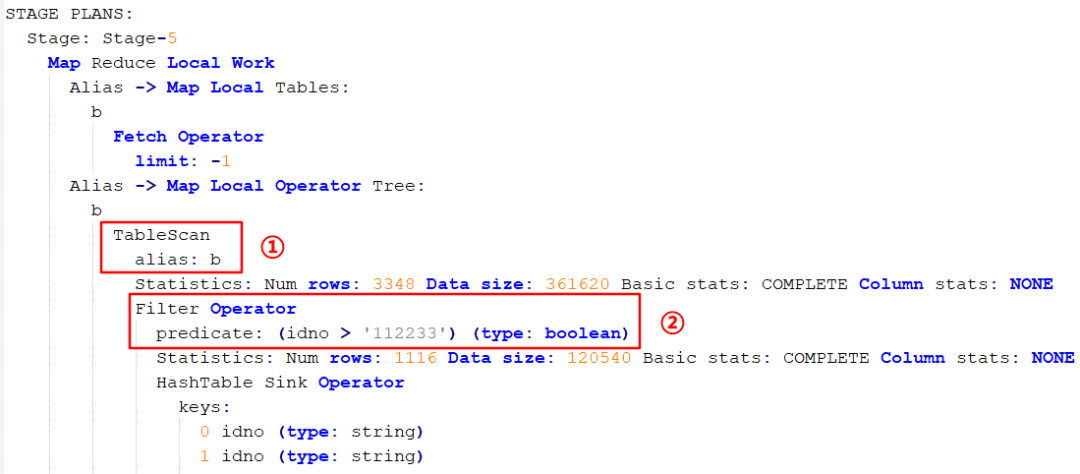
图中标 ① 处是表扫描操作,注意先扫描的 b 表,也就是 left join 后面的表,然后进行过滤操作(图中标 ② 处),我们 sql 语句中是对 a 表进行的过滤,但是 Hive 也会自动对 b 表进行相同的过滤操作,这样可以减少关联的数据量。
接下来执行 Stage-2:首先是 Map 端操作:
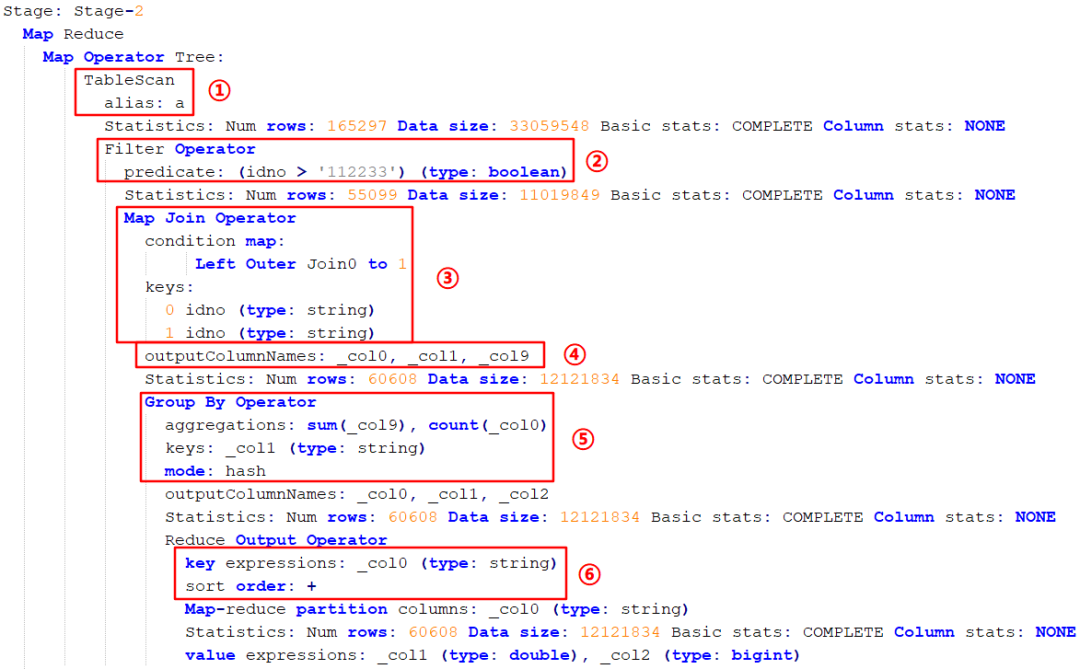
先扫描 a 表(图中标 ① 处);接下来进行过滤操作 idno > '112233'(图中标 ② 处);然后进行 left join,关联的 key 是 idno(图中标 ③ 处);执行完关联操作之后会进行输出操作,输出的是三个字段,包括 select 的两个字段加 group by 的一个字段(图中标 ④ 处);然后进行 group by 操作,分组方式是 hash(图中标 ⑤ 处);然后进行排序操作,按照 idno 进行正向排序(图中标 ⑥ 处)。
然后是 Reduce 端操作:

首先进行 group by 操作,注意此时的分组方式是 mergepartial 合并分组(图中标 ① 处);然后进行 select 操作,此时输出的字段只有两个了,输出的行数是 30304 行(图中标 ② 处);接下来执行 having 的过滤操作,过滤出 count_user>1 的字段,输出的行数是 10101 行(图中标 ③ 处);然后进行 limit 限制输出的行数(图中标 ④ 处);图中标 ⑤ 处表示是否对文件压缩,false 不压缩。
执行计划中的数据量只是预测的数据量,不是真实运行的,所以数据可能不准!
最后是 Stage-0 阶段:

限制最终输出的行数为 10 行。
总结
通过上面对 SQL 执行计划的分析,总结以下几点:
每个 stage 都是一个独立的 MR,复杂的 hive sql 语句可以产生多个 stage,可以通过执行计划的描述,看看具体步骤是什么。
对于 group by 的 key,必须是表中的字段,对于 having 的 key,必须是 select 的字段。
order by 是在 select 后执行的,所以 order by 的 key 必须是 select 的字段。
select 最好指明字段,select * 会增加很多不必要的消耗(CPU、IO、内存、网络带宽)。
