阿里GATNE:一文了解异构图的表示学习
程序媛驿站
导读
论文:
Representation Learning for Attributed Multiplex Heterogeneous Network
任务:
针对考虑属性的复杂异构图的图表示学习
本文:
提出GATNE模型
机构:
清华大学、阿里达摩院

发表:
KDD 2019
一、动机
「图的embedding表示」在真实世界中已经有了非常大规模的应用,然而现存的一些图嵌入相关的方法主要还是集中在同质网络的应用场景下,即节点和边的类型都是单一类型的情况下。
但是,真实世界网络中每个节点的类型都多种,每条边的类型也有多种,而且每一个节点都具有不同且繁多的属性(异构网络)。
因此,
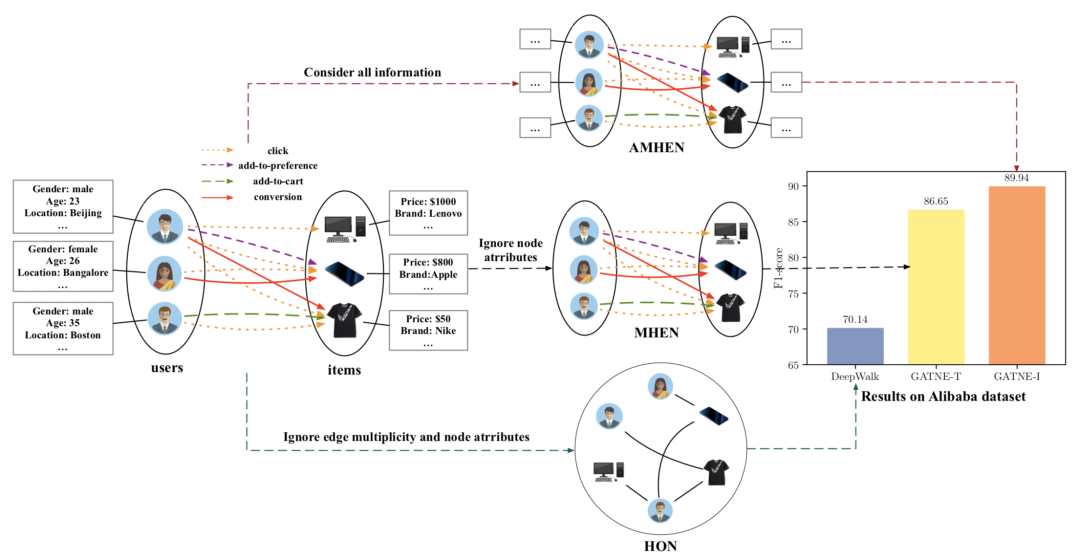
本论文提出了一种在Attributed Multiplex Heterogeneous Network(考虑属性的复杂异构图)中进行embedding学习的统一框架,还在Amazon, YouTube, Twitter, and Alibaba数据集上进行了大量的实验。
实验结果表明利用此框架学习到的embedding有惊人的性能提升F1 scores可提高5.99-28.23%
而且该框架还成功地部署在全球领先的电子商务公司阿里巴巴集团的推荐系统上。
二、什么是考虑属性的复杂异构图 图有哪些分类方式呢?
节点类型(Node Type)表格第三列):单一类型 / 多类型
边类型(Edge Type)第四列):单一类型 / 多类型 & 有向边 / 无向边
特征属性(Attribute)最右侧列):带属性 / 不带属性
根据以上几种分类方式的不同组合,
本表格展现了六种不同类型的网络(第一列),
并分别列出了学术界的发展进度(第二列)。
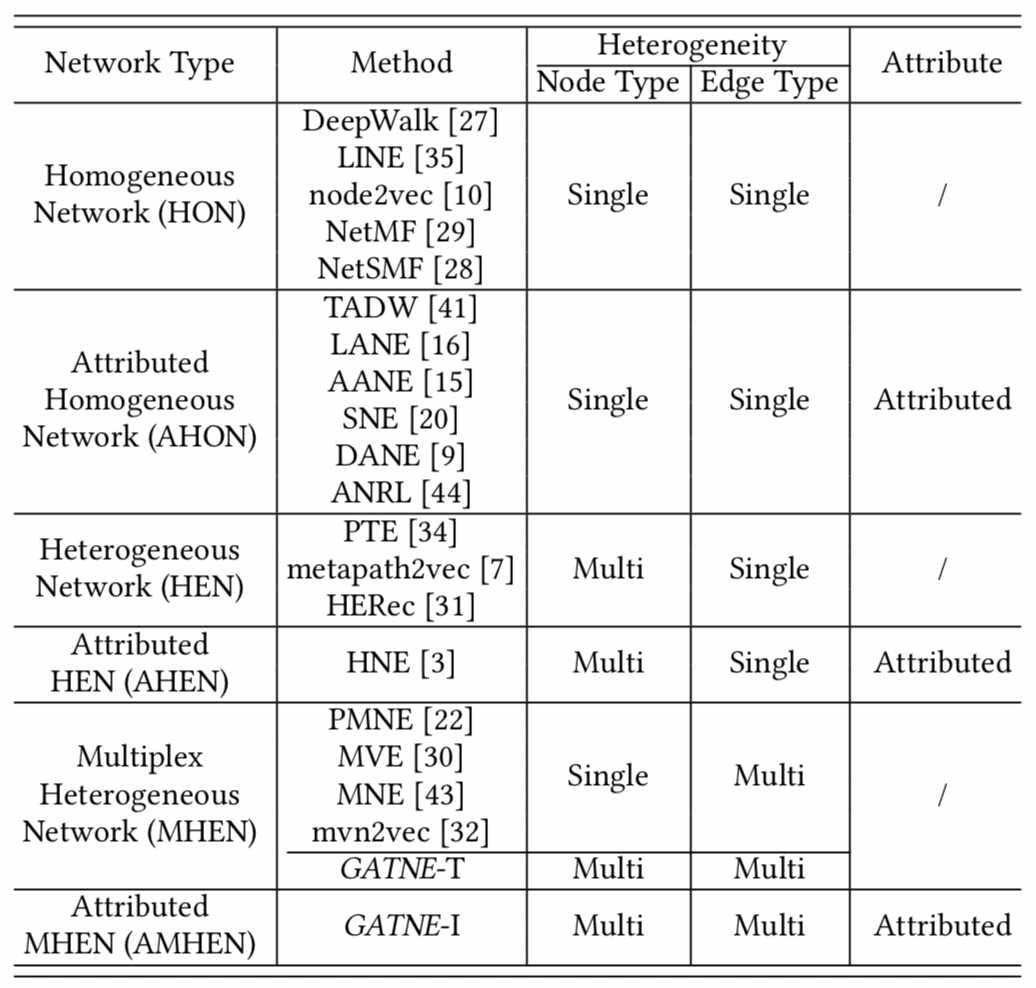
分为:
不带属性的同构网络(HON)(第一行)、带属性的同构网络(AHON)(第二行)、不带属性的异构网络(HEN)、带属性的异构网络(AHEN)、多重异构网络(MHEN)和带属性的异构网络(AMHEN)。
可以看出,
对节点多类型、边多类型且带属性的异质网络 (AMHEN)(最后一行)的研究目前是最少的。
本文则重点关注 Attributed Multiplex Heterogeneous (AMHEN) 网络:
Attributed:考虑节点性质,如用户性别、年龄、购买力等
Multiplex:多重边,节点之间可能有多种关系,比如说两个用户之间可能为好友、同学、交易关系等;用户和item之间可以浏览、点击、添加到购物车、购买等
Heterogeneous:异构,节点和边有多种类型,节点类型+边类型>2
下图为 阿里巴巴公司数据集的网络及效果示意图
三、本文贡献
本论文提出了两个模型
Transductive Model: GATNE-T
Inductive Model: GATNE-I
那么二者的区别又是什么呢?
想要知道二者的区别,首先要明白Transductive Model和Inductive Model的区别
那么Transductive Model和Inductive Model的区别是什么呢?
Transductive learning:直推式学习,后面我们简称T
Inductive Leaning:归纳式学习,简称I
区别:
模型训练:T在训练过程中已经用到测试集数据(不带标签)中的信息,而I仅仅只用到训练集中数据的信息,也就是说训练时的T是见到过测试数据的;
模型预测:T只能预测在其训练过程中所用到的样本,而I只要样本特征属于同样的欧拉空间,即可进行预测;
当有新样本时,T需要重新进行训练;I则不需要;
三、GATNE-T
GATNE模型
全称:General Attributed Multiplex Heterogeneous Network Embedding
本文提出的GATNE模型,希望每个节点在不同类型边中有不同的表示。
比如说,
用户A在点击查看商品的场景下学习一种向量表示,在购买商品的场景下学习另一种向量表示,而不同场景之间并不完全独立。
具体的说,
本文将每个边类型r上特定节点vi的整体embedding(Vi,r)分为两部分:
base embedding(bi)和edge embedding(Uir),由二者组合而成。
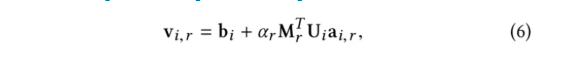
公式中的ai,r为self-attention,计算当前节点下的不同类型的边的权重:
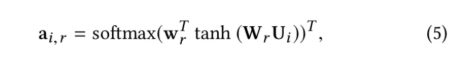
其中,Uir表示i节点r边的特征,Ui表示i节点concat聚合了所有边类型的特征,m为聚合后的边embedding的维度。
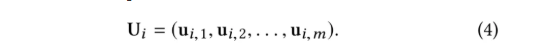
以上公式中,W、w 均为可训练的参数矩阵。
如下图所示,
base embedding不区分边的类型,在不同类型的边之间共享
edge embedding会区分不同类型的边,利用类似于Graphsage对邻居聚合的思想,节点i边类型r下的特征表示Ui,r由周围的K层邻居聚合得到
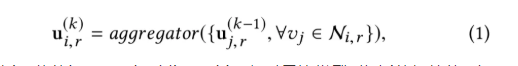
对于节点i,他的base embedding(bi)与对于边类型r节点i的初始的edge embedding(Uir)均为:根据网络结构,针对每一个节点,通过训练获得。
模型结构如下图所示:
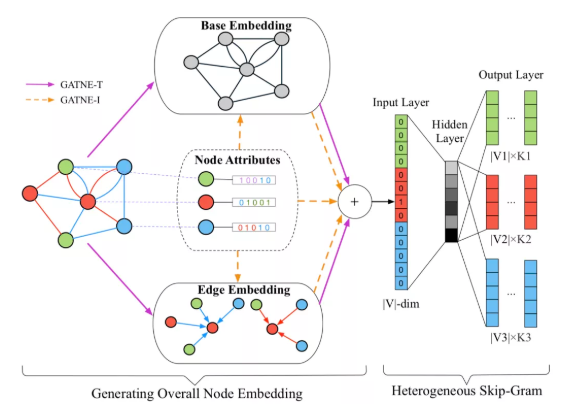
图上我们也可以看出,GATNE-T仅仅利用了网络结构信息,而GATNE-I同时考虑了网络结构信息和节点属性。
但现实中的真实情况是:整张图的网络我们往往只能观察到部分而非全部。
因此,为了解决部分观察的问题,本论文在GATNE-T的模型上做了一个延伸,生成了一个新模型,叫作:GATNE-I
四、GATNE-I
本文基于GATNE-T模型的局限性:
不能处理观察不到的数据然而在现实生活大量的应用中,被网络化的数据常常只有部分能被观测到
于是提出了模型GATNE-I
此模型能够更好地处理那些不能被观测到的数据部分,即,从考虑节点初始的特征入手。
GATNE-I
它不再为每一个节点直接训练特征,而是通过训练两个函数,将节点属性分别通过两个函数生成。
这样有助于在训练过程中哪怕看不到这个节点,但是只要这个节点有原属性就可以通过函数生成相应特征。
对比GATNE-T模型,GATNE-I模型主要从以下三个角度进行调整:
base embedding:GATNE-T中base embedding由训练得到,而GATNE-I考虑利用节点属性(Xi)生成base embedding,其中加入了函数h,完成节点属性Xi到base embedding=h(Xi)的转化。
初始edge embedding:GATNE-T中edge embedding值由随机初始化得到,而GATNE-I中的初始edge embedding同样利用节点属性生成,其中使用了节点类型&边类型的转化函数。
最终的 节点在边类型为r下的 embedding 由 base embedding + edge embedding + 类型为z的节点的 转化特征 DzXi 得到。
其中,Dz是vi对应节点类型z上的特征变换矩阵。
五、训练算法
本文利用基于元路径meta-path-based的随机游走方法和skip-gram来学习模型参数。

具体过程包括:
在图上,对于每一种类型的边,通过随机游走生成节点序列,其中包含点Vi、Vj与边r;
由于是异构的,我们使用基于元路径的随机游走,然后设置路径中各节点的转移概率,0或1;
基于元路径的随机游走策略确保了不同类型节点之间的语义关系能够正确地融入到skip-gram模型中。
通过公式(6)或(13)计算得到点Vir、Vjr的表示;
然后对节点序列执行skip gram以学习embedding表示;
对于节点vi与其路径中的“上下文”C,我们的目标为最小化负对数似然:
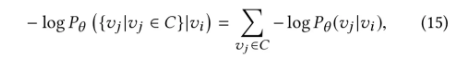
对每一对节点构建目标函数:
其中,L是与正训练样本相对应的负样本数。
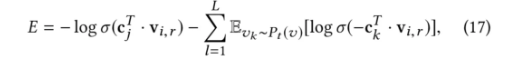
通过构建的目标函数不断更新模型参数
六、数据集与实验效果
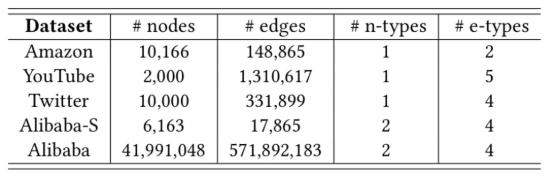
数据集规模:
实验效果:
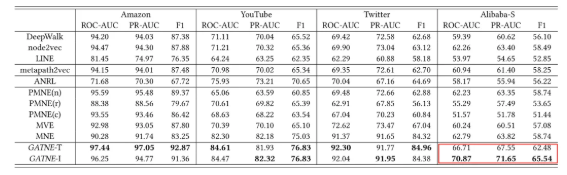
红色框框??出了本文模型在阿里数据集上的效果,可以看出,利用此框架学习到的embedding有着惊人的性能提升。
