图像的主题模型
磐创AI主题建模是一个技术的集合,允许用户在大量数据中找到主题。当试图对这些文档的内容建模和执行EDA时,它将非常有利。
不久前,我们介绍了一种名为BERTopic的主题建模技术,它利用了BERT嵌入和基于类的TF-IDF创建簇,允许轻松解释主题。
不过,过了一会儿,开始考虑它在其他领域的应用,例如计算机视觉。如果我们能在图像上应用主题建模,那会有多酷?
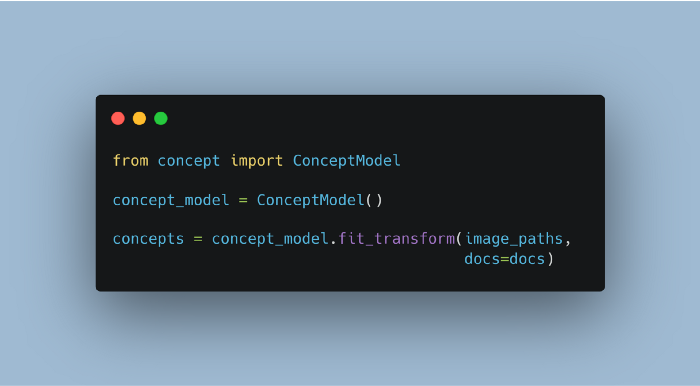
花了一段时间,但经过一些实验,想出了解决方案,Concept!
Concept是一个包,它同时在图像和文本上引入主题建模的概念。然而,由于主题通常指的是书面或口头的文字,它并不能完全封装图像的含义。相反,我们将这些分组的图像和文本称为概念。

因此,Concept包执行概念建模,这是一种统计模型,用于发现图像和相应文档集合中出现的抽象概念。
概念建模是主题建模对图像和文本的概括
例如,下面的概念通过概念建模检索:

正如你可能注意到的,我们可以通过它们的文本表示和视觉表示来解释这些概念。然而,通过组合这些表示,可以找到概念建模的真正力量。
概念建模允许概念的多模态表示
一幅图片告诉你一千多个字。但是如果我们在图像中添加单词怎么办?这两种沟通方式的协同作用,可以丰富对Concept的解读和理解。
在本文中,将介绍使用Concept创建自己的概念模型的步骤。你可以在上面的链接中跟随GoogleColab笔记本。
步骤1:安装Concept
我们可以通过PyPI轻松安装
Concept:pip install concept
步骤2:准备图像
要执行概念建模,我们需要大量的图像进行聚类。我们将从Unflash下载25000张图片
import os
import glob
import zipfile
from tqdm import tqdm
from sentence_transformers import util
# Download 25k images from Unsplash
img_folder = 'photos/'
if not os.path.exists(img_folder) or len(os.listdir(img_folder)) == 0:
os.makedirs(img_folder, exist_ok=True)
photo_filename = 'unsplash-25k-photos.zip'
if not os.path.exists(photo_filename): #Download dataset if does not exist
util.http_get('http://sbert.net/datasets/'+photo_filename, photo_filename)
#Extract all images
with zipfile.ZipFile(photo_filename, 'r') as zf:
for member in tqdm(zf.infolist(), desc='Extracting'):
zf.extract(member, img_folder)
# Load image paths
img_names = list(glob.glob('photos.jpg'))
在准备好图像之后,我们已经可以在Concept上使用它们了。但是,没有文本的话就不会创建文本表示。所以下一步是准备我们的文本。
步骤3:准备文本
Concept的有趣方面是,任何文本都可以被输入模型。理想情况下,我们希望向它提供与手头图像最相关的文本。
然而,情况可能并非总是如此。因此,为了演示目的,我们将在英语词典中为模型提供一系列名词:
import random
import nltk
nltk.download("wordnet")
from nltk.corpus import wordnet as wn
all_nouns = [word for synset in wn.all_synsets('n') for word in synset.lemma_names()
if "_" not in word]
selected_nouns = random.sample(all_nouns, 50_000)
在上面的例子中,我们使用了50000个随机名词,原因有两个。
首先,不需要在英语词典中获取所有名词,因为我们可以假设50000个名词应该代表足够的实体。
其次,这会加快计算速度,因为我们需要从较低的单词中提取嵌入。
实际上,如果你知道文本数据与图像相关,那么就用这些代替名词!
步骤4:训练模型
下一步是训练模型!一如既往,我们保持了这一相对简单的态度。只需将每个图像的路径和我们选择的名词输入模型:
from concept import ConceptModel
concept_model = ConceptModel()
concepts = concept_model.fit_transform(img_names, docs=selected_nouns)
concepts变量包含每个图像的预测的概念。
Concept的基本模型是Openai的CLIP,它是一个经过大量图像和文本对训练的神经网络。这意味着模型在生成嵌入时使用GPU是有益的。
最后,运行concept_model.frequency查看包含Concept和频率的数据帧。
注意:使用Concept(embedding_model="clip-ViT-B-32-multilingual-v1")选择支持50+语言的模型!
预训练的图像嵌入
对于那些想要尝试此演示但无法访问GPU的用户,我们可以从sentence-Transformers站点加载经过预训练的图像嵌入:
import pickle
from sentence_transformers import util
# Load pre-trained image embeddings
emb_filename = 'unsplash-25k-photos-embeddings.pkl'
if not os.path.exists(emb_filename): #Download dataset if does not exist
util.http_get('http://sbert.net/datasets/'+emb_filename, emb_filename)
with open(emb_filename, 'rb') as fIn:
img_names, image_embeddings = pickle.load(fIn)
img_names = [f"photos/{path}" for path in img_names]
然后,我们将预训练的嵌入件添加到模型中,并对其进行训练:
from concept import ConceptModel
# Train Concept using the pre-trained image embeddings
concept_model = ConceptModel()
concepts = concept_model.fit_transform(img_names,
image_embeddings=image_embeddings,
docs=selected_nouns)
步骤5:可视化Concept
如前所述,由此产生的Concept是多模态的,即视觉和文本。我们需要在一个概览中找到一种表示这两种情况的方法。
为了做到这一点,我们选取了一些最能代表每个Concept的图像,然后找到最能代表这些图像的名词。
在实践中,创建可视化非常简单:
fig = concept_model.visualize_concepts()
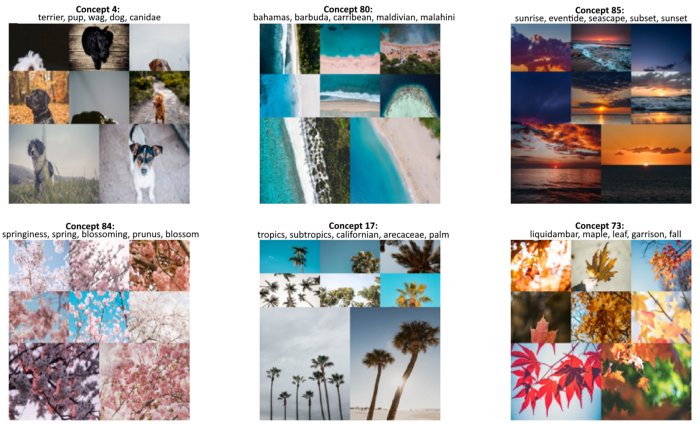
我们数据集中的许多图片都与自然有关。然而,如果我们看得更远一点,我们可以看到更有趣的概念:

上面的结果为如何在概念建模中直观地思考概念提供了一个很好的例子。我们不仅可以通过一组图像看到视觉表现,而且文本表现有助于我们进一步理解这些概念中的内容。
第6步:搜索概念
我们可以通过嵌入搜索词并找到最能代表它们的簇嵌入来快速搜索特定概念。
例如,让我们搜索“beach”一词,看看能找到什么。为此,我们只需运行以下操作:
>>> search_results = concept_model.find_concepts("beach")
>>> search_results
[(100, 0.277577825349102),
(53, 0.27431058773894657),
(95, 0.25973751319723837),
(77, 0.2560122597417548),
(97, 0.25361988261846297)]
每个元组包含两个值,第一个是概念簇,第二个是与搜索词的相似性。返回前5个类似主题。
现在,让我们可视化这些概念,看看搜索功能的工作情况:
fig = concept_model.visualize_concepts(concepts=[concept for concept, _ in search_results])

正如我们所看到的,结果概念与我们的搜索词非常相似!模型的这种多模态特性使我们能够轻松地搜索概念和图像。
第7步:算法概述
对于那些对概念基础感兴趣的人来说,下面是用于创建结果Concept的方法的摘要:
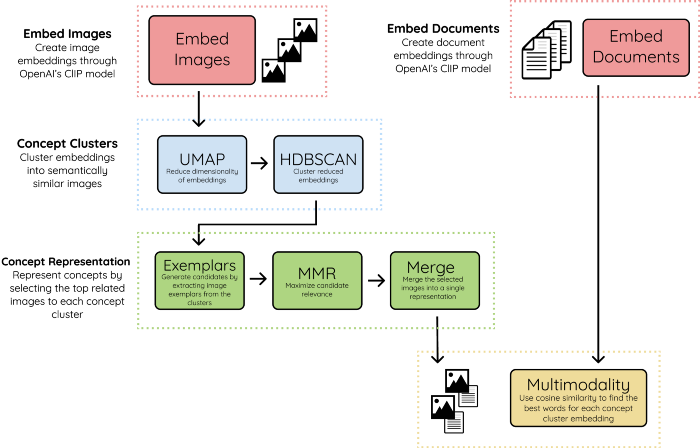
1.嵌入图像和文档
我们首先使用OpenAI的CLIP模型将图像和文档嵌入到同一个向量空间中。这使我们能够在图像和文本之间进行比较。文档可以是单词、短语、句子等。
2.概念簇
我们使用UMAP+HDBSCAN对图像嵌入进行聚类,以创建视觉和语义上彼此相似的簇。我们将簇称为Concept,因为它们代表了多模态性质。
3.概念表达
为了直观地表示概念簇,我们将每个概念的最相关图像称为范例。根据概念簇的大小,每个簇的示例数可能超过数百个,因此需要一个过滤器。
我们使用MMR来选择与Concept嵌入最相关但彼此仍然足够不同的图像。这样,我们就可以尽可能多地展示这个概念。然后将选定的图像合并为一个图像,以创建一个视觉表示。
4.多模态
最后,我们将文本嵌入与创建的概念簇嵌入进行比较。利用余弦相似性,我们选择彼此最相关的嵌入。这将多模态引入到概念表示中。
注意:还可以选择使用c-TF-IDF,使用concept_model = ConceptModel(ctfidf=True)提取文本表示
