一文了解如何使用CNN进行图像分类
磐创AI介绍
在计算机视觉中,我们有一个卷积神经网络,它非常适用于计算机视觉任务,例如图像分类、对象检测、图像分割等等。
图像分类是当今时代最需要的技术之一,它被用于医疗保健、商业等各个领域,因此,了解并制作最先进的计算机视觉模型是AI的一个必须的领域。
在本文中,我们将学习涵盖CNN 的基础知识和高级概念,然后我们将构建一个模型,使用 Tensorflow 将图像分类为猫或狗,然后我们将学习高级计算机视觉,其中将涵盖迁移学习以及我们将使用**卷积神经网络 (CNN)**构建多图像分类器。
卷积神经网络
卷积神经网络 (CNN)是一种用于处理图像的神经网络,这种类型的神经网络从图像中获取输入并从图像中提取特征,并提供可学习的参数以有效地进行分类、检测和更多任务。
我们使用称为“过滤器”的东西从图像中提取特征,我们使用不同的过滤器从图像中提取不同的特征。
让我们举个例子,你正在构建一个分类模型来检测图像是猫还是非猫。因此,我们有不同的过滤器用于从图像中提取不同的特征,例如在这种情况下,一个过滤器可以学习检测猫的眼睛,另一个可以学习检测耳朵等。
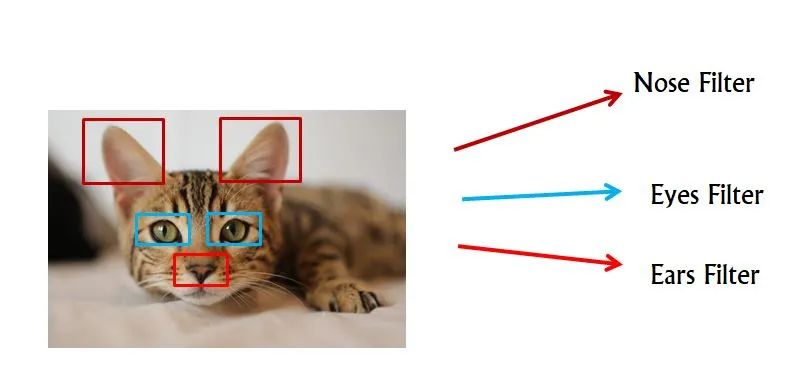
我们如何使用这些过滤器提取信息?
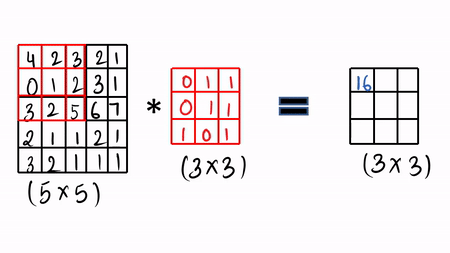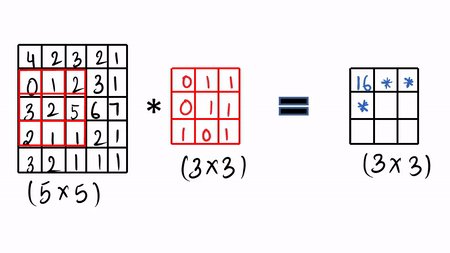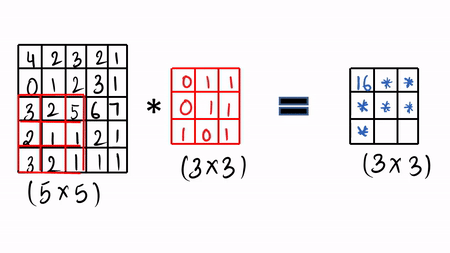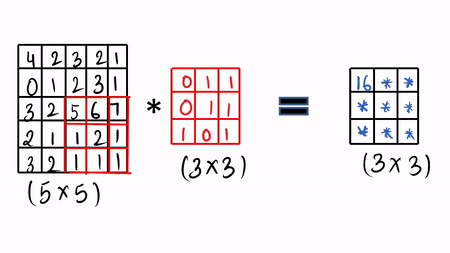
我们使用过滤器和卷积操作来卷积我们的图像,让我们通过一些可视化来详细了解。我们采用图像(5 x 5),这里我们有灰度图像,然后采用可学习的过滤器(3 x3),接着进行卷积操作。
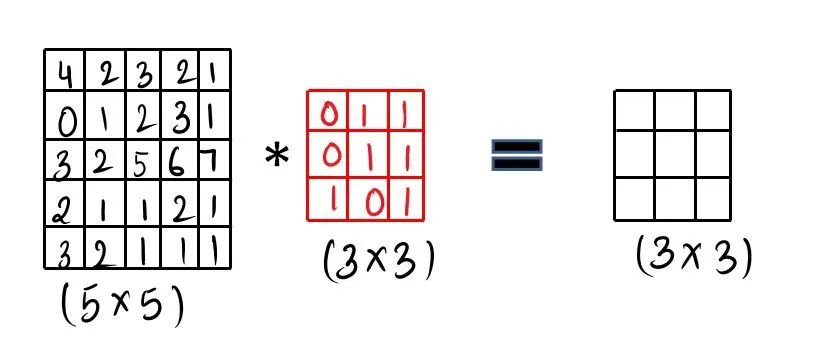
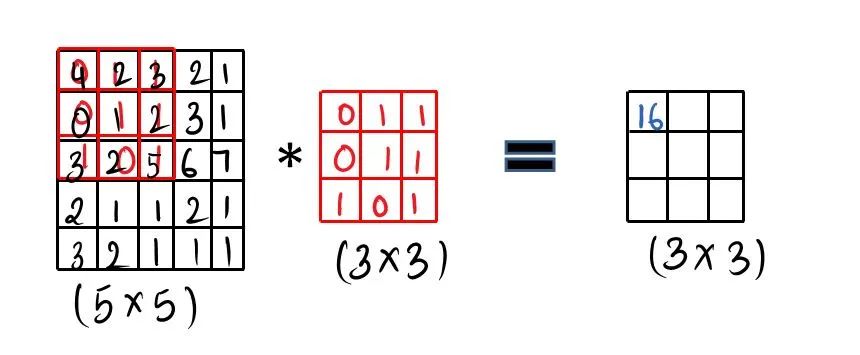
步骤1: 做元素乘积,然后把它加起来,然后填充第一个单元格。[ 4 * 0 + 1 * 2 + 1 * 3 + 0 * 0 + 1 * 1 + 2 * 1 + 3 * 1 + 2 * 0 + 5 * 1 = 16 ]
然后滑动 1 倍,再次做同样的事情,这就是所谓的卷积操作,只需做元素乘积并将其求和。可以查看 GIF 格式的可视化。
你可能会问一个问题,我们如何处理 RGB 比例或彩色图像,你必须这样做:
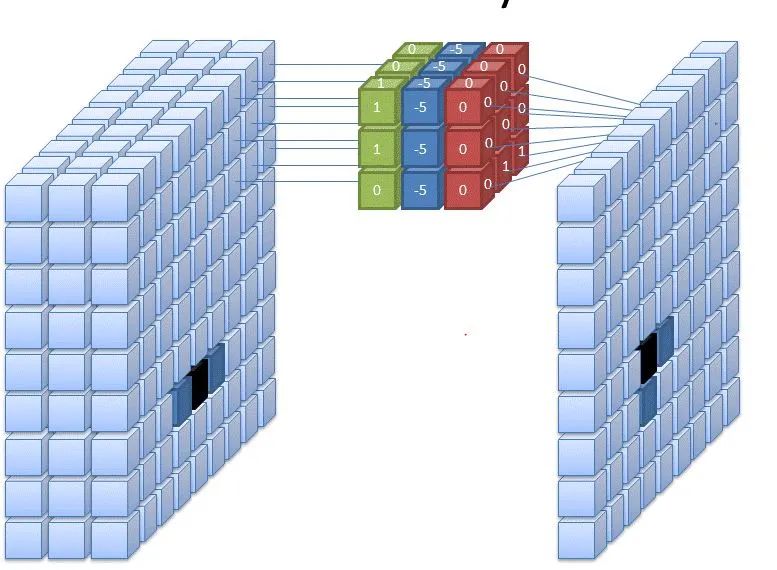
1) 步幅卷积在上面的例子中,我们用因子 1 滑过我们的图像,所以为了更快地计算图像,所以在下面的例子中,我们用因子 2 滑过图像。
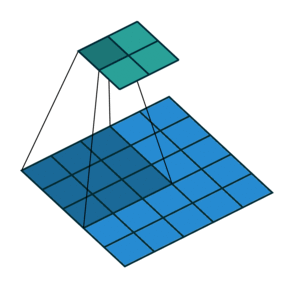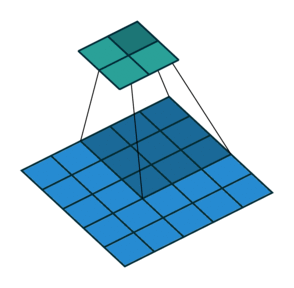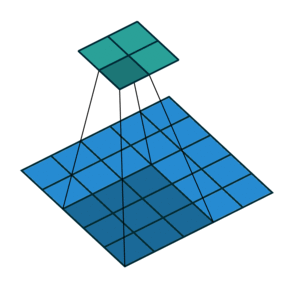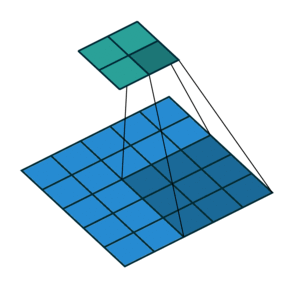
2) 填充在卷积运算中,我们经常会丢失一些信息,因此为了保留信息,我们用零填充图像,然后开始对图像进行卷积。
3) 池化层为了在保留信息的同时对图像进行下采样,我们使用池化层,我们有两种类型的池化层,即最大池化和平均池化。
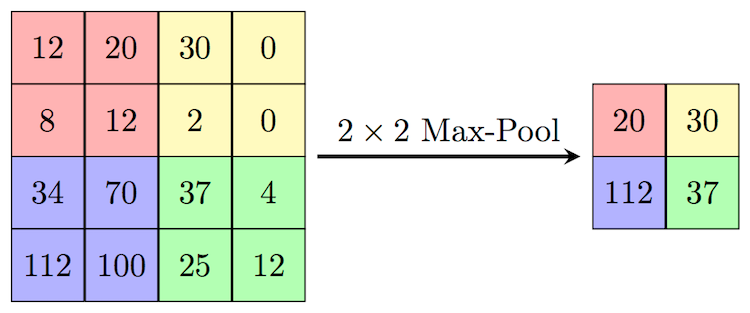
在上图中,我们正在做最大池化,而且如果你想使用平均池化,那么你可以取平均值而不是最大值。
4) 上采样层为了对图像进行上采样或使图像变大,你可以使用这些类型的图层,它有时会模糊你的图像或其他缺点。
5) 了解尺寸在你的图像被卷积之后,你将如何了解尺寸?这里是计算卷积后图像尺寸的公式:((n-f+2p)/s) + 1n 是输入的大小,如果你有一个 32x32x3 的图像,那么 n 将为 32。f 是过滤器的大小,如果过滤器的大小是 3×3,那么 f 将是 3。p 是填充。s 是你要滑动的系数对CNN的了解就到此为止,希望大家对CNN有所了解,我们会构建一个完整的CNN进行分类。图像分类图像分类:它是从图像中提取信息并对图像进行标记或分类的过程。有两种分类:二元分类:在这种类型的分类中,我们的输出是二进制值 0 或 1,让我们举个例子,给你一张猫的图像,你必须检测图像是猫的还是非猫的。多类分类:在这种类型的分类中,我们的输出将是多类的,让我们举个例子,给你一个图像,你必须在 37 个类中检测狗的品种。
使用 CNN 构建猫狗图像分类器问题陈述:我们得到一个图像,我们需要制作一个模型来分类该图像是猫还是狗。数据集:我正在使用来自 kaggle 的猫和狗数据集,你可以找到链接。方法:Github链接:步骤1)导入必要的库import numpy as np
import pandas as pd
import os
from pathlib import Path
import glob
import seaborn as sns
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import Model
from tensorflow.keras.optimizers import RMSprop
from keras_preprocessing.image import ImageDataGenerator
步骤2) 加载数据和基本 EDAdata_dir = Path('../input/cat-and-dog') # data directory
train_dir = data_dir / "training_set/training_set"
test_dir = data_dir / "test_set/test_set"
cat_samples_dir_train = train_dir / "cats" # directory for cats images
dog_samples_dir_train = train_dir / "dogs" # directory for dogs images
def make_csv_with_image_labels(CATS_PATH, DOGS_PATH):
'''
Function for making a dataframe that contains images path as well as their labels.
Parameters:-
- CATS_PATH - Path for Cats Images
- DOGS_PATH - Path for Dogs Images
Output:-
It simply returns dataframe
'''
cat_images = CATS_PATH.glob('*.jpg')
dog_images = DOGS_PATH.glob('*.jpg')
df = []
for i in cat_images:
df.append((i, 0)) # appending cat images as 0
for j in dog_images:
df.append((i, 1)) # appending dog images as 0
df = pd.DataFrame(df, columns=["image_path", "label"], index = None) # converting into dataframe
df = df.sample(frac = 1).reset_index(drop=True)
return df
train_csv = make_csv_with_image_labels(cat_samples_dir_train,dog_samples_dir_train)
train_csv.head()
现在,我们将可视化每个类的图像数量。len_cat = len(train_csv["label"][train_csv.label == 0])
len_dog = len(train_csv["label"][train_csv.label == 1])
arr = np.array([len_cat , len_dog])
labels = ['CAT', 'DOG']
print("Total No. Of CAT Samples :- ", len_cat)
print("Total No. Of DOG Samples :- ", len_dog)
plt.pie(arr, labels=labels, explode = [0.2,0.0] , shadow=True)
plt.show()

步骤3)准备训练和测试数据def get_train_generator(train_dir, batch_size=64, target_size=(224, 224)):
'''
Function for preparing training data
'''
train_datagen = ImageDataGenerator(rescale = 1./255., # normalizing the image
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size = batch_size,
color_mode='rgb',
class_mode = 'binary',
target_size = target_size)
return train_generator
train_generator = get_train_generator(train_dir)
Output :- Found 8005 images belonging to 2 classes.
现在,我们将准备测试数据,def get_testgenerator(test_dir,batch_size=64, target_size=(224,224)):
'''
Function for preparing testing data
'''
test_datagen = ImageDataGenerator( rescale = 1.0/255. )
test_generator = test_datagen.flow_from_directory(test_dir,
batch_size = batch_size,
color_mode='rgb',
class_mode = 'binary',
target_size = target_size)
return test_generator
test_generator = get_testgenerator(test_dir)
Output:- Found 2023 images belonging to 2 classes.
步骤4)构建模型现在,我们将开始构建我们的模型,下面是在 Tensorflow 中实现的完整架构。我们将从具有 64 个滤波器的卷积块开始,内核大小为 (3×3),步幅为 2,然后是 relu 激活层。然后我们将以同样的方式改变过滤器,最后我们添加了 4 个全连接层,因为这是二元分类,所以我们的最后一个激活层是 sigmoid。model = tf.keras.Sequential([
layers.Conv2D(64, (3,3), strides=(2,2),padding='same',input_shape= (224,224,3),activation = 'relu'),
layers.MaxPool2D(2,2),
layers.Conv2D(128, (3,3), strides=(2,2),padding='same',activation = 'relu'),
layers.MaxPool2D(2,2),
layers.Conv2D(256, (3,3), strides=(2,2),padding='same',activation = 'relu'),
layers.MaxPool2D(2,2),
layers.Flatten(),
layers.Dense(158, activation ='relu'),
layers.Dense(256, activation = 'relu'),
layers.Dense(128, activation = 'relu'),
layers.Dense(1, activation = 'sigmoid'),
])
model.summary()
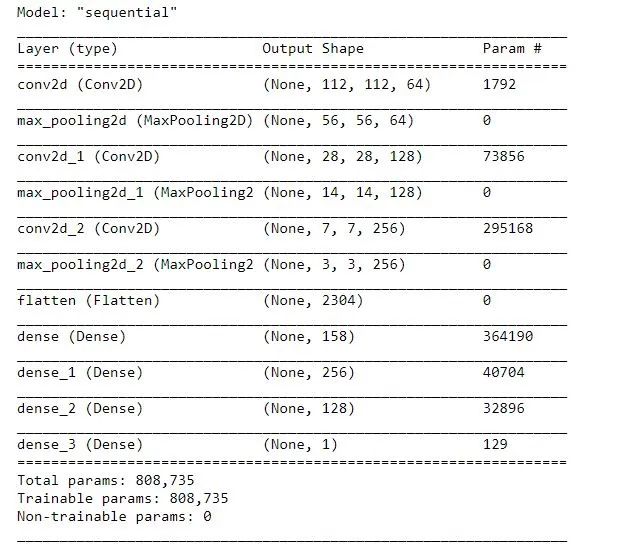
构建模型步骤5)编译和训练模型model.compile(optimizer=RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['acc'])
history = model.fit_generator(train_generator,
epochs=15,
verbose=1,
validation_data=test_generator)
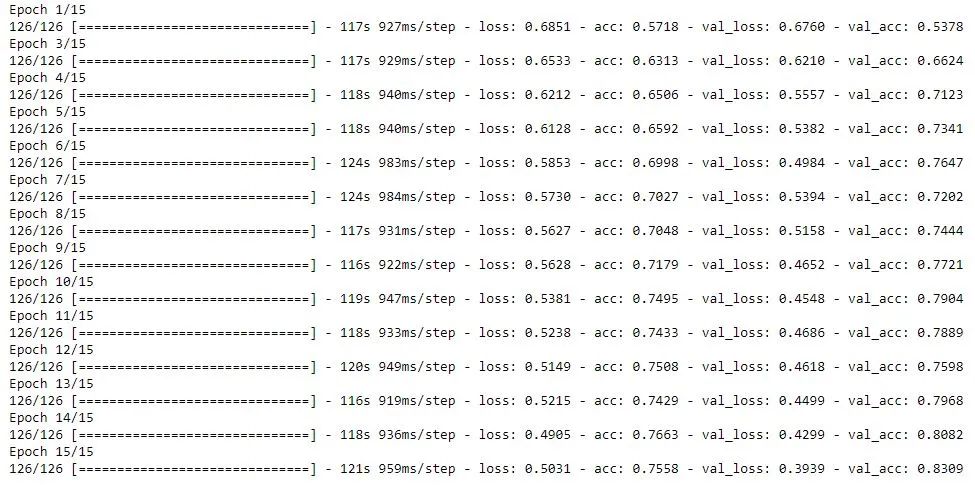
编译和训练模型步骤6)评估模型import matplotlib.image as mpimg
import matplotlib.pyplot as plt
acc=history.history['acc']
val_acc=history.history['val_acc']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(len(acc))
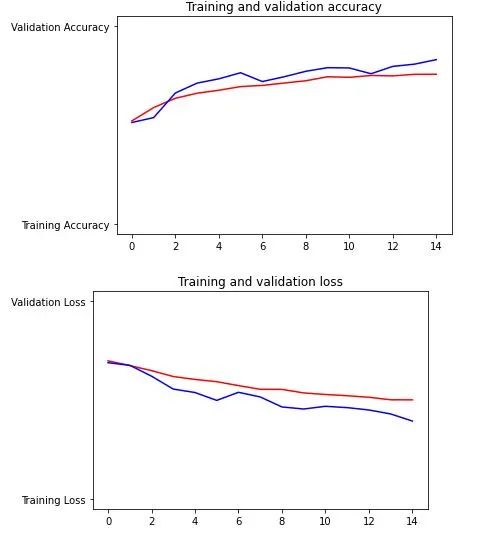
plt.plot(epochs, acc, 'r', "Training Accuracy")
plt.plot(epochs, val_acc, 'b', "Validation Accuracy")
plt.title('Training and validation accuracy')
plt.figure()
plt.plot(epochs, loss, 'r', "Training Loss")
plt.plot(epochs, val_loss, 'b', "Validation Loss")
plt.title('Training and validation loss')
model.save('my_model.h5') # saving the trained model
new_model = tf.keras.models.load_model('./my_model.h5') # loading the trained model
迁移学习迁移学习背后的基本直觉是,你使用一个预先训练好的模型,该模型已经在更大的数据集上训练过,并进行了大量的超参数调整,你只需删除一些层就可以根据数据对这个模型进行微调。它可以帮助你将知识从一种模型转移到另一种模型。
