亚马逊门铃系统上的人脸识别是如何实现的?
磐创AI作为一个新的亚马逊门铃的买家,我喜欢它提供的炫酷功能。然而,我认为我可以做一些改进。我需要的是为住在我家的人定制的门铃。要是门铃能认出是谁在敲门就好了。看到门铃是多么的受欢迎,我决定帮助大多数家庭,最好方法是让他们能够毫不费力地定制他们的门铃。我开发了一个应用程序,可以告诉你谁在你的门口,只需输入你的门铃帐户的用户名和密码。知道谁在你的门口,无需等待门铃在你的智能手机上显示视频,这是非常方便的。它大大提高了安全性,带来了极大的便利,甚至可以安装在一个自动开门的系统上。在深度学习时代,每个家庭都需要安装这些系统。下图说明了我的系统是如何工作的。
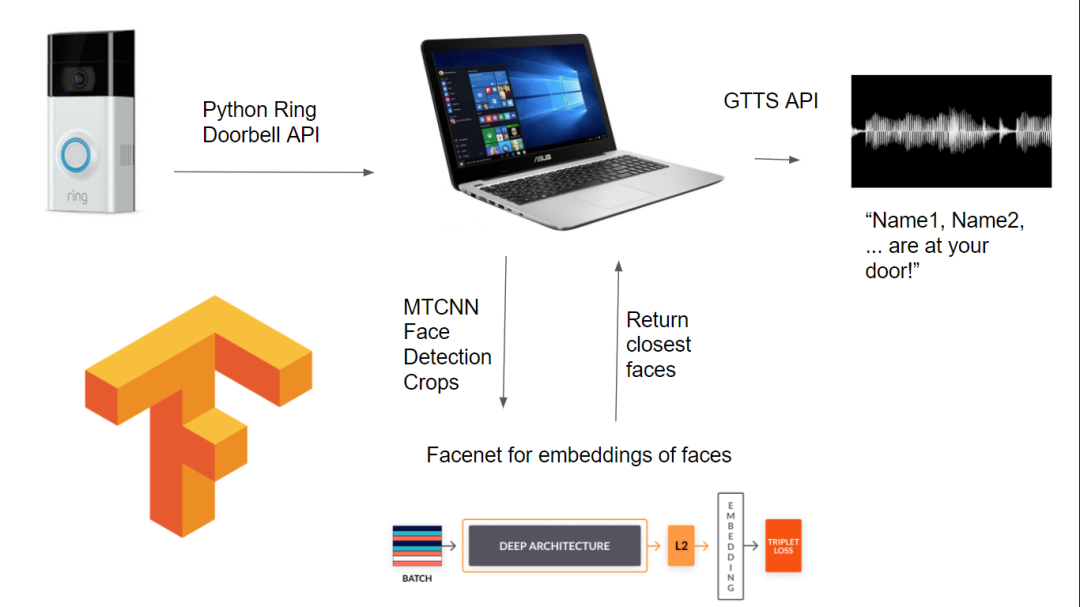
完整的代码可以在这里的Git存储库中找到。https://github.com/dude123studios/SmarterRingV2要求如下:tensorflow==2.4.1
opencv-python==4.5.1.48
mtcnn==0.1.0
ring_doorbell==0.7.0
oauthlib~=3.1.0
numpy~=1.19.5
scipy~=1.6.1
scikit-learn==0.24.1
gtts==2.2.2
playsound~=1.2.2
让我们来分析一下发生了什么。通过输入用户名和密码作为环境变量,Ring API就能够连接到你的帐户。该API允许用户访问python特性。这里(https://github.com/tchellomello/python-ring-doorbell)有API存储库和简短的文档。这是Ring.py的一个片段,它实例化了一个与你的门铃的连接:import os
import json
from pathlib import Path
from ring_doorbell import Ring, Auth
from oauthlib.oauth2 import MissingTokenError
cache_file = Path("test_token.cache")
def token_updated(token):
cache_file.write_text(json.dumps(token))
def otp_callback():
auth_code = input("[INPUT] 2FA code: ")
return auth_code
def main(download_only=False):
if cache_file.is_file():
auth = Auth("MyProject/1.0", json.loads(cache_file.read_text()), token_updated)
else:
username = os.environ.get('USERNAME')
password = os.environ.get('PASSWORD')
auth = Auth("MyProject/1.0", None, token_updated)
try:
auth.fetch_token(username, password)
except MissingTokenError:
auth.fetch_token(username, password, otp_callback())
ring = Ring(auth)
ring.update_data()
wait_for_update(ring, download_only=download_only)
wait_for_update方法持续运行并实例化一个正在等待客户端的处理程序。它会继续刷新,直到发现Ring的存储历史记录有更新。一旦发生这种情况,它检查门铃是否被按了。如果是这样,它会把整个视频下载到你的设备上。为了加快这一过程,请使用智能手机上的ring应用程序缩小视频录制的大小。你的门铃响了,最后一段视频就会传到你的电脑上。从那里,我们截取了那段视频的多个帧,以确保一个人的脸都不会被遮住。我在utils.py中定义了这个方法。它将在稍后显示。下面是ring.py的另一个片段。用于处理主线程:import time
def wait_for_update(ring, download_only=False):
id = -1
start = time.time()
while True:
try:
ring.update_data()
except:
time.sleep(1)
continue
doorbell = ring.devices()['authorized_doorbots'][0]
for event in doorbell.history(limit=20, kind='ding'):
current_id = event['id']
break
if current_id != id:
id = current_id
print('[INFO] finished search in:', str(time.time() - start))
start = time.time()
if download_only:
handle_video(ring, True)
return
handle = handle_video(ring)
if handle:
text_to_speech(handle)
else:
text_to_speech('The person at the door is not very clear')
time.sleep(1)
如果你对identify、get_first_frame和text_to_speech方法调用有点困惑,不要担心!我们就要谈到这个了!现在我们的处理程序已经就位,让我们开始面部识别吧!FaceNetFaceNet是谷歌在2015年开发的一个模型。FaceNet使用一种称为聚类的过程
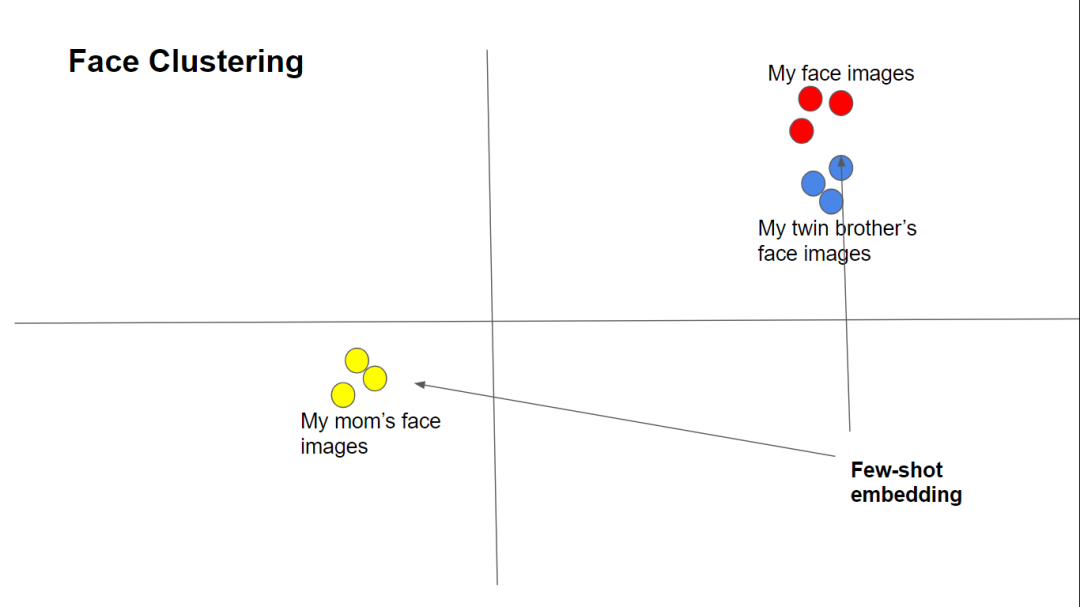
聚类的目的是创建一种嵌入,就像单词一样。唯一的区别是,该模型不是学习向量标记的id,而是将图像压缩到一个小的潜在空间。具体来说,给定一幅形状为(160,160,3)的图像,FaceNet模型,产生一个形状为(128)的矢量,称为它的嵌入。该模型将确保不同人的面孔在嵌入空间中的距离较远,同一个人的面孔距离较近。这样,一个人无论在什么样的光线条件下,从什么样的角度,或者什么妆容,都可以被认出来。FaceNet架构FaceNet类似于ResNet和InceptionV3。架构如下所示。输入图像经过1x1Conv层和2x2Pooling层,然后沿着深度ResNet下行,由成对的Inception层和残差连接层组成。最后的层包含多个3x3Conv、Concat和2x2Pooling层。
1 2 下一页>
