使用Python和docTR提取车辆识别号
磐创AI
VIN(车辆识别号)是一个17个字符的字符串,由数字和大写字母组成,用作汽车的指纹。
它可以帮助识别任何一辆汽车的寿命,并获得有关它的具体信息。该唯一标识符在制造过程中打印在车辆的某个位置,以便人们在租车或销售等过程中需要时读取。
几个月前,我们的朋友联系了我们,他们来自Monk:一家AI公司,为汽车、保险和移动市场提供最先进的计算机视觉解决方案。他们正在开发一种视觉智能技术,能够在车辆生命周期的每个阶段对车辆进行检查。
他们唯一的重点是建立检测、分类和评估车辆损坏的最佳技术。能够自动读取VIN对他们来说很重要。
VIN用例
请注意,本文中VIN的任何照片都是伪造或模糊的。问题的定义很简单:
· 输入是写在汽车上的VIN的照片
· 输出是一个17个字符长的字符串:VIN

以高精度自动执行此任务比看起来要困难。主要困难是:
输入的照片大多是在室外拍摄的,有很多噪音(亮度、水渍、阴影等),这会使车辆识别码的检测和识别变得困难
· 虽然VIN是以相当标准的格式书写的,但所使用的字体并不标准,也不总是相同的,字母间距可能会有很大差异。
· 存在一种校验和验证方法来验证VIN,但它并不适用于所有车辆。我们拒绝了这个后处理解决方案。
· 最后但并非最不重要的一点是,VIN并不总是照片中唯一的文字,使用传统的OCR方法是不够的,因为我们需要添加一层后处理来过滤掉不需要的字符。
以下是一些噪声图像的示例:

我们做的第一件事就是运行现成的OCR,既可以从开源库中运行,也可以从基于云的API中运行。
VIN是写在汽车上的,而不是写在纸上的,而且它不是字符识别技术的常见用例。我们必须找到另一种使用Python和docTR的方法。
为什么要使用docTR?
DocTR是一个面向数据科学家和开发人员的Python光学字符识别库。端到端OCR使用两个阶段的方法实现:文本检测和文本识别。
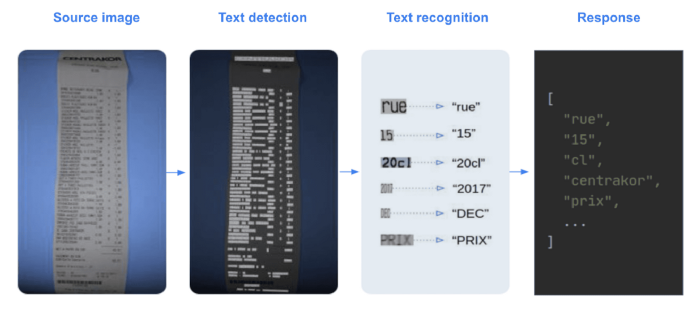
DocTR包括用于检测和识别任务的预训练模型。任何人都可以使用它从图像或pdf中提取单词。你可以非常轻松地测试它(更多信息请参阅docTR文档)
1.安装
pip install python-doctr
2.Python hello world
from doctr.io import DocumentFile
from doctr.models import ocr_predictor
model = ocr_predictor(pretrained=True)
doc = DocumentFile.from_pdf("path/to/your/doc.pdf").as_images()
# Analyze
result = model(doc)
但正如我们之前提到的,没有OCR能很好地解决我们的VIN问题。通用OCR不是这个用例的好解决方案,因为:
· OCR应该是通用的,而文本检测和文本识别的问题在涉及“野外”数据(如VIN的照片)时非常困难。
· 通用OCR的输出列出了写入图像中的字符,即使所有字符都被准确检测到,如何从中重建VIN字符串?
为了摆脱这些限制,我们决定对VIN数据上的docTR模型进行微调,以实现检测和识别任务,从而获得更好的性能。
这样,检测将只提取VIN字符(而不是周围的字符),我们将有一个用于读取它们的微调模型。该库包括基于预训练模型的检测和识别能力。
由于这些预训练的模型,我们可以很容易地对VIN数据进行微调:我们应该获得较高的精度,因为它们预训练了数以百万计的各种数据。
我们的贡献者经常向库添加最先进的模型。以下是截至今天的可用模型列表:
文本检测
· Real-time Scene Text Detection with Differentiable
Binarization(https://arxiv.org/pdf/1911.08947.pdf).
· LinkNet: Exploiting Encoder Representations for Efficient Semantic
Segmentation(https://arxiv.org/pdf/1707.03718.pdf)
文本识别
· An End-to-End Trainable Neural Network for Image-based Sequence
Recognition and Its Application to Scene Text
Recognition(https://arxiv.org/pdf/1507.05717.pdf).
· Show, Attend and Read: A Simple and Strong Baseline for Irregular Text
Recognition(https://arxiv.org/pdf/1811.00751.pdf).
· MASTER: Multi-Aspect Non-local Network for Scene Text
Recognition(https://arxiv.org/pdf/1910.02562.pdf).
我们的数据集
我们有5000张使用不同设备拍摄的VIN照片,所有这些照片都来自不同的车辆。这是一个好的开始!
Nicolas告诉我们,他们的移动应用程序中有一个用于拍照的布局模板,强制用户以正确的方向拍照。这使问题变得更容易,因为我们可以假设输入图像的方向正确。它也有助于我们确保VIN不太倾斜:我们可以考虑最大绝对斜席角约5°。

我们的数据集包含方向错误的照片和角度超过5°的倾斜VIN。我们从数据集中删除了5°以上的倾斜照片,并改变了方向以使每张照片都笔直。
我们将75%的数据用于训练,15%用于验证,10%用于测试。
注释文本检测数据集
DocTR文本检测模型输出图像的分割热图。

为了训练这个模型,我们需要为每个图像提供对应于我们正在寻找的文本位置的多边形集。
在我们的例子中,每个图像的标签都是一个多边形,表示VIN在图像中的位置。训练和验证集的文件夹结构必须如下所示:
├── images
│ ├── sample_img_01.png
│ ├── sample_img_02.png
│ ├── sample_img_03.png
│ └── ...
└── labels.json
labels.json文件将输入文件名映射到其多边形标签:
{
"sample_img_01.png" = {
'img_dimensions': (900, 600),
'img_hash': "theimagedumpmyhash",
'polygons': [[[x1, y1], [x2, y2], [x3, y3], [x4, y4]],...]
},
"sample_img_02.png" = {
'img_dimensions': (900, 600),
'img_hash': "thisisahash",
'polygons': [[[x1, y1], [x2, y2], [x3, y3], [x4, y4]],...]
}
...
}
我们使用了我们的内部工具来注释这些数据,但是你可以找到很多很好的商业软件。
注释文本识别数据集
在docTR端到端管道中,文本识别模型将在第一个文本检测阶段检测到的输入图像作为输入。然后,该算法将对这些作物执行“读取”任务,以获得机器编码的字符串。

对识别数据集进行注释比检测更加繁琐。我们再次使用了我们的内部工具,其中包括一个预注释功能,使用通用文本识别算法使其更容易。更正几个字符确实比从头开始手动键入所有字符更容易。你可以在许多商业注释软件中找到此功能。
对于文本识别任务,docTR要求数据集文件夹的结构与文本检测的结构相同。
├── images
├── img_1.jpg
├── img_2.jpg
├── img_3.jpg
└── ...
├── labels.json
labels.json文件将输入文件名映射到其输出字符串:
{
labels = {
'img_1.jpg': 'I',
'img_2.jpg': 'am',
'img_3.jpg': 'a',
'img_4.jpg': 'Jedi',
'img_5.jpg': '!',
...
}
训练模型
现在让我们跳到有趣的事情!正如你可能想象的那样,实际的过程实际上是在训练实验和数据清理之间来回多次,以提高性能。但是为了这篇文章,让我们考虑数据集第一次被完全注释。
我们将使用TensorFlow 2(TF)后端来训练我们的模型:这也可以使用PyTorch后端来实现,因为步骤非常相似。你可以通过以下方式使用TF或PyTorch后端安装docTR
Tensorflow
pip install python-doctr[tf]
PyTorch
pip install python-doctr[torch]
确保你有4个必需的带注释数据文件夹,例如:
├── detection_train
├── images
├── train_det_img_1.jpg
└── ...
└── labels.json
├── detection_val
├── images
├── val_det_img_1.jpg
└── ...
└── labels.json
├── recognition_train
├── images
├── train_rec_img_1.jpg
└── ...
└── labels.json
├── recognition_val
├── images
├── val_rec_img_1.jpg
└── ...
└── labels.json
文本识别模型训练
让我们从文本识别算法开始。
1.安装docTR
pip install python-doctr[tf]
2.在笔记本电脑上的某个地方克隆存储库
git clone https://github.com/mindee/doctr
3.导航到刚刚克隆的docTR repo,进入recognition references文件夹。references/recognition文件夹包含TensorFlow和PyTorch的训练脚本。
cd /path/to/doctr/references/recognition
4.使用sar_resnet31启动训练(此模型使用Resnet 31)
python train_tensorflow.py model=sar_resnet31 train_path=/path/to/your/train/recognition/dataset val_path=/path/to/your/val/recognition/dataset --vocab legacy_french --pretrained --wb --epochs 50
— pretrained:将从docTR-SAR开始,使用Resnet31预训练模型。
— wb:将开展一项关于权重和偏置的实验。
— tb:如果你想改用TensorBoard 。
根据机器规格,如果内存不足,可能会出现内存不足(OOM)错误。如果出现此错误,请使用-b参数减小批次大小:
python train_tensorflow.py model=sar_resnet31 train_path=/path/to/your/train/recognition/dataset
val_path=/path/to/your/val/recognition/dataset --vocab legacy_french --pretrained --wb --epochs 50 -b 16
-b:批量大小
验证步骤发生在每个epoch之后,如果验证丢失是所有epoch中最低的,则检查点将保存在references文件夹中。
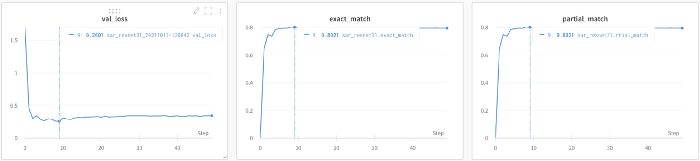
该模型收敛速度非常快,能够在验证集上实现80%的准确率。这看起来可能没有那么多,但这是因为我们将扭曲的数据放入训练集中。我们后面计算端到端的指标,这是最重要的指标,了解整体进展情况。
文本检测模型训练
对于文本检测模型,以下是步骤:
1.导航到/references/detection文件夹
cd /path/to/doctr/references/detection
2.使用db_resnet50启动训练(此模型使用Resnet 50主干)
python train_tensorflow.py model=db_resnet50 train_path=/path/to/your/train/detection/dataset val_path=/path/to/your/val/detection/dataset --pretrained --wb
检测模型比识别模型大:这一模型更可能出现OOM错误。同样,如果出现这种情况,可以考虑减少批量大小。
为这项任务使用预训练的模型是非常重要的。docTR模型的训练是检测图像中的任何单词,我们只寻找VIN。通过仅在VIN上重新训练此模型,我们正在微调模型,以仅检测VIN,并过滤掉任何周围的文本。
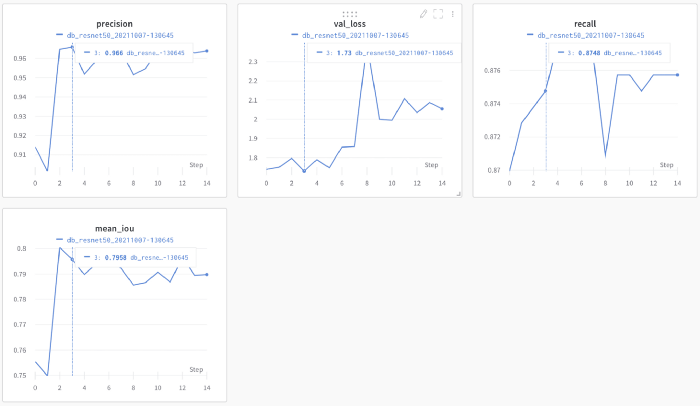
检测指标比识别指标更难分析。虽然精度看起来很高,但由于IoU不容易操作,我们将通过测试端到端管道来了解模型的性能。
测试经过训练的模型
我们的模型保存在克隆的docTR存储库的参考文件夹中。
要查看模型的实际工作情况,代码非常简单:
from doctr.io import DocumentFile
from doctr.models import ocr_predictor
DET_CKPT = "file:///path/to/detection/model/db_resnet50_XXXX/weights"
REC_CKPT = "file://path/to/recognition/model/sar_resnet31_XXXX/weights"
model = ocr_predictor(det_arch='db_resnet50', reco_arch='sar_resnet31',pretrained=True)
model.det_predictor.model.load_weights(DET_CKPT)
model.det_predictor.model.postprocessor.unclip_ratio = 2
model.reco_predictor.model.load_weights(REC_CKPT)
if __name__ == "__main__":
# Image loading
doc = DocumentFile.from_images("./path/to/image")
# Models inference
result = model(doc)
# Max proba post processing rule for selecting the right VIN value among docTR results
vin = ""
for word in result.pages[0].blocks[0].lines[0].words:
if word.confidence > confidence:
vin = word.value
confidence = word.confidence
# Display the detection and recognition results on the image
result.show(doc)
为了找到最佳参数,我们根据验证集微调了Unprex_ratio参数。这是用于从检测模型扩展输出多边形的因子,以便生成可输入文本识别模型的方形框。
由于这两个模型是分别训练的,因此没有理由默认参数是优化文本识别性能的最佳参数。
在我们的测试集中测试了经过训练的模型之后,我们实现了90%的端到端准确率,考虑到数据量少和用例的复杂性,这是非常好的。如果我们愿意,我们本可以花更多时间用一些想法优化模型:
· 检测模型在方形框上训练。DocTR将很快支持旋转框,这将使我们对倾斜的照片有更好的鲁棒性。
· 超参数微调:我们没有在这方面花费太多时间。例如,我们注意到dropout和学习率对训练有很大影响。我们手动测试了一些值,但我们本可以花更多时间对这些参数进行网格搜索。输入大小也很重要,我们使用了默认的docTR参数。
· 文本识别只针对算法的主干部分预训练模型:虽然有预训练的模型很好,但在使用它们时,我们不能自由地使用我们想要的词汇表。我们询问docTR团队,是否有可能只为文本识别算法的主干部分获得预训练模型,这样我们就可以用我们的特定词汇训练分类头。他们很快就会解决这个问题。
· 当然,更多的数据…
结论
本例是,该问题需要对检测层和识别层进行重新训练,以获得更好的性能。
使用通用的OCR并试图提取所需的关键信息可能非常乏味。你需要在原始OCR结果的基础上构建大量的后处理,而且它不太可能在简单的文本检测和识别任务中表现良好。
感谢阅读!
