构建自定义CNN模型:识别COVID-19
磐创AI本文让我们从头开始,通过训练和测试我们的自定义图像数据集,来构建我们自己的自定义CNN(卷积神经网络)模型。
我们将使用验证集方法来训练模型,从而将我们的数据集划分为训练、验证和测试数据集。
在结束时,你将能够为 COVID-19 构建你自己的自定义 CNN 模型,通过使用你自己的数据集进行训练来执行多类图像分类!
此外,我们还将通过获取其分类报告和混淆矩阵,在验证和测试数据集上彻底评估训练模型。此外,我们还将使用 Streamlit 创建一个漂亮而简单的前端,并将我们的模型与 Web 应用程序集成。
目前已经使用 Google Colab 进行所有实施。此外,已将数据集上传到项目的Google drive 。Streamlit Web 应用程序可以从 Google Colab 轻松启动。
那么,让我们开始吧!
目录
· 介绍
· 应用
· 执行
· 结论
介绍
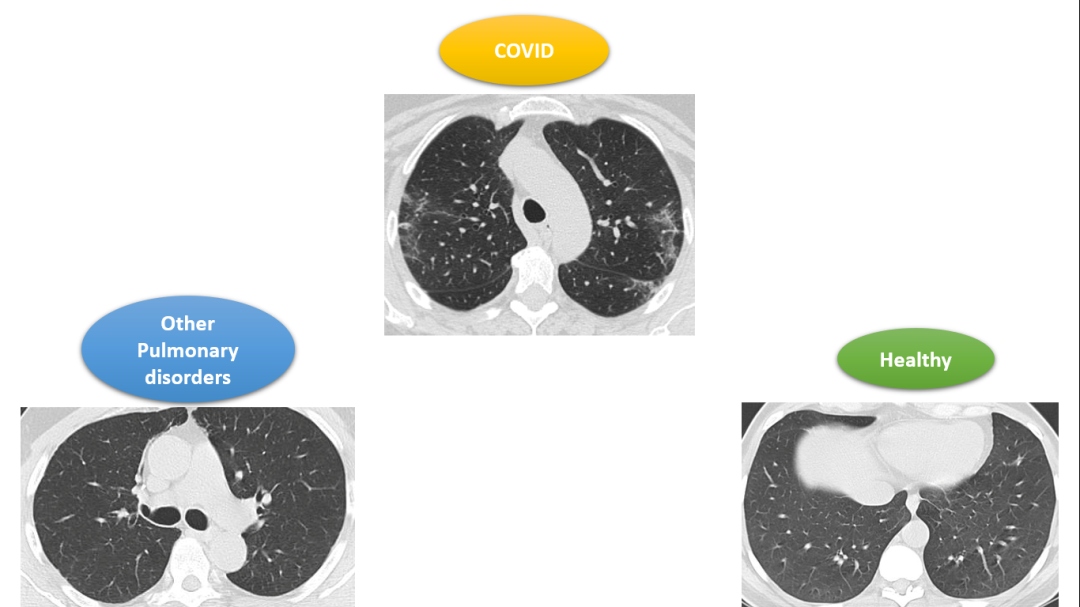
首先,自定义数据集是你自己准备的数据集,就像你去外面玩并拍摄照片以收集你感兴趣的图像一样,或者从知名网站下载并使用开源图像数据集来获取数据集,例如 Kaggle、GitHub 等。
总而言之,它是你自己的数据集,其中你将所需类的图像存储在不同的文件夹中——每个类的文件夹。
在本文中,将解释如何使用 TensorFlow 在 CT 扫描的 COVID 多类数据集之一上为 COVID-19 构建 CNN 模型。可以直接从这里下载。现在,暂停并确保你下载数据集以跟随实施。
给定的 Kaggle 数据集包括患有新型 COVID-19、其他肺部疾病和健康患者的患者的胸部 CT 扫描图像。对于这三个类别中的每一个,都有多个患者,并且对于每个类别,都有相应的多个 CT 扫描图像。
我们将使用这些 CT 扫描图像来训练我们的 CNN 模型,以识别给定的 CT 扫描是 COVID 患者、患有除 COVID 以外的其他肺部疾病的患者,还是健康患者的 CT 扫描。该问题包括 3 类,即:COVID、健康和其他肺部疾病,简称为“其他”。
应用
我们知道,进行 RTPCR 检测 COVID 是有风险的,因为拭子检测通过鼻子到达喉咙,导致咳嗽,从而将病毒颗粒传播到空气中,从而危及卫生工作者的生命。
因此,研究人员表示,CT 扫描比此类拭子测试更安全。此外,建议在对 COVID 阳性患者进行 RTPCR 测试后进行 CT 扫描测试。
这就是我们现在正在做的项目可以证明对医学界有帮助的地方。
执行
Step-1:图像预处理
Step-2:训练-测试-验证拆分
Step-3:模型构建
Step-4:模型评估
Step-5:构建 Streamlit Web 应用程序
首先,让我们导入所有需要的包,如下所示:
from tensorflow.keras.layers import Input, Lambda, Dense, Flatten,Dropout,Conv2D,MaxPooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing import image
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
import numpy as np
import pandas as pd
import os
import cv2
import matplotlib.pyplot as plt
Step-1 图像预处理
每当我们处理图像数据时,图像预处理是第一步,也是最关键的一步。
在这里,我们将所有图像重新缩放为所需的大小(在这个项目中为 100×100)并将它们除以 255 进行标准化。
根据我们数据集的目录结构,如上一节所述,我们必须遍历文件夹 2(患者文件夹)中存在的每个图像,该图像进一步存在于文件夹 1(类别文件夹:COVID、健康或其他)。
因此,相同的代码是这样的:
# re-size all the images to this
IMAGE_SIZE = (100,100)
path="/content/drive/MyDrive/MLH Project/dataset"
data=[]
c=0
for folder in os.listdir(path):
sub_path=path+"/"+folder
for folder2 in os.listdir(sub_path):
sub_path2=sub_path+"/"+folder2
for img in os.listdir(sub_path2):
image_path=sub_path2+"/"+img
img_arr=cv2.imread(image_path)
try:
img_arr=cv2.resize(img_arr,IMAGE_SIZE)
data.append(img_arr)
except:
c+=1
continue
print("Number of images skipped= ",c)
注意:在案例中可能会跳过两个图像。我们可以忽略它们,因为只是 2 张图像,而不是跳过大量的图像。
下面的代码执行图像的标准化:
x=np.array(data)
x=x/255.0
现在,由于我们的自定义数据集在文件夹中有图像,我们如何获取标签?
使用 ImageDataGenerator 以及以下代码实现:
datagen = ImageDataGenerator(rescale = 1./255)
dataset = datagen.flow_from_directory(path,
target_size = IMAGE_SIZE,
batch_size = 32,
class_mode = 'sparse')
此外,要注意类的索引并将这些类分配为标签,请使用以下代码:
dataset.class_indices
y=dataset.classes
y.shape
运行上面的代码,你将观察到以下索引已用于相应的类:
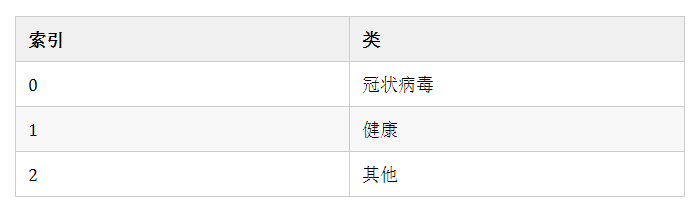
注意:在这一步的最后,所有的图像都将被调整到100×100,尽管它们是CT扫描,但它们已被作为彩色图像提供在选定的Kaggle数据集中。这就是为什么当我们在下一节中尝试查看 x_train,x_val 和 x_test 的形状时,会得到100x100x3。这里,3表示彩色图像(R-G-B)
Step-2:训练-测试-验证拆分
在这一步中,我们将数据集划分为训练集、测试集和验证集,以便使用验证集方法来训练我们的模型,以便在 COVID、健康或其他的 CT 扫描中进行分类。
我们可以使用传统的 sklearn 来实现。
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.1)
x_train,x_val,y_train,y_val=train_test_split(x_train,y_train,test_size=0.2)
此外,使用以下代码查看每个数据集的大小:
x_train.shape,y_train.shape
x_val.shape,y_val.shape
x_test.shape,y_test.shape
从上面的代码中,你将观察到 3002 幅图像属于训练集,751 幅图像属于验证集,418 幅图像属于测试集。
Step-3 模型构建
现在,我们都准备好从头开始为 COVID-19 编码我们的 CNN 模型了。为此,我们只需要不断添加层,主要是 Conv2D 来提取特征,MaxPooling2D 来执行图像的下采样。
此外,还使用了 BatchNormalization 层来提高模型在训练和验证准确性方面的性能。
因此,我们可以编写我们自己的 CNN 模型,如下所示:
model=Sequential()
#covolution layer
model.add(Conv2D(32,(3,3),activation='relu',input_shape=(100,100,3)))
#pooling layer
model.add(MaxPooling2D(2,2))
model.add(BatchNormalization())
#covolution layer
model.add(Conv2D(32,(3,3),activation='relu'))
#pooling layer
model.add(MaxPooling2D(2,2))
model.add(BatchNormalization())
#covolution layer
model.add(Conv2D(64,(3,3),activation='relu'))
#pooling layer
model.add(MaxPooling2D(2,2))
model.add(BatchNormalization())
#covolution layer
model.add(Conv2D(64,(3,3),activation='relu'))
#pooling layer
model.add(MaxPooling2D(2,2))
model.add(BatchNormalization())
#i/p layer
model.add(Flatten())
#o/p layer
model.add(Dense(3,activation='softmax'))
model.summary()
卷积神经网络由几个卷积层和池化层组成。我添加了四个 Conv2D 和 MaxPooling 层。Conv2D 层的第一个参数是我们必须在其中进行大量操作以达到最佳模型。
你可以从 Keras 官方文档中了解更多关于 Conv2D、MaxPooling2D 和 BatchNormalization 的语法。
添加卷积层和最大池化层后,包含了 BatchNormalization 层,然后使用 Flatten() 函数添加了输入层。
这里没有隐藏层,因为它们对提高模型在训练期间的性能没有用处。
最后,添加了输出层,它确实给了我们最后的输出!Dense() 函数也用于相同的目的。它需要参数 3,因为我们有 3 个类别:COVID、健康和其他。
此外,这里使用的激活函数是 softmax 函数,因为这是一个多类问题。
这是模型架构。现在,在我们训练它之前,我们必须按如下方式编译它:
使用的优化器是常见的 Adam 优化器。由于所考虑的数据集的标签是分类的而不是独热编码的,我们必须选择稀疏分类交叉熵损失函数。
提前停止用于避免过度拟合。当它开始过度拟合时,它会停止训练我们的模型,而过拟合又通过验证损失的突然增加被识别出来。
#compile model:
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
提前停止可用于避免过度拟合。这样做是因为我们不知道我们的模型必须训练多少个 epoch。
from tensorflow.keras.callbacks import EarlyStopping
early_stop=EarlyStopping(monitor='val_loss',mode='min',verbose=1,patience=5)
#Early stopping to avoid overfitting of model
现在,让我们最终训练我们的自定义 CNN 模型,比如 30 个 epoch:
history=model.fit(x_train,y_train,validation_data=(x_val,y_val),epochs=30,callbacks=[early_stop],shuffle=True)
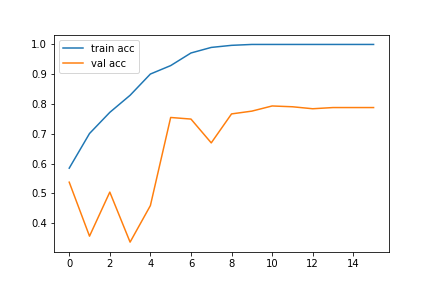
在第 16 个 epoch 遇到了提前停止,因此模型只训练了 16 个 epoch,在结束时它显示出 100% 的训练准确度和 78.83% 的验证准确度。
Step-4 模型评估
可视化我们的模型训练的最佳方法是使用损失和准确度图。
以下代码可用于获取我们训练的模型的损失和准确度图:
#loss graph
plt.plot(history.history['loss'],label='train loss')
plt.plot(history.history['val_loss'],label='val loss')
plt.legend()
plt.savefig('loss-graph.png')
plt.show()
#accuracies
plt.plot(history.history['accuracy'], label='train acc')
plt.plot(history.history['val_accuracy'], label='val acc')
plt.legend()
plt.savefig('acc-graph.png')
plt.show()
准确率和损失图如下:
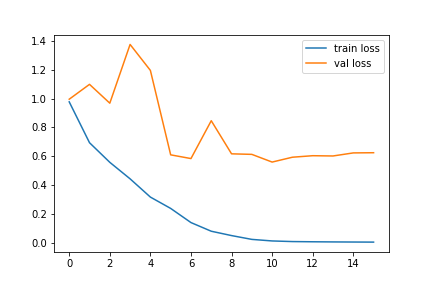
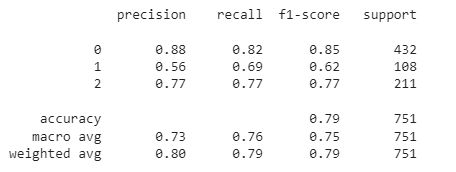
验证数据集的分类报告和混淆矩阵:
y_val_pred=model.predict(x_val)
y_val_pred=np.argmax(y_val_pred,axis=1)
print(classification_report(y_val_pred,y_val))
confusion_matrix(y_val_pred,y_val)

因此,可以清楚地得出结论,我们用于 COVID CT 扫描的 CNN 模型是最好的。它显示了其他肺部疾病类别的平均表现。
然而,它对健康患者的表现相对较差。此外,我们的模型在验证数据集上显示出 79% 的准确率。
测试数据集的分类报告和混淆矩阵,这对我们的模型来说是全新的:
y_pred=model.predict(x_test)
y_pred=np.argmax(y_pred,axis=1)
print(classification_report(y_pred,y_test))
confusion_matrix(y_pred,y_test)
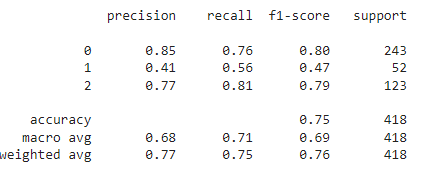

它在测试数据集上显示了 75% 的准确度,与验证数据集的性能相似。
总的来说,我们可以得出结论,我们已经从头开始为 COVID-19 开发了一个现实的 CNN 模型。
现在让我们使用以下代码保存模型:
model.save('/content/drive/MyDrive/MLH Project/model-recent.h5')
Step-5 构建 Streamlit Web 应用程序
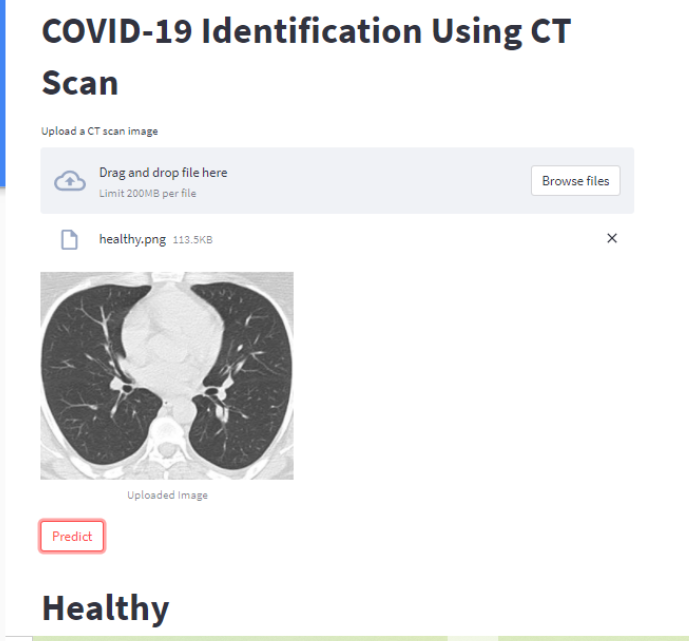
在这一步中,我们将使用 Streamlit 创建一个前端,用户可以在其中上传胸部 CT 扫描的图像。单击“预测”按钮将输入图像预处理为 100×100,这是我们用于 COVID-19 的 CNN 模型的输入形状,然后将其发送到我们的模型。
为了检查我们的模型预测该图像是哪个类别,我们使用 np.argmax() 函数获得对应于最大值的索引,从而根据步骤 1 表中讨论的标签索引得出结论。
首先,我们必须安装 Streamlit 并导入 ngrok:
!pip install streamlit --quiet
!pip install pyngrok==4.1.1 --quiet
from pyngrok import ngrok
然后是实际代码。
这里,我们主要加载保存的模型——h5文件,并使用它进行预测。模型文件的名称是 model-recent.h5。可以选择直接从本地系统上传图像并检查其类别 - 如果 CT 扫描是 COVID 或健康或其他肺部疾病。
st. button(‘Predict’) 创建一个写有“Predict”的按钮,并在用户单击按钮时返回 True。st.title() 使其参数中的文本以深色粗体显示。
这些是要讨论的一些 Streamlit 功能。
%%writefile app.py
import streamlit as st
import tensorflow as tf
import numpy as np
from PIL import Image # Strreamlit works with PIL library very easily for Images
import cv2
model_path='/content/drive/MyDrive/MLH Project/model-recent.h5'
st.title("COVID-19 Identification Using CT Scan")
upload = st.file_uploader('Upload a CT scan image')
if upload is not None:
file_bytes = np.asarray(bytearray(upload.read()), dtype=np.uint8)
opencv_image = cv2.imdecode(file_bytes, 1)
opencv_image = cv2.cvtColor(opencv_image,cv2.COLOR_BGR2RGB)
# Color from BGR to RGB
img = Image.open(upload)
st.image(img,caption='Uploaded Image',width=300)
if(st.button('Predict')):
model = tf.keras.models.load_model(model_path)
x = cv2.resize(opencv_image,(100,100))
x = np.expand_dims(x,axis=0)
y = model.predict(x)
ans=np.argmax(y,axis=1)
if(ans==0):
st.title('COVID')
elif(ans==1):
st.title('Healthy')
else:
st.title('Other Pulmonary Disorder')
最后,从以下位置获取 Web 应用程序的 URL:
!nohup streamlit run app.py &
url = ngrok.connect(port='8501')
url
将此 URL 粘贴到 Chrome 网络浏览器中以查看我们漂亮的应用程序。
结果
使用浏览按钮上传图像然后单击预测按钮后,你的 Web 应用程序应如下所示。
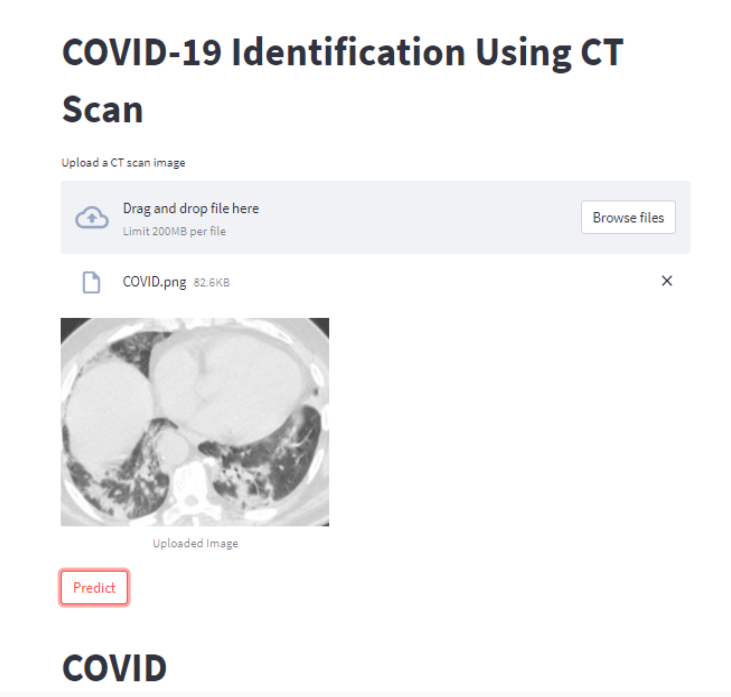
结论
因此,我们使用我们的数据集成功构建并训练了我们自己的 COVID-19 CNN 模型!相同的方法可用于两个或更多类。你所要做的就是更改输出层或模型架构的最后一层中的类数量。
